一种驾驶员注意力分散识别方法、智能座舱、电子设备与流程
本发明涉及一种识别方法、智能座舱、电子设备,尤其涉及一种驾驶员注意力分散识别方法、智能座舱、电子设备。
背景技术:
1、驾驶员在行车过程中左顾右盼是一种常见的行为。然而,在某些情况下,这种行为可能会影响到驾驶员对道路情况的注意,从而增加了发生交通事故的风险。例如,驾驶员在变道时,若未能及时注意到侧后方的车辆,可能会导致危险情况的发生。目前,现有技术的车辆行驶管理系统侧重于车辆的行驶数据、定位信息等方面的监测,对于驾驶员的行为及注意力状态的监测相对欠缺。传统的监测手段难以准确识别驾驶员的头部姿态和视线方向,已经不能满足人们的要求,亟需得到改进。
技术实现思路
1、本发明的目的在于提供一种驾驶员注意力分散识别方法、智能座舱、电子设备,实现对驾驶员行为的智能化实时监控,解决现有技术存在的缺憾。
2、本发明提供了下述方案:
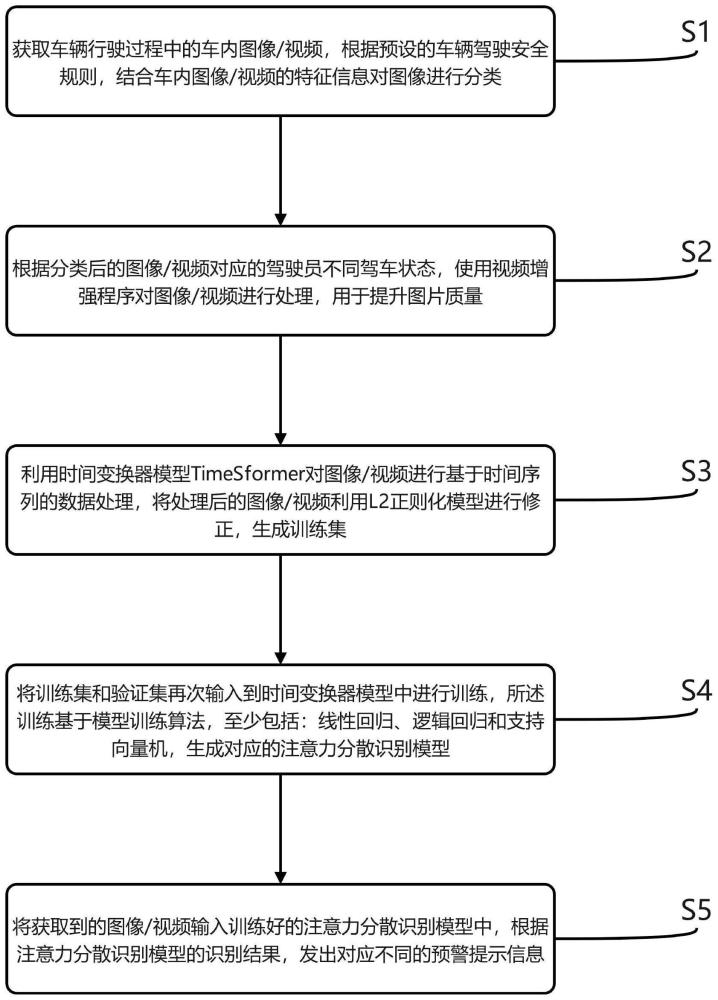
3、一种基于深度学习的驾驶员注意力分散识别方法,包括:
4、获取车辆行驶过程中的车内图像/视频,根据预设的车辆驾驶安全规则,结合车内图像/视频的特征信息对图像进行分类;
5、根据分类后的图像/视频对应的驾驶员不同驾车状态,使用视频增强程序对图像/视频进行处理;
6、利用时间变换器模型对图像/视频进行基于时间序列的数据处理,将处理后的图像/视频利用l2正则化模型进行修正,生成训练集;
7、将训练集和验证集再次输入到时间变换器模型中进行训练,所述训练集基于模型训练算法,至少包括:线性回归、逻辑回归和支持向量机,生成对应的注意力分散识别模型;
8、将获取到的图像/视频输入训练好的注意力分散识别模型中,根据注意力分散识别模型的识别结果,发出对应不同的预警提示信息。
9、进一步的,所述根据预设的车辆驾驶安全规则,结合车内图像/视频的特征信息对图像进行分类,进一步包括:所述图像/视频特征信息进一步包括:
10、用于表征驾驶员左顾右盼场景的第一驾车状态;
11、用于表征驾驶员正常行驶的第二驾车状态;
12、不属于第一、二驾驶状态的第三驾车状态,用于表征不属于第一、二驾驶状态的驾驶员其他不安全行为。
13、进一步的,还包括:
14、建立驾驶员驾车状态图像/视频库:获取驾驶员处于左顾右盼场景下的面部图像/视频,形成对应的图像/视频数据集;
15、基于时间序列将所述图像/视频分解成连续帧图像,并将所述连续帧图像转换为数字矩阵进行标注;
16、将标注后的数字矩阵发送给神经网络进行学习,进行迭代优化和权重配置,直到神经网络输出能够识别驾驶员左顾右盼场景的第一结果变量;
17、将所述第一结果变量标记为第一驾车状态进行存储,用于视频增强处理以及作为时间变换器模型的输入量。
18、进一步的,所述根据分类后的图像/视频对应的驾驶员不同驾车状态,使用视频增强程序对图像/视频进行处理,进一步包括:
19、使用videomix数据增强技术将分类后的第一视频与第二视频进行数据融合,所述第一视频为驾驶员在第一时间段的驾驶状态,所述第二视频为驾驶员在第二时间段的驾驶状态,第一、二时间段基于时间序列进行分布;
20、接收第一、二时间段的关键帧和时间戳信息,对每个关键帧进行特征提取,获得对应不同的特征值,并根据时间戳信息对第一、二时间段进行同步处理;
21、对同步处理后的第一、二时间段进行时空融合,并比较特征值,用于对第一、二视频进行视频信息的时空融合。
22、进一步的,所述利用时间变换器模型对图像/视频进行基于时间序列的数据处理,将处理后的图像/视频利用l2正则化模型进行修正,生成训练集,进一步包括:
23、获取图像/视频的每一帧图片,并将每一帧图片转化为特征向量;
24、建立时间维度与所述特征向量之间的映射关系,通过不同映射关系之间的权重获得映射关系对应的动态变化信息;
25、根据所述动态变化信息输入进机器学习模型,基于l2正则化的损失函数对所述动态变化信息进行训练。
26、进一步的,所述基于l2正则化的损失函数对所述动态变化信息进行训练,具体为:
27、获取时间变换器模型的参数,将所述时间变换器的参数输入进一个损失函数中,所述损失函数用于衡量模型预测结果与真实值之间的差异;
28、建立损失函数的惩罚项,所述惩罚项是时间变换器的参数进行平方和计算后与一个调节参数相乘,获取惩罚项系数值;
29、根据事先设定的阈值检测损失函数的惩罚项是否达到了过拟合的程度,如果未达到过拟合的程度,则进行迭代运算,直到损失函数的惩罚项超过了过拟合的程度,停止迭代运算,并记录超过了过拟合程度的前一次的计算结果。
30、一种基于深度学习的驾驶员注意力分散识别系统,包括:
31、车内图像/视频获取及分类模块,用于获取车辆行驶过程中的车内图像/视频,根据预设的车辆驾驶安全规则,结合车内图像/视频的特征信息对图像进行分类;
32、图像/视频增强处理模块,根据分类后的图像/视频对应的驾驶员不同驾车状态,使用视频增强程序对图像/视频进行处理;
33、时间变换器模型修正模块,利用时间变换器模型对图像/视频进行基于时间序列的数据处理,将处理后的图像/视频利用l2正则化模型进行修正,生成训练集;
34、时间变换器模型训练模块,将训练集和验证集再次输入到时间变换器模型中进行训练,所述训练集基于模型训练算法,至少包括:线性回归、逻辑回归和支持向量机,生成对应的注意力分散识别模型;
35、预警提示信息发送模块,将获取到的图像/视频输入训练好的注意力分散识别模型中,根据注意力分散识别模型的识别结果,发出对应不同的预警提示信息。
36、一种智能座舱,其特征在于,所述智能座舱中设置有基于深度学习的驾驶员注意力分散识别系统。
37、一种电子设备,包括:处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;所述存储器中存储有计算机程序,当所述计算机程序被所述处理器执行时,使得所述处理器执行所述方法的步骤。
38、一种计算机可读存储介质,其存储有可由电子设备执行的计算机程序,当所述计算机程序在所述电子设备上运行时,使得所述电子设备执行所述方法的步骤。
39、本发明与现有技术相比具有以下的优点:
40、本发明基于计算机视觉技术对驾驶员的头部姿态和其他身体姿态进行识别,可以实时监测驾驶员是否在左顾右盼。本发明能够有效提升驾驶员的安全意识和警觉性,从而降低交通事故的发生率,通过计算机视觉技术对头部姿态进行识别,并及时向司机发出警示信号或提醒他们注意道路情况,可以大大减少分心行为带来的潜在危险,减少由于分心、疲劳、左顾右盼等原因引起的交通事故。
41、为了能够智能化地解决司机分心、疲劳、左顾右盼导致的交通安全隐患,本发明通过对图像/视频增强程序对图像进行分类处理,提升了采集车内图像/视频的清晰度,并利用了时间变换器模型、损失函数及其l2正则化处理方法对基于时间序列的数据进行处理,防止算法在运行时出现过拟合现象,添加了数据模型的泛化能力,提高了驾驶员注意力分散识别方法的应用范围。
42、不仅如此,本发明还通过videomix数据增强技术将分类后的视频/图像数据进行融合处理,基于关键帧和时间戳进行特征提取,实现了不同视频的时空融合,更有利于深度学习模型的应用和训练。
- 还没有人留言评论。精彩留言会获得点赞!