一种自动驾驶场景下面向车辆道路行驶的视觉检测方法与流程
本发明属于自动驾驶,具体涉及一种自动驾驶场景下面向车辆道路行驶的视觉检测方法。
背景技术:
1、随着智能驾驶技术的不断发展,自动驾驶车辆在道路行驶的安全性受到更多的关注,大量的相关技术得到很好发展。比方车道保持系统可以很好地控制车辆,提高道路交通的安全性。其原理是通过车载前置相机获得道路车道线信息,然后由车辆控制模块保证车辆在车道线中间行驶,避免车辆偏离车道导致的交通事故。该项技术的优劣取决车道线检测的质量,一项稳定的检测算法是车道保持系统的保证。另外车辆在行驶过程中会遇到障碍物的干扰,比方其它车辆或者行人,都会影响自动驾驶的安全性。针对自动驾驶车辆周围目标的检测和追踪就显得尤为重要,一般通过激光雷达数据的处理方式完成检测任务,但激光雷达成本过高,影响着技术的发展,一种依靠相机数据的纯视觉方案可以为这一领域带来更好的发展。检测和追踪出障碍物目标的运动行为,有助系统对目标做出预判,提高自动驾驶车辆的性能和安全性。
2、现今,凭借着人工智能领域和深度学习技术的发展,涌现出大量优秀的视觉方案参与到车道线检测和目标检测中。传统的车道线检测算法面对遮挡和极端照明条件下会影响检测性能,深度学习的方法会基于上下文和全局信息检测出车道线位置,具有更好的鲁棒性。大量相关数据集culane、tusimple、curvelanes和算法ufld、laneatt、clrnet都促进了车道线检测算法的发展,能够更好地面向现实场景车道线检测。目标检测算法是计算机视觉领域最基础的任务之一,但面向智能驾驶领域则需要精确地检测。2d检测框已然不能满足要求,大量3d目标检测方案涌现出来,像monoflex、smoke、pgd,使得纯视觉方案的3d检测技术变得可行,大大降低智能驾驶成本。
3、但是现有技术中,由于计算量较大,需要大量计算资源和较多的计算时间,导致检测的实时性较差,并且受到计算资源限制,也影响了目标实时跟踪功能。在计算资源受限的情况下,现有技术的检测结果在准确性上有所不足,对障碍物和车道线的检测有一定误差,特别是容易存在远距离车道线检测偏离问题。
技术实现思路
1、本发明目的是提供一种自动驾驶场景下面向车辆道路行驶的视觉检测方法,以解决现有技术中对不规则物体的形状和噪声数据应对能力较差,从而导致现有技术会鲁棒性不足,出现较多的特征点匹配错误,并进一步造成位姿估计偏差的技术问题
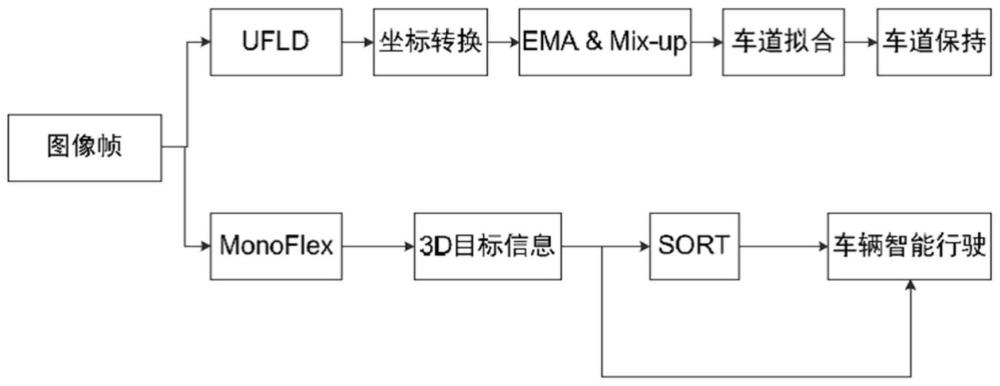
2、所述的一种自动驾驶场景下面向车辆道路行驶的视觉检测方法,包括下列步骤。
3、步骤一:通过车载前方单目相机获得图像之后,输入到ufld深度神经网络中获得车道线像素坐标,转换像素坐标为相机坐标系下的车道线坐标。
4、步骤二:对车道线相机坐标系下坐标采用ema优化方法和mix-up优化方法优化坐标质量,进而拟合车道线二次曲线方程,并将拟合结果输入到运动控制模块,实现车道保持功能。
5、步骤三:在将图像数据输入到ufld深度神经网络的同时,将图像数据传入到monoflex深度神经网络,得到图像数据中障碍物的3d检测框信息。
6、步骤四:获得3d检测框信息后,采用sort目标追踪算法,追踪障碍物车辆并预判其运动行为,完成车辆安全行驶。
7、所述sort目标追踪算法将障碍物的3d检测框和经过卡尔曼滤波器处理得到的追踪框进行特征匹配,目标匹配采用匈牙利算法。
8、优选的,所述步骤一中,基于ufld深度神经网络建立的ufld车道线检测算法以mobilenetv2卷积神经网络为骨架网络,ufld车道线检测算法将车道线检测定义成分类任务,通过车载前方单目相机获得单目图像之后,将图像输入到ufld深度神经网络中获得车道线像素点坐标,并通过相机内参矩阵和相机高度得出车道线在相机坐标系下坐标。
9、优选的,所述步骤一中,相机内参矩阵k为:
10、
11、其中,焦距为(fx,fy),光学中心为(cx,cy);车道线像素点(u,v)在相机坐标系y轴坐标为yc,表示相机安装高度;车道线像素点(u,v)在相机坐标系z轴坐标为:
12、
13、其中,车道线像素点坐标为(u,v),车道线像素点(u,v)在相机坐标系下x轴、y轴和z轴坐标为:
14、
15、通过以上公式能得出车道线各个像素点在相机坐标系下的坐标(xc,yc,zc)。
16、优选的,所述步骤二的ema优化方法中,此时刻车道线点的计算式如下:
17、ct=β×ct-1+(1-β)c′t
18、其中,上一时刻车道线点为ct-1,此时刻车道线检测点为c′t,β为常量值。
19、优选的,所述步骤二的mix-up优化方法中,一条车道线相邻点之间的坐标为(x1,y1,z1)和(x2,y2,z2),经过线性插值得到新的坐标具体计算式如下:
20、
21、
22、
23、其中λ取值beta分布;然后让优化后的所有车道线坐标参与二次曲线的拟合。
24、优选的,所述步骤四中,基于上一步提取出的3d检测框,通过匈牙利算法判断前后两帧的相似度,采用卡尔曼滤波算法预测和更新追踪目标框,将障碍物的3d检测框和经过卡尔曼滤波器处理得到的追踪框进行特征匹配,进而划分出未被匹配的追踪框、未被匹配的检测框和已匹配的追踪框;未被匹配的追踪框选择删去的处理方法,未被匹配的检测框设置成新的追踪框,已匹配的追踪框则基于卡尔曼滤波器的更新得到新的追踪框;基于两个新的追踪框构成这一帧画面追踪目标。
25、优选的,所述步骤四中,匈牙利算法利用检测框和当前帧经过卡尔曼滤波器预测的追踪框之间的特征值来构造代价函数,进行数据关联,目标是使得匹配后代价矩阵最小;匈牙利算法的详细步骤如下:
26、1)代价矩阵每一行元素减去当前行中元素最小值,得到新矩阵;
27、2)对步骤1)所得新矩阵的每一列元素减去其当前列中元素最小值,得到新矩阵;
28、3)用最少的水平线或垂直线覆盖步骤2)所得的新矩阵中所有0,若线数量为代价矩阵行或列数,则说明找到最优分配,匹配结束,否则进入到下一步;
29、4)在所有没被线覆盖的元素中取最小元素;若当前行没被线覆盖则用当前行减去此元素,若当前列被线覆盖则用此列加上此元素,返回步骤3)。
30、优选的,卡尔曼滤波算法用来对追踪框进行预测和更新,3d检测框信息也参与到目标追踪,以预判其行为特征;卡尔曼滤波算法的相关公式为:
31、
32、
33、
34、
35、其中,和代表t-1时刻后验状态估计和t时刻后验状态估计,代表t时刻先验状态估计,pt-1和pt代表t-1时刻后验估计协方差和t时刻后验估计协方差,代表t时刻先验估计协方差,h代表状态到观测的转换矩阵,zt代表观测值,kt代表卡尔曼增益,f代表状态转移矩阵,q代表过程协方差,r代表噪声协方差,b是输入转换成状态的矩阵。
36、本发明具有以下优点:本发明通过采用基于深度学习的检测方法实现自动驾驶车辆对道路环境的感知。仅通过单目相机完成了车道线检测和障碍物检测及跟踪,从而实现车辆在道路上自动驾驶;采用ufld车道线检测算法、坐标系转换、ema优化方法、mix-up优化方法、二次曲线拟合等策略实现车道线精确检测;结合monoflex目标检测算法和sort目标追踪算法实现车辆道路障碍物感知,相比其它传感器的方案,大大节省了成本。这两种方案检测出的结果输入到车辆控制和规划模块,可以实现自动驾驶领域的车道保持和车辆避障安全行驶功能。
37、ufld检测算法得出的远侧像素点不够准确,容易飘飞,但近处的像素点足够精确,直道型车道线中远处检测点应该更多关注近处点坐标信息,尤其是横坐标的情况。本方法因此采用ema优化方法进行优化,之后采用mix-up优化方法提高样本数量,得到较好的车道线检测方程。
38、本方法将ufld车道线检测算法中骨架网络resnet更换成mobilenetv2,mobilenetv2这是一种参数量小,计算量少和性能优的轻量型卷积神经网络,其更适合移动端的部署。本方法采用monoflex目标检测算法检测出目标的3d检测框信息,该算法是一种端到端的3d目标检测方法,优化截断物体的检测和中心点的深度估计,并在检测速度有了明显提升。
- 还没有人留言评论。精彩留言会获得点赞!