基于CT重建图像的目标识别模型的训练方法与流程
本发明涉及ct重建图像识别,尤其涉及一种基于ct重建图像的目标识别模型的训练方法。
背景技术:
1、ct安检设备在安防安保系统中的作用至关重要,尤其是在机场、火车站、地铁站等人流密集的交通节点中,安检设备是确保旅客人身财产安全乃至国家、社会稳定的重要安全保障工具,ct安检设备经常用于例如违禁品等的目标物的识别中。
2、目前现有技术中通常将三维ct重建图像进行降维生成多个二维视图,再针对多个二维视图进行目标物的识别。然而,现有技术没有充分利用物体本身的三维信息,虽然能够在爆炸物、毒品等物质属性上具有较强可分性的违禁品识别上具有良好的性能,但对于具有较强的三维形状特征且物质组成和物理属性比较复杂的目标物的识别,表现出明显的局限性。比如:普通棍棒在多个视角下形状差异不大、物质属性简单、特征明显,十分利于分类;而刀只在正反视角面积较大、物质属性较为复杂(刀身、刀把材质往往不同)、在其他视角只有薄薄一层甚至只有几个像素点的厚度,这十分不利于目标检测中的分类。
3、同时,现有技术中在目标识别模型进行训练时,难以获取足够数量的独立目标,使得目标识别模型的识别精度有限,越来越不能高精度识别的需要。
4、因此,亟需一种新的基于ct重建图像的目标识别模型的训练方法的技术方案。
技术实现思路
1、鉴于上述的分析,本发明实施例旨在提供一种基于ct重建图像的目标识别模型的训练方法,用以解决现有技术中由于缺乏有效的训练样本导致目标识别模型识别不准确的问题。
2、本发明实施例提供了一种基于ct重建图像的目标识别模型的训练方法,所述训练方法包括:
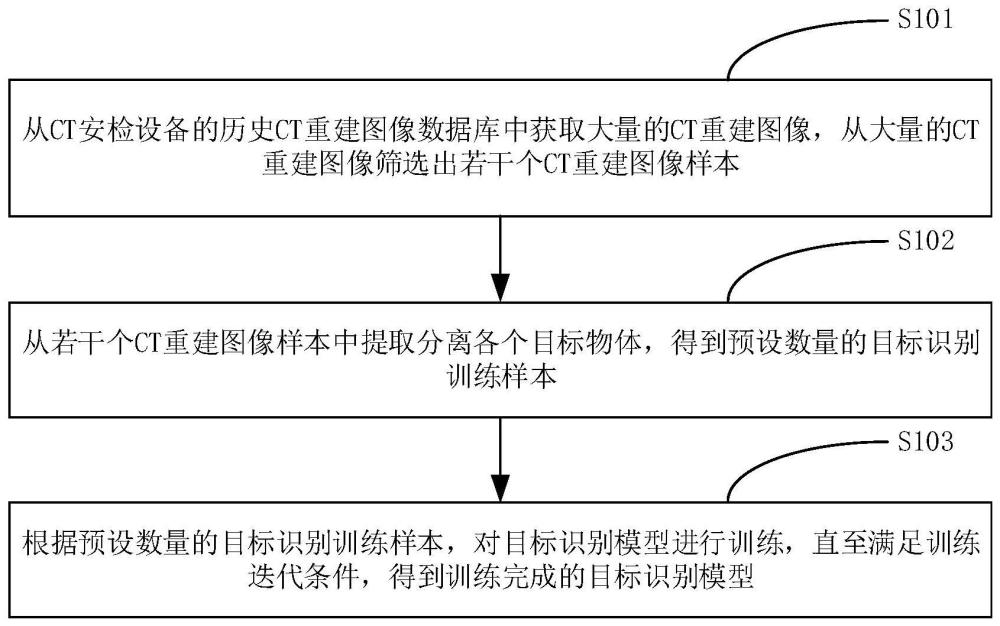
3、从ct安检设备的历史ct重建图像数据库中获取大量的ct重建图像,从大量的ct重建图像筛选出若干个ct重建图像样本;
4、从若干个ct重建图像样本中提取分离各个目标物体,得到预设数量的目标识别训练样本;
5、根据预设数量的目标识别训练样本,对目标识别模型进行训练,直至满足训练迭代条件,得到训练完成的目标识别模型。
6、基于上述训练方法的进一步改进,所述从大量的ct重建图像筛选出若干个ct重建图像样本,包括:
7、判断ct重建图像中所包括的目标物体的数量,如果所包括的目标物体的数量在预设数量范围内,则将该ct重建图像作为一个ct重建图像样本;
8、预设数量范围为4-6个。
9、基于上述训练方法的进一步改进,所述从若干个ct重建图像样本中提取分离各个目标物体,得到预设数量的目标识别训练样本,包括:
10、步骤s201:从每个ct重建图像样本中获取多个目标物体的三维体素;
11、步骤s202:对每个目标物体的三维体素进行第二预设视角下的渲染,得到该目标物体的多个渲染图像;将该目标物体的多个渲染图像作为一个目标识别训练样本,并且设置该目标识别训练样本的类别标签;
12、步骤s203:重复步骤s202,直至得到该ct重建图像样本中所有目标物体对应的目标识别训练样本;
13、步骤s204:判断是否得到预设数量的目标识别训练样本;如果为是,终止步骤s204,否则重复执行步骤s201、步骤s202和步骤s203。
14、基于上述训练方法的进一步改进,所述从每个ct重建图像样本中获取多个目标物体的三维体素,包括:
15、对ct重建图像样本进行第一预设视角的投影,得到第一预设视角对应的多个二维投影图像;将多个二维投影图像依次输入至预先训练完成的包围框确定模型,得到每个二维投影图像对应的二维包围框;
16、将每个二维投影图像对应的二维包围框按照第一预设视角反映射回ct重建图像样本中,得到ct重建图像样本中所包括的目标物体,每个目标物体对应唯一的三维包围框;
17、基于每个目标物体的三维包围框,从ct重建图像样本中依次提取每个目标物体的三维体素。
18、基于上述训练方法的进一步改进,所述基于每个目标物体的三维包围框,从ct重建图像样本中依次提取每个目标物体的三维体素,包括:
19、基于每个目标物体的三维包围框,确定该目标物体对应的矩阵掩模数组;
20、将该目标物体对应的矩阵掩模数组与ct重建图像样本对应的三维体素相乘,得到该目标物体的三维体素。
21、基于上述训练方法的进一步改进,所述包围框确定模型包括特征提取骨干层、双层特征结合层和二维框输出层;
22、特征提取骨干层,用于接收二维投影图像,提取二维投影图像的特征图,输出两个深度不同的特征图至双层特征结合层;
23、双层特征结合层,用于组合两个深度不同的特征图,融合得到三种不同的特征图,并且将三种特征图输入至二维框输出层;
24、二维框输出层,用于分别根据各自的特征图进行预测,得到每个特征图中各个目标的二维包围框;计算三个特征图中各个目标的二维包围框的平均值,作为每个二维投影图像对应的二维包围框。
25、基于上述训练方法的进一步改进,所述特征提取骨干层包括卷积输入层、第一特征图提取层和第二特征图提取层;
26、卷积输入层,用于接收二维投影图像,并进行一次卷积操作,将卷积操作后的特征图输入至第一特征图提取层;
27、第一特征图提取层,用于对输入的特征图进行卷积操作和残差卷积操作,得到第一特征图,并输出至第二特征图提取层和双层特征结合层;
28、第二特征图提取层,用于对输入的第一特征图进行卷积操作和残差卷积操作,得到第二特征图,并输出至双层特征结合层。
29、基于上述训练方法的进一步改进,所述包围框确定模型的损失函数为:
30、
31、
32、
33、其中,表示二维包围框的损失函数,xt,xb,xl,xr分别表示预测包围框的二维坐标,分别表示实际包围框的二维坐标,i是交集面积,u是并集面积。
34、基于上述训练方法的进一步改进,所述目标识别模型包括特征提取网络、特征融合网络和分类头网络;
35、特征提取网络,用于接收目标识别训练样本的多个渲染图像,并分别提取每个渲染对象对应的特征图,并将每个渲染对象对应的特征图发送至特征融合网络;
36、特征融合网络,用于将多个渲染图像对应的多个特征图连接合并,得到每个目标物体对应的特征矩阵,并将每个目标物体对应的特征矩阵发送至分类头网络;
37、分类头网络,用于根据每个目标物体对应的特征矩阵,预测出每个目标物体对应的类别。
38、基于上述训练方法的进一步改进,所述特征提取网络包括多个特征提取层,特征提取层的数量和第二预设视角的数量相同,每个特征提取层用于提取每个第二预设视角对应的渲染图像的特征图;
39、每个特征提取层包括依次连接的输入层、多个卷积池化层和输出层,每个卷积池化层包括依次连接的2个卷积层和1个池化层。
40、与现有技术相比,本发明至少可实现如下有益效果之一:
41、1、通过历史ct重建图像数据库中获取大量的ct重建图像,从大量的ct重建图像筛选出若干个ct重建图像样本从若干个ct重建图像样本中提取分离各个目标物体,得到预设数量的目标识别训练样本,提高了训练完成的目标识别模型的识别精度;
42、2、通过从每个ct重建图像样本中获取多个目标物体的三维体素,对每个目标物体的三维体素进行第二预设视角下的渲染,得到该目标物体的多个渲染图像,快速得到目标识别训练样本;
43、3、通过第一预设视角对应的多个二维投影图像,利用包围框确定模型得到每个二维投影图像对应的二维包围框,将每个二维投影图像对应的二维包围框按照第一预设视角反映射回ct重建图像样本中,得到ct重建图像样本中所包括的目标物体,从ct重建图像样本中依次提取每个目标物体的三维体素,提高了每个目标物体的准确性。
44、本发明中,上述各技术方案之间还可以相互组合,以实现更多的优选组合方案。本发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书以及附图中所特别指出的内容中来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!