数据入湖文件的生成方法及其装置、电子设备及存储介质与流程
本发明涉及大数据领域、金融科技领域或其他相关,具体而言,涉及一种数据入湖文件的生成方法及其装置、电子设备及存储介质。
背景技术:
1、随着互联网技术的快速发展以及信息化程度的不断提高,通过信息化技术解决日常生活问题的场景越来越多,每个场景下产生的数据也越来越多,如何利用这些数据规划产品的方向、贴合用户的需求或者指引企业的重要决策便成为了每个企业数字化转型的必经之路,在数字化浪潮下,大数据技术应运而生,并提出了数据湖的概念,数据湖是一个以原始格式存储数据的存储库或系统,可以按原始格式存储数据,而无需事先对数据进行结构化处理,一个数据湖可以存储结构化数据,半结构化数据,非结构化数据和二进制数据。
2、当前数据入湖的方案层出不穷,相关技术中,主要基于数据库监控组件、消息队列和入湖组件等多个组件协作的形式实现入湖文件的生成,数据库监控组件监控数据库二进制文件的变化,如数据库有变化则将变化内容组装成json数据格式发送到消息队列,入湖组件监听消息队列,执行入湖操作,上述数据入湖操作涉及组件多,需要每个组件都保证高可用,数据生成操作高度依赖中间件,同时也依赖于数据库的主从架构的稳定性,外部依赖比较多,导致入湖文件生成系统的稳定性较差。
3、针对上述的问题,目前尚未提出有效的解决方案。
技术实现思路
1、本发明实施例提供了一种数据入湖文件的生成方法及其装置、电子设备及存储介质,以至少解决相关技术中,基于数据库监控组件、消息队列和入湖组件等多个组件协作的形式实现入湖文件的生成,对多个组件的依赖性较强,导致入湖文件生成系统的稳定性较差的技术问题。
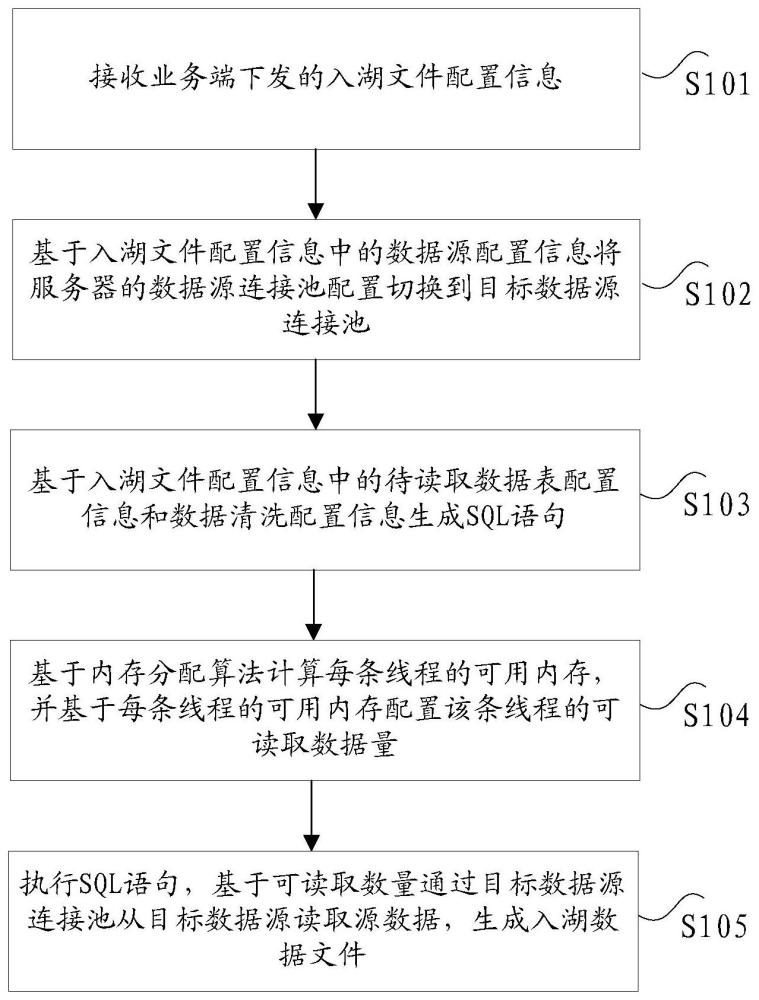
2、根据本发明实施例的一个方面,提供了一种数据入湖文件的生成方法,包括:接收业务端下发的入湖文件配置信息,其中,所述入湖文件配置信息至少包括:数据源配置信息、待读取数据表配置信息以及数据清洗配置信息;基于所述入湖文件配置信息中的所述数据源配置信息将服务器的数据源连接池配置切换到目标数据源连接池,其中,所述目标数据源连接池用于建立所述服务器与目标数据源的连接;基于所述入湖文件配置信息中的所述待读取数据表配置信息和所述数据清洗配置信息生成sql语句;基于内存分配算法计算每条线程的可用内存,并基于所述每条线程的可用内存配置该条线程的可读取数据量;执行所述sql语句,基于所述可读取数据量通过所述目标数据源连接池从所述目标数据源读取源数据,生成入湖数据文件。
3、可选地,在接收业务端下发的入湖文件配置信息之前,还包括:确定待执行数据入湖操作的所有数据源,得到数据源信息;基于所述数据源信息确定数据源连接池需求,其中,所述数据源连接池需求至少包括:最大连接数、最小空闲连接数以及连接超时时长;基于所述数据源连接池需求,为所述数据源创建数据源连接池。
4、可选地,在为所述数据源创建数据源连接池之后,还包括:对所有所述数据源连接池进行初始化操作,其中,所述初始化操作用于为服务器提供动态切换数据源连接池的功能;为所述数据源连接池配置标识信息。
5、可选地,基于内存分配算法计算每条线程的可用内存,并基于所述每条线程的可用内存配置该条线程的可读取数据量的步骤包括:计算服务器的可使用内存,并基于预设内存分配比例计算入湖文件生成操作对应的内存;基于所述入湖文件生成操作对应的内存和当前正在执行的线程数量计算所述每条线程的可用内存;基于所述每条线程的可用内存和数据内存占用规则计算每条线程的可读取数据量,并为每条线程配置所述可读取数据量。
6、可选地,基于所述可读取数据量通过所述目标数据源连接池从所述目标数据源读取源数据,生成入湖数据文件的步骤包括:基于所述目标数据源连接池与所述目标数据源建立连接;采用数据流管道的方式从所述目标数据源读取所述可读取数据量指示的源数据,其中,所述数据流管道的方式提供持续从数据源读取数据的功能;基于所述源数据生成数据文件;基于所述数据文件生成数据校验文件,其中,所述数据校验文件用于对所述数据文件进行校验,所述数据校验文件中存储有校验参数;基于所述数据文件和所述数据校验文件生成所述入湖数据文件。
7、可选地,所述校验参数至少包括:所述数据文件的文件标识、所述数据文件的md5值、所述数据文件的文件大小。
8、可选地,所述数据清洗配置信息包括下述至少之一:按照首次全量读取时间戳清洗数据、按照增量读取时间戳清洗数据、按照异常字符过滤字段清洗数据,其中,所述异常字符为预先配置的不符合入湖文件生成规则的字符数据。
9、根据本发明实施例的另一方面,还提供了一种数据入湖文件的生成装置,包括:接收单元,用于接收业务端下发的入湖文件配置信息,其中,所述入湖文件配置信息至少包括:数据源配置信息、待读取数据表配置信息以及数据清洗配置信息;切换单元,用于基于所述入湖文件配置信息中的所述数据源配置信息将服务器的数据源连接池配置切换到目标数据源连接池,其中,所述目标数据源连接池用于建立所述服务器与目标数据源的连接;生成单元,用于基于所述入湖文件配置信息中的所述待读取数据表配置信息和所述数据清洗配置信息生成sql语句;计算单元,用于基于内存分配算法计算每条线程的可用内存,并基于所述每条线程的可用内存配置该条线程的可读取数据量;读取单元,用于执行所述sql语句,基于所述可读取数据量通过所述目标数据源连接池从所述目标数据源读取源数据,生成入湖数据文件。
10、可选地,所述数据入湖文件的生成装置还包括:第一确定模块,用于确定待执行数据入湖操作的所有数据源,得到数据源信息;第二确定模块,用于基于所述数据源信息确定数据源连接池需求,其中,所述数据源连接池需求至少包括:最大连接数、最小空闲连接数以及连接超时时长;第一创建模块,用于基于所述数据源连接池需求,为所述数据源创建数据源连接池。
11、可选地,所述数据入湖文件的生成装置还包括:第一初始化模块,用于对所有所述数据源连接池进行初始化操作,其中,所述初始化操作用于为服务器提供动态切换数据源连接池的功能;第一配置模块,用于为所述数据源连接池配置标识信息。
12、可选地,所述计算单元包括:第一计算模块,用于计算服务器的可使用内存,并基于预设内存分配比例计算入湖文件生成操作对应的内存;第二计算单元,用于基于所述入湖文件生成操作对应的内存和当前正在执行的线程数量计算所述每条线程的可用内存;第三计算单元,用于基于所述每条线程的可用内存和数据内存占用规则计算每条线程的可读取数据量,并为每条线程配置所述可读取数据量。
13、可选地,所述读取单元包括:第一建立模块,用于基于所述目标数据源连接池与所述目标数据源建立连接;第一读取模块,用于采用数据流管道的方式从所述目标数据源读取所述可读取数据量指示的源数据,其中,所述数据流管道的方式提供持续从数据源读取数据的功能;第一生成模块,用于基于所述源数据生成数据文件;第二生成模块,用于基于所述数据文件生成数据校验文件,其中,所述数据校验文件用于对所述数据文件进行校验,所述数据校验文件中存储有校验参数;第三生成模块,用于基于所述数据文件和所述数据校验文件生成所述入湖数据文件。
14、可选地,所述校验参数至少包括:所述数据文件的文件标识、所述数据文件的md5值、所述数据文件的文件大小。
15、可选地,所述数据清洗配置信息包括下述至少之一:按照首次全量读取时间戳清洗数据、按照增量读取时间戳清洗数据、按照异常字符过滤字段清洗数据,其中,所述异常字符为预先配置的不符合入湖文件生成规则的字符数据。
16、根据本发明实施例的另一方面,还提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行上述任意一项数据入湖文件的生成方法。
17、根据本发明实施例的另一方面,还提供了一种电子设备,包括一个或多个处理器和存储器,所述存储器用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现上述任意一项数据入湖文件的生成方法。
18、在本公开中,通过以下步骤:先接收业务端下发的入湖文件配置信息,其中,入湖文件配置信息至少包括:数据源配置信息、待读取数据表配置信息以及数据清洗配置信息,并基于入湖文件配置信息中的数据源配置信息将服务器的数据源连接池配置切换到目标数据源连接池,其中,目标数据源连接池用于建立服务器与目标数据源的连接,再基于入湖文件配置信息中的待读取数据表配置信息和数据清洗配置信息生成sql语句,然后基于内存分配算法计算每条线程的可用内存,并基于每条线程的可用内存配置该条线程的可读取数据量,最后执行sql语句,基于可读取数据量通过目标数据源连接池从目标数据源读取源数据,生成入湖数据文件。
19、在本公开中,通过数据源连接池与多个数据源进行连接,从数据源读取数据,同时为线程动态分配内存,保证数据导出的高效性,入湖文件自动生成数据文件和数据校验文件,保证数据有效性,采用原生的数据入湖方式,不依赖中间件,保证了入湖文件系统的稳定性,进而解决了相关技术中,基于数据库监控组件、消息队列和入湖组件等多个组件协作的形式实现入湖文件的生成,对多个组件的依赖性较强,导致入湖文件生成系统的稳定性较差的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!