视觉语言模型指令微调方法及装置
本发明涉及计算机,尤其涉及一种视觉语言模型指令微调方法及装置。
背景技术:
1、近年来,视觉语言模型(vision language model,vlm)在视觉问答任务的准确率方面得到了大幅提升,大型语言模型(large language model,llm)在推理任务中也取得了令人惊喜的成功,例如思维链和语境学习等。理论上,vlm也应该具有与llm同样强大的推理能力。视觉语言模型先在大规模的数据集上进行预训练,再针对不同的下游任务进行微调的方法,被称为“预训练-微调”方式。
2、现有的针对视觉语言模型的调优方法主要集中通过现有的数据集通过改进网络结构和添加指令等方式,这样的方法不仅复杂而且微调后的视觉语言模型的精度低。
技术实现思路
1、本发明提供一种视觉语言模型指令微调方法及装置,用以解决微调后的视觉语言模型的精度低的问题。
2、本发明提供一种视觉语言模型指令微调方法,包括:
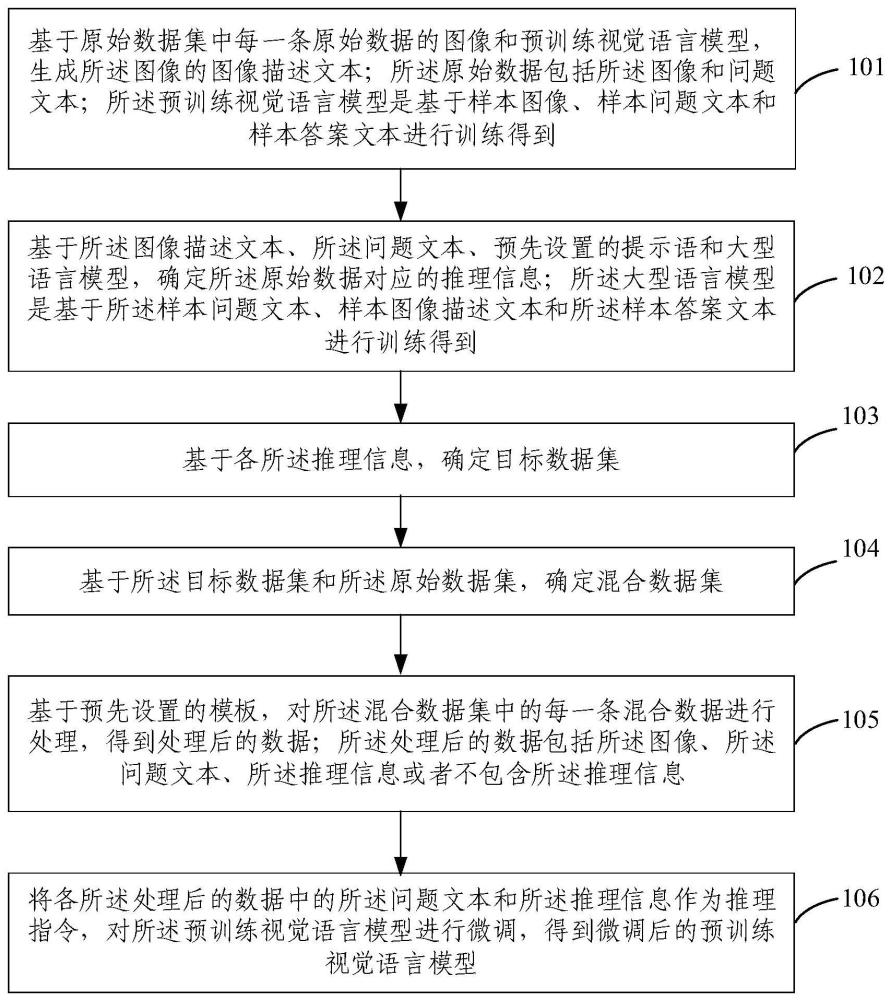
3、基于原始数据集中每一条原始数据的图像和预训练视觉语言模型,生成所述图像的图像描述文本;所述原始数据包括所述图像和问题文本;所述预训练视觉语言模型是基于样本图像、所述样本问题文本和所述样本答案文本进行训练得到;
4、基于所述图像描述文本、所述问题文本、预先设置的提示语和大型语言模型,确定所述原始数据对应的推理信息;所述大型语言模型是基于所述样本问题文本、样本图像描述文本和所述样本答案文本进行训练得到;
5、基于各所述推理信息,确定目标数据集;
6、基于所述目标数据集和所述原始数据集,确定混合数据集;
7、基于预先设置的模板,对所述混合数据集中的每一条混合数据进行处理,得到处理后的数据;所述处理后的数据包括所述图像、所述问题文本、所述推理信息或者不包含所述推理信息;
8、将各所述处理后的数据中的所述问题文本和所述推理信息作为推理指令,对所述预训练视觉语言模型进行微调,得到微调后的预训练视觉语言模型。
9、根据本发明提供的一种视觉语言模型指令微调方法,所述基于各所述推理信息,确定目标数据集,包括:
10、将所述推理信息添加至所述原始数据,得到第一数据;所述第一数据包括所述图像、所述问题文本和所述推理信息;
11、基于各所述第一数据,确定所述目标数据集。
12、根据本发明提供的一种视觉语言模型指令微调方法,在所述基于各所述第一数据,确定所述目标数据集之前,所述方法还包括:
13、基于所述推理信息、所述图像和视觉语言模型,对所述推理信息进行验证,得到验证结果;所述验证结果用于指示所述推理信息是否符合所述图像;所述视觉语言模型是基于样本图像和样本文本进行训练得到;
14、在所述推理信息符合所述图像的情况下,将所述推理信息保留;
15、在所述推理信息不符合所述图像的情况下,将所述图像描述文本作为所述推理信息。
16、根据本发明提供的一种视觉语言模型指令微调方法,所述预训练视觉语言模型包括图像编码器、轻量级查询转换器、全连接层和预训练语言模型;
17、所述将各所述处理后的数据中的所述问题文本和所述推理信息作为指令,对所述预训练视觉语言模型进行微调,得到微调后的预训练视觉语言模型,包括:
18、步骤a:针对每一条处理后的数据,将所述处理后的数据中的图像输入至所述图像编码器,得到所述图像编码器输出的所述图像对应的第一图像特征向量;
19、步骤b:将可学习查询模块的学习查询向量、所述第一图像特征向量和所述推理指令输入至所述轻量级查询转换器,得到所述轻量级查询转换器输出的第二图像特征向量;所述学习查询向量是基于上一次微调过程中所述轻量级查询转换器得到的所述第二图像特征向量得到的;
20、步骤c:将所述第二图像特征向量输入至所述全连接层,得到所述全连接层输出的第三图像特征向量;
21、步骤d:将所述第三图像特征向量和所述推理指令输入至所述预训练语言模型,得到所述预训练语言模型输出的推理答案;
22、步骤e:基于所述推理答案和所述原始数据中的标准答案,计算损失值;
23、步骤f:基于所述损失值,确定所述微调后的预训练视觉语言模型。
24、根据本发明提供的一种视觉语言模型指令微调方法,所述基于所述损失值,确定所述微调后的预训练视觉语言模型,包括:
25、将所述损失值进行回传,微调所述轻量级查询转换器的参数,得到微调后的参数;
26、基于所述微调后的参数,重复执行上述步骤a-步骤e的步骤,直至最终计算的损失值趋于稳定停止微调;
27、基于最后一次微调得到的所述轻量级查询转换器的参数,得到最终微调后的预训练视觉语言模型。
28、根据本发明提供的一种视觉语言模型指令微调方法,在微调的过程中,所述图像编码器和所述预训练语言模型的参数冻结。
29、本发明还提供一种视觉语言模型指令微调装置,包括:
30、第一确定模块,用于基于原始数据集中每一条原始数据的图像和预训练视觉语言模型,生成所述图像的图像描述文本;所述原始数据包括所述图像和问题文本;所述预训练视觉语言模型是基于样本图像、所述样本问题文本和所述样本答案文本进行训练得到;
31、第二确定模块,用于基于所述图像描述文本、所述问题文本、预先设置的提示语和大型语言模型,确定所述原始数据对应的推理信息;所述大型语言模型是基于样本问题文本、样本图像描述文本和样本答案文本进行训练得到;
32、第三确定模块,用于基于各所述推理信息,确定目标数据集;
33、第四确定模块,用于基于所述目标数据集和所述原始数据集,确定混合数据集;
34、处理模块,用于基于预先设置的模板,对所述混合数据集中的每一条混合数据进行处理,得到处理后的数据;所述处理后的数据包括所述图像、所述问题文本、所述推理信息或者不包含所述推理信息;
35、微调模块,用于将各所述处理后的数据中的所述问题文本和所述推理信息作为推理指令,对所述预训练视觉语言模型进行微调,得到微调后的预训练视觉语言模型。
36、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述视觉语言模型指令微调方法。
37、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述视觉语言模型指令微调方法。
38、本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述任一种所述视觉语言模型指令微调方法。
39、本发明提供的视觉语言模型指令微调方法及装置,通过基于原始数据集中每一条原始数据的图像和预训练视觉语言模型,生成图像的图像描述文本;原始数据包括图像和问题文本;预训练视觉语言模型是基于样本图像、样本问题文本和样本答案文本进行训练得到;再基于图像描述文本、问题文本、预先设置的提示语和大型语言模型,确定原始数据对应的推理信息;大型语言模型是基于样本问题文本、样本图像描述文本和样本答案文本进行训练得到;基于各推理信息,确定目标数据集;基于目标数据集和原始数据集,确定混合数据集;基于预先设置的模板,对混合数据集中的每一条混合数据进行处理,得到处理后的数据;预处理的数据包括图像、问题文本、推理信息或者不包含推理信息;将各处理后的数据中的所述问题文本和所述推理信息作为推理指令,对预训练视觉语言模型进行微调,得到微调后的预训练视觉语言模型。通过利用大型语言模型生成原始数据对应的推理信息,再根据推理信息构建目标数据集,最终得到混合数据集,并利用该混合数据集对预训练视觉语言模型进行混合指令调优,提升了微调后的预训练视觉语言模型的精度。
- 还没有人留言评论。精彩留言会获得点赞!