一种基于不经意随机访问机的函数依赖发现方法
本发明属于信息安全,尤其涉及一种基于不经意随机访问机的函数依赖发现方法。
背景技术:
1、随着云计算的迅速发展和数据存储需求的不断增加,将数据库外包给云服务提供商的模式正变得越来越受欢迎。通过这种模式,用户无需自行设置、管理和维护存储设备,而是根据实际使用量支付相应费用,十分便捷和高效。
2、同时,外包数据库也带来了数据安全相关的问题,因为云服务提供商有可能窥探或泄露用户的数据。为了解决这一问题,一些加密数据库的方案应运而生,它们利用密码学技术或可信执行环境(tee)来保护用户的数据隐私。然而,现有的加密数据库技术主要关注范围查询、连接查询等查询操作相关的问题,对于加密数据库维护(如函数依赖的发现)方面的关注则很少。
3、函数依赖(functional dependency)描述了数据库中属性之间的对应关系,即一个属性(或属性集合)的值能唯一决定另一个属性(或属性集合)的值,它帮助我们理解和设计数据库结构,也是优化数据库性能和查询速度的重要依据。
4、学术文献frequency-hiding dependency-preserving encryption foroutsourced databases.in 2017ieee 33rd international conference on dataengineering(icde),pages 721–732,2017是目前唯一一项在加密数据库中进行函数依赖发现的工作。然而,此方案存在严重的安全性问题——泄漏了明文的部分频率信息。由于明文频率信息泄漏会导致数据的安全性受到威胁,所以该方案并不适合实际应用。
5、因此,什么是安全的函数依赖发现,以及如何实现安全的函数依赖发现仍然是有待解决的问题。
技术实现思路
1、为了解决上述问题,本发明首先给出了安全的函数依赖发现方法的定义。考虑到加密数据库中数据库大小的泄漏通常是可以接受的,以及所发现的函数依赖的泄漏是进行数据库维护任务的必要条件,本发明将这种泄漏称为安全的函数依赖发现的最小泄漏。基于此,一种安全的函数依赖发现方法只会泄漏数据库大小和所发现的函数依赖,而不会泄漏任何其他信息。
2、本发明提出一种基于不经意随机访问机(oblivious ram,oram)的函数依赖发现方法,在基于分区的函数依赖发现方法的基础上,通过将对数据库按照在属性集合上的取值分区的过程转变为不经意的,实现了上述安全的函数依赖发现。
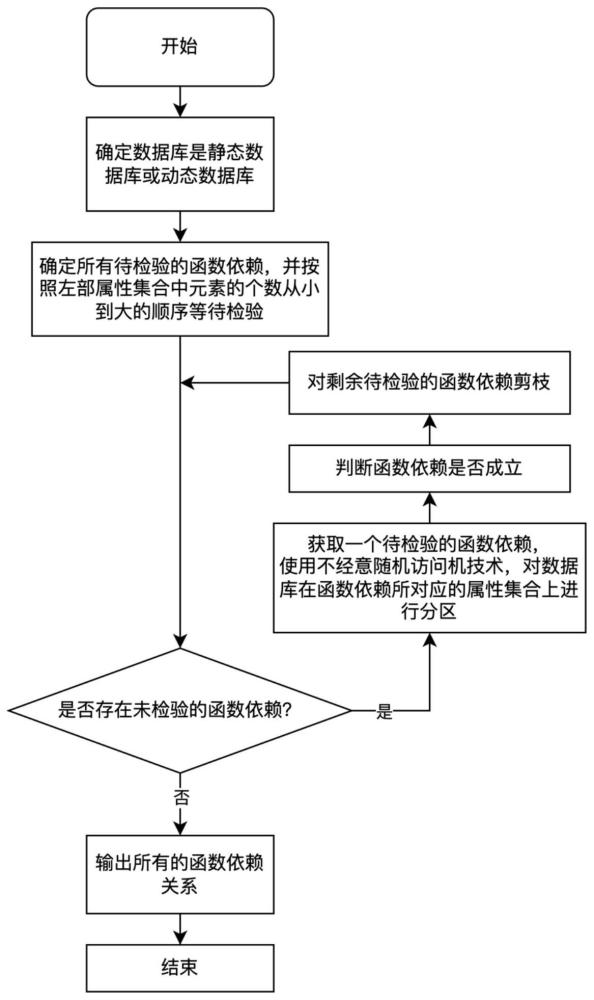
3、本发明所采用的技术方案是一种基于不经意随机访问机(oblivious ram,oram)的函数依赖发现方法,包括以下步骤:
4、(1)确定所要进行函数依赖发现的数据库是静态数据库还是动态数据库;
5、(2)根据数据库中的属性得到属性格,确定所有待检验的函数依赖集合;
6、(3)利用不经意随机访问机,对待检验的函数依赖关系按照左部属性集合中所包含的元素个数从小到大进行检验,在此过程中,根据已检验的函数依赖关系对剩余的待检验的函数依赖关系进行剪枝操作;
7、(4)输出所发现的函数依赖关系。
8、具体地,所述不经意随机访问机(oram)是一种密码学原语,用于隐藏程序对内存的访问模式,即所访问的指令、地址和数据,以保护程序的隐私和安全,防止敌手通过观察内存访问模式来推断出敏感信息;将oram看作一种键值存储,即键-值oram,其中键为一个唯一的标识符,值为一个任意的数据项;oram支持两种基本的操作:读和写,读操作是根据给定的“键”,返回对应的“值”;写操作是根据给定的“键”和“值”,更新或插入一个(“键”,“值”)对。
9、具体地,所述步骤(1)中所述静态数据库在数据库建立后没有数据的插入、删除或更新;相反,动态数据库在数据库建立后有数据插入、删除或更新。
10、进一步地,所述步骤(2)具体为:用空集作为根节点,将数据库中的每个单独属性作为第一层节点,每两个属性的组合作为第二层节点,以此类推,直到用所有的属性的组合作为最后一层的节点;每条边连接两个相邻层的节点,如果所连接的上层节点是下层节点的子集,那么这条边就表示一个从上层节点所包含的属性到下层节点减去上层节点所包含的属性的函数依赖。
11、进一步地,所述步骤(3)中对待检验的函数依赖关系按照左部属性集合中所包含的元素个数从小到大的顺序进行检验,其检验函数依赖关系是否成立的具体过程为:对待检验的函数依赖关系x→y进行检验的过程中,分别计算数据库在属性集合x和属性集合x∪y上的分区(πx和πx∪y),函数依赖关系x→y成立当且仅当在属性集合x和属性集合x∪y上的分区的数量相等(|πx|=|πx∪y|);所述的分区的过程是将数据库中的记录按在某个属性集合上的取值分成不重叠的子集,满足同一子集内的记录在该属性集合上取值相同,不同子集内的记录在该属性集合上取值不同。
12、进一步地,所述步骤(3)中,对待检验的函数依赖关系x→y进行检验的过程中,需利用不经意随机访问机实现在属性集合x和属性集合x∪y上的分区(πx和πx∪y)的计算,当确定的数据库为静态数据库,其在一个属性集合上分区的具体过程包括:
13、(3.1)如果当前属性集合仅包含一个属性,即当前是在单个属性上进行分区,则进行后续步骤;反之,将此属性集合的两个不同的真子集所对应的不经意随机访问机key-label oram作为本执行步骤的输入,其中两个真子集需满足交集为当前属性集合;特定的函数依赖的检验顺序能够保证已经计算出两个key-label oram;
14、(3.2)对当前属性集合创建两个不经意随机访问机key-label oram和id-labeloram,并使用安全参数对其进行初始化;将分区计数器初始值设置为0;所述key指一个记录在某个属性集合上的取值;所述label是用于标识分区后的一个记录所属的集合;所述id为一个记录在数据库中的唯一标识;
15、(3.3)基于步骤(3.2)中的创建的不经意随机访问机和分区计数器,对数据库中的所有记录执行后续步骤;
16、(3.4)对于步骤(3.3)中的每一个记录,获取该记录的key;
17、(3.5)使用步骤(3.4)中获取的key在当前属性集合的key-label oram中进行查询,获取label:
18、如果查询结果为空,则将当前分区计数器的值作为该记录的label,并将该记录的键值对(key,label)存入当前属性集合的key-label oram,将该记录的键值对(id,label)存入当前属性集合的id-label oram中,同时将分区计数器的值增加1;
19、反之,如果查询结果不为空,将该记录的键值对(id,label)存入当前属性集合的id-label oram中;
20、(3.6)在处理完所有记录后,将当前属性集合的key-label oram和id-label oram以及分区计数器的值作为输出;所述输出的key-label oram中包含了具体的分区结果,所述输出的id-label oram作为数据库在后续的属性集合上计算分区时的输入,所述输出的分区计数器的值即为数据库在当前属性集合上分区的数目。
21、进一步地,所述步骤(3)中,在对一个待检验的函数依赖关系x→y进行检验的过程中,需利用不经意随机访问机计算数据库在属性集合x和x∪y上的分区(πx和πx∪y),当确定的数据库为动态数据库,其在一个属性集合上分区的具体过程包括:
22、(4.1)如果当前属性集合中只包含一个属性,则进行后续步骤;反之,需要以此属性集合的两个不同的真子集所对应的不经意随机访问机id-key-label oram作为本执行步骤的输入,其中两个真子集需满足交集为当前属性集合;特定的函数依赖的检验顺序保证已经计算出这样的两个id-key-label oram;
23、(4.2)对当前属性集合创建两个不经意随机访问机key-label-frequency oram和id-key-label oram,并使用安全参数对其进行初始化;将分区计数器初始值设置为0;所述key指一个记录在某个属性集合上的取值;所述label用于标识分区后的一个记录所属的集合;所述id为一个记录在数据库中的唯一标识;所述的frequency用于记录在当前属性集合上的取值为key的元素的个数;
24、(4.3)基于(4.2)中的创建的不经意随机访问机和分区计数器,对数据库中的所有记录执行后续步骤;
25、(4.4)对于步骤(4.3)中的每一个记录,获取该记录的key;
26、(4.5)使用步骤(4.4)中获取的key在当前属性集合的key-label-frequency oram中进行查询:
27、如果查询结果不为空,则对当前属性集合的key-label-frequency oram进行更新——将该记录所对应项的frequency加1,并结合当前记录的id构成键值对(id,(key,label)),将其存入当前属性集合对应的id-key-label oram中;
28、反之,如果查询结果为空,则将分区计数器的值作为label,设置frequency的值为1,然后结合当前记录的id构成键值对(id,(key,label))和(key,(label,frequency)),分别存入当前属性集合对应的id-key-label oram和key-label-frequency oram中,并将分区计数器的值增加1;
29、(4.6)在处理完所有记录后,将当前属性集合的两个oram以及分区计数器的值作为输出;
30、(4.7)动态数据库中,向数据库插入记录后,在当前属性集合上的分区需要更新,具体过程为:将要插入的记录当作步骤(4.4)中的还未访问到的记录,对该记录执行步骤(4.4)和(4.5),步骤(4.6)得到的输出即为插入后的结果;
31、(4.8)动态数据库中,从数据库中删除记录后,在当前属性集合上的分区需要更新,具体过程如下:
32、使用此记录的id来查询当前属性集合的id-key-label oram获取对应的key和label,使用所获得key查询key-label-frequency oram获取对应的label和frequency;
33、如果所得到的frequency的值不为1,则对key-label-frequency oram进行更新,将此key对应的frequency值减1;并在id-key-label oram中删除此记录的id所对应的项;
34、反之,如果所得到的frequency的值为1,删除key-label-frequency oram中此key所对应的内容;并在id-key-label oram中删除此记录的id所对应的项;并将当前属性集合的分区计数器的值减1。
35、具体地,所述步骤(3.4)和步骤(4.4)中获取一个记录的key的过程为:如果当前的属性集合中只包含一个属性,key即为该记录在此属性上的取值;如果当前属性集合中包含多个属性,key通过属性压缩的方法来确定,所述的属性压缩是将若干个属性的取值转换为单个值的方法,具体为:通过当前记录的id,分别在算法输入的当前属性集合的两个真子集对应的oram中查询当前记录所对应的label(和),则key的值为其中n为数据库中记录的总个数。
36、具体地,所述步骤(3)中需要根据已检验的函数依赖对剩余的待检验的函数依赖进行剪枝操作,具体为:如果通过已检验的函数依赖能够确定某些待检验的函数依赖是否成立,则这些待检验的函数依赖不需要被再被检验;当一个函数依赖不需要被检验时,需要将其从待检验的函数依赖集合中移除。
37、此外,该方法的所有执行步骤在具体实现时都需要以不经意的方式实现,即不能通过观察程序的运行时间以及其他相关因素来判断程序内部的执行情况。
38、与现有技术相比,本发明的有益效果:
39、1.基于不经意随机访问机,在加密数据库的基础上完成函数依赖发现,在整个过程中不会泄漏除了数据库大小和所发现的函数依赖以外的其他任何信息。本发明中的方案是第一个满足此安全要求的函数依赖发现方案。
40、2.本发明通过属性压缩的方案,减少了存储和计算的开销,进一步提高了效率和可扩展性。
41、3.本发明可以适用于动态的数据库。
42、4.本发明对加密数据库没有限制,容易与已有的加密数据库集成,具有实用性。
43、5.本发明具有通用性强、安全高效、保护隐私、使用简便、效率高、内存和存储消耗少等优点。
- 还没有人留言评论。精彩留言会获得点赞!