一种基于ResNet34神经网络的集成自蒸馏训练系统的制作方法
本发明涉及神经网络领域,尤其涉及一种基于resnet34神经网络的集成自蒸馏训练系统。
背景技术:
1、随着人工智能技术不断发展,深度神经网络算法已应用在图像分类、自然语言处理和语音识别等领域,并取得了重要成果。其中,在图像分类领域,googlenet、resnet、mobilenet等神经网络的提出,在分类任务上取得了较好的表现。然而,在传统的训练方法中,分类准确性往往取决于网络自身结构。在不增加参数条件下,提升网络性能是深度学习领域的难点。
2、知识蒸馏是一种提高网络分类准确性的训练方法,主要思想是让一个包含丰富知识的教师网络指导学生网络进行训练,使学生网络在训练过程中吸收教师网络中包含的丰富知识,从而在不改变学生网络结构的前提下,提升学生网络的性能。然而,知识蒸馏也有其局限性。首先,知识蒸馏需要一个强大的教师模型来提供知识,教师模型的训练会额外增加训练成本。其次,当教师模型和学生模型之间存在较大差异时,知识蒸馏可能无法显著提高学生模型的性能。
3、自蒸馏作为一种特殊的知识蒸馏方法,将神经网络自身作为教师网络,后通过额外构建多个浅层分类器作为学生网络,进行蒸馏。训练过程只有一次,规避掉了传统知识蒸馏的局限性,但自蒸馏训练方式仍存在优化空间。现有自蒸馏方案往往指定神经网络向浅层分类器传递知识,这些知识仅来自神经网络,信息质量依赖网络自身性能。此外,自蒸馏框架内无额外知识辅助神经网络训练。基于此,本发明针对resnet34神经网络提出一种集成自蒸馏训练方案,通过集成神经网络与浅层分类器的特征,额外构建集成分类器,可为神经网络与浅层分类器提供信息更丰富、质量更高的知识,进一步提升网络性能。
技术实现思路
1、针对自蒸馏训练方案无法为神经网络及浅层分类器提供高质量知识的问题,本发明提出了一种基于resnet34神经网络的集成自蒸馏训练方案。该方案首先将resnet34网络分层模块化,在各模块依次添加注意力模块和浅层模块构建多个浅层分类器,完成自蒸馏框架的搭建,后集成各个浅层分类器与resnet34网络相关特征,构建集成模型作为教师网络,各浅层分类器和resnet34网络作为学生网络,来进行自蒸馏训练。相较于原训练方式,本方案能够进一步提高网络的精确度和泛化能力。
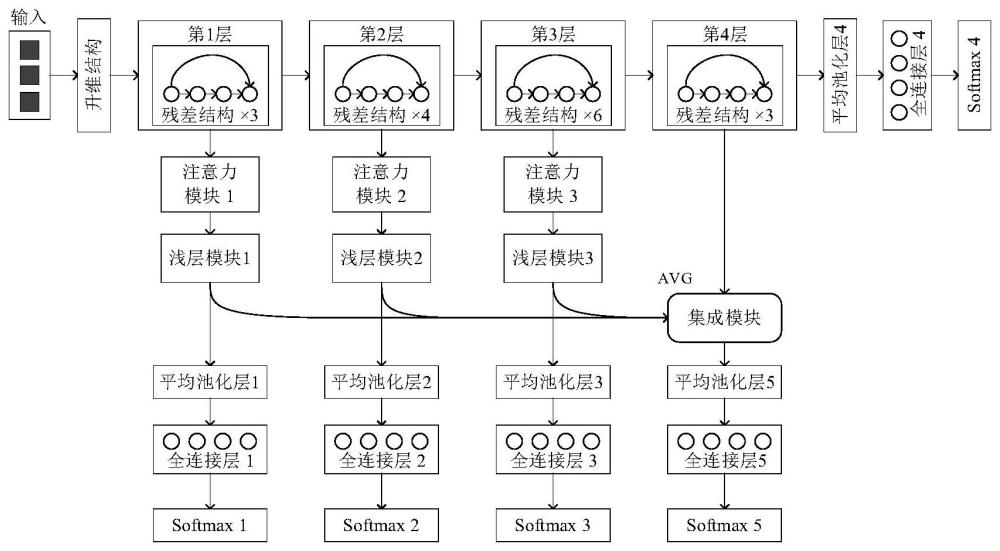
2、本发明提出的一种基于resnet34神经网络的集成自蒸馏训练系统,包括:整体架构,整体架构由resnet34网络、3个浅层分类器和1个集成分类器组成;resnet34网络按由浅到深的顺序依次为升维结构、4层结构、平均池化层4、全连接层4和softmax4;浅层分类器1由升维结构、第1层结构、注意力模块1、浅层模块1、平均池化层1、全连接层1和softmax1组成;浅层分类器2由升维结构、第1层结构、第2层结构、注意力模块2、浅层模块2、平均池化层2、全连接层2和softmax2组成;浅层分类器3由升维结构、第1层结构、第2层结构、第3层结构、注意力模块3、浅层模块3、平均池化层3、全连接层3和softmax3组成;集成分类器由集成模块、平均池化层5、全连接层5、softmax5组成;其中,resnet34网络、浅层分类器和集成分类器主要通过大量卷积层构成。
3、本发明进一步的技术方案在于,记单个卷积层的卷积核大小为kernel_size;步距为stride,默认为1;填充为padding,默认为0;输入特征图的通道数为in_put,输出特征图的通道数为out_put,resnet34网络中的升维结构依次由1个卷积层、1个批归一化层和1个relu激活函数组成,其中,卷积层的kernel_size为3,padding为1,in_put为3,out_put为64,特征图经过升维结构后,尺寸不变,通道数变为64,resnet34网络的4层结构由数目不同的残差结构堆叠而成,残差结构分为普通残差结构和下采样残差结构两种实现,都接收两个参数,分别为输入特征图的通道数in_channel和输出特征图的通道数out_channel。
4、本发明进一步的技术方案在于,普通残差结构由2个卷积层、2个批归一化层和2个relu激活函数组成,其中,卷积层1的kernel_size为3,padding为1,in_put为in_channel,out_put为out_channel,卷积层2的kernel_size为3,padding为1,in_put为out_channel,out_put为out_channel,输入普通残差结构的特征图x1依次经过卷积层1、批归一化层1、relu激活函数1、卷积层2和批归一化层2后的结果,与原来的x1值相加,得到的值再经过relu激活函数2,最终结果即为普通残差结构的输出,特征图经过普通残差结构后,尺寸不变,通道数变为参数out_channel。
5、本发明进一步的技术方案在于,下采样残差结构的卷积层1的stride为2,并且在分支路径上多了一个kernel_size为1,stride为2,in_put为in_channel,out_put为out_channel的下采样卷积,输入下采样残差结构的特征图x2依次经过卷积层1、批归一化层1、relu激活函数1、卷积层2和批归一化层2后的结果,与原来的x2经过下采样卷积后的值相加,得到的值再经过relu激活函数2,最终结果即为下采样残差结构的输出,特征图经过下采样残差结构后,尺寸缩减为原来的1/2,通道数变为参数out_channel。
6、本发明进一步的技术方案在于,resnet34的第1层结构由3个in_channel为64,out_channel为64的普通残差结构堆叠而成,特征图经过第1层结构后,尺寸不变,通道数变为64,第2层结构由1个in_channel为64,out_channel为128的下采样残差结构和3个in_channel为128,out_channel为128的普通残差结构堆叠而成,特征图经过第2层结构后,尺寸缩减为原来的1/2,通道数变为128,第3层结构由1个in_channel为128,out_channel为256的下采样残差结构和5个in_channel为256,out_channel为256的普通残差结构堆叠而成,特征图经过第3层结构后,尺寸缩减为原来的1/2,通道数变为256,第4层结构由1个in_channel为256,out_channel为512的下采样残差结构和2个in_channel为512,out_channel为512的普通残差结构堆叠而成,特征图经过第4层结构后,尺寸缩减为原来的1/2,通道数变为512,平均池化层4的输出特征图尺寸为1×1,全连接层4的结点个数为num_classes,其中num_classes指的是图像类别个数。
7、本发明进一步的技术方案在于,浅层分类器中的注意力模块依次由浅层卷积结构、批归一化层、relu激活函数、上采样层和sigmoid激活函数组成,其中,浅层卷积结构依次由深度卷积层1、逐点卷积层1、批归一化层1、relu激活函数1、深度卷积层2、逐点卷积层2、批归一化层2和relu激活函数2组成;其中,深度卷积层1的kernel_size为3,padding为1,stride为2,in_put为in_channel_2,out_put为in_channel_2;深度卷积层2的kernel_size为3,padding为1,in_put为in_channel_2,out_put为in_channel_2;逐点卷积层1的kernel_size为1,in_put为in_channel_2,out_put为in_channel_2;逐点卷积层2的kernel_size为1,in_put为in_channel_2,out_put为out_channel_2,特征图经过浅层卷积结构后,尺寸缩减为原来的1/2,通道数变为参数out_channel_2,注意力模块的上采样层的倍率因子为2,作用是将特征图的尺寸增加到原来的2倍,在注意力模块中,输入注意力模块的特征图x3依次经过浅层卷积结构、批归一化层、relu激活函数、上采样层和sigmoid激活函数后的结果,与原x3的值进行点积操作,最终结果即为注意力模块的输出,特征图经过注意力模块后,特征图的尺寸不变,通道数变为参数out_channel_1,注意力模块1的in_channel_1为64,out_channel_1为64;注意力模块2的in_channel_1为128,out_channel_1为128;注意力模块3的in_channel_1为256,out_channel_1为256。
8、本发明进一步的技术方案在于,浅层分类器中的浅层模块主要由不同数量的浅层卷积结构堆叠而成,浅层模块1由3个浅层卷积结构组成,第一个的参数in_channel_2为64,out_channel_2为128;第二个的参数in_channel_2为128,out_channel_2为256;第三个的参数in_channel_2为256,out_channel_2为512,特征图经过浅层模块1后,尺寸缩减为原来的1/8,通道数变为512,浅层模块2由2个浅层卷积结构组成,第一个的参数in_channel_2为128,out_channel_2为256;第二个的参数in_channel_2为256,out_channel_2为512,特征图经过浅层模块2后,尺寸缩减为原来的1/4,通道数变为512,浅层模块3由1个浅层卷积结构组成,其参数in_channel_2为256,out_channel_2为512,特征图经过浅层模块3后,尺寸缩减为原来的1/2,通道数变为512,平均池化层i(i=1,2,3)的输出特征图尺寸为1×1,全连接层i(i=1,2,3)的结点个数为num_classes。
9、本发明进一步的技术方案在于,集成分类器主要由集成模块构成,其中集成模块依次由1个卷积层、1个批归一化层、1个relu激活函数组成,其中,卷积层的kernel_size为3,in_put为512,out_put为512,特征图经过集成模块后,尺寸缩减为原来的1/2,通道数变为512,平均池化层5的输出特征图尺寸为1×1,全连接层5的结点个数为num_chasses,softmax i(i=1,2,3,4,5)为激活函数,用于将神经网络的输出值转化为概率分布。
10、本发明进一步的技术方案在于,集成自蒸馏框架搭建完成后即可用数据集进行训练,数据集中的数据作为升维结构的输入特征图,升维结构的输出特征图作为第1层结构的输入特征图,第1层结构的输出特征图既作为注意力模块1的输入特征图,也作为第2层结构的输入特征图,注意力模块1的输出特征图作为浅层模块1的输入特征图,浅层模块1的输出特征图作为平均池化层1的输入特征图,平均池化层1的输出特征图作为全连接层1的输入特征图,softmax1作用于全连接层1的输出特征图后即可作为浅层分类器1的分类结果,第2层结构的输出特征图既作为注意力模块2的输入特征图,也作为第3层的输入特征图,注意力模块2的输出特征图作为浅层模块2的输入特征图,浅层模块2的输出特征图作为平均池化层2的输入特征图,平均池化层2的输出特征图作为全连接层2的输入特征图,softmax2作用于全连接层2的输出特征图后即可作为浅层分类器2的分类结果,第3层结构的输出特征图既作为注意力模块3的输入特征图,也作为第4层的输入特征图,注意力模块3的输出特征图作为浅层模块3的输入特征图,浅层模块3的输出特征图作为平均池化层3的输入特征图,平均池化层3的输出特征图作为全连接层3的输入特征图,softmax3作用于全连接层3的输出特征图后即可作为浅层分类器3的分类结果,第4层结构的输出特征图作为平均池化层4的输入特征图,平均池化层4的输出特征图作为全连接层4的输入特征图,softmax4作用于全连接层4的输出特征图后即为resnet34网络的分类结果,浅层模块i(i=1,2,3)输出和第4层结构的输出特征图求和取平均作为集成模块的输入特征图,集成模块的输出特征图作为平均池化层5的输入特征图,平均池化层5的输出特征图作为全连接层5的输入特征图,softmax5作用于全连接层5的输出特征图后即可作为集成分类器的分类结果。
11、本发明进一步的技术方案在于,基于resnet34网络蒸馏训练在两个数据集上进行训练,且所有实验均在gpu设备上,pytorch 2.0.1环境下进行;
12、cifar100:训练200个epoch,通过sgd优化器对神经网络进行优化,初始的学习率为0.1,当训练到66、133和190个epoch的时候,学习率除以10,权值衰减weight_decay=5e-4,每次更新的变化量momentum=0.9;batchsize为128,蒸馏温度t为3;所有实验均在gpu设备上,pytorch2.0.1环境下进行,训练之前对cifar100数据集的训练集进行了如下处理:(1)对图片进行随机裁剪,裁剪后尺寸(size)为32,填充边界的值(padding)设置为4,填充值(fill)设置为128;(2)对图片进行随机水平翻转;(3)将图片格式转换为tensor格式;将图片的每一个数值归一化到[0,1];(4)将图片的每一个数值进行标准化处理,标准化处理的均值为(0.4914,0.4822,0.4465),方差为(0.2023,0.1994,0.2010),对cifar100数据集的测试集进行如下处理:(1)将图片格式转换为tensor格式;将图片的每一个数值归一化到[0,1];(2)将图片的每一个数值进行标准化处理,标准化处理的均值为(0.4914,0.4822,0.4465),标准差为(0.2023,0.1994,0.2010);
13、tiny imagenet:训练100个epoch,通过sgd优化器对神经网络进行优化,初始的学习率为0.1,当训练到33、66和90个epoch的时候,学习率除以10,权值衰减weight_decay=5e-4,每次更新的变化量momentum=0.9;batchsize为128,蒸馏温度t为3,训练之前对tinyimagenet数据集的训练集进行了如下处理:(1)对图片进行随机旋转,最大旋转角度为20度,(2)对图片进行随机水平翻转,翻转概率是0.5,(3)将图片格式转换为tensor格式,(4)将图片的每一个数值进行标准化处理,标准化处理的均值为(0.4802,0.4481,0.3975),方差为(0.2302,0.2265,0.2262),对tiny imagenet数据集的测试集进行如下处理:(1)将图片格式转换为tensor格式,(2)将图片的每一个数值进行标准化处理,标准化处理的均值为(0.4802,0.4481,0.3975),方差为(0.2302,0.2265,0.2262);
14、在softmax函数中引入温度系数t,可以通过修改温度系数的值使输出的标签软化,温度t越大,输出结果的概率分布就越软,在公式(1)中,zj指第j类别的输出结果,若分类类别总数为m,则j的取值范围为[1,m],zn为经过全连接层后,第n类别对应位置的值,pn为分类器第n类别的输出概率,
15、
16、本发明所述的训练方法,包含三种损失,loss1为l2损失,loss2为kl散度损失,loss3为交叉熵损失,
17、loss1:计算平均池化层5的输出特征图分别与平均池化层i(i=1,2,3)的输出特征图之间的l2损失,再对3个损失值求和,得到的值乘上损失权重后,最终结果即为loss1的值,loss1损失如公式(2)所示,在公式(2)中,fi表示平均池化层i(i=1,2,3,5)的输出特征图;β表示该损失的权重,
18、
19、loss2:计算softmax 5函数t=3时的输出分别与softmax i(i=1,2,3,4)函数t=3时的输出之间的kl散度损失,再对4个损失值求和,得到的值乘上损失权重后,最终结果即为loss2的值,loss2损失如公式(3)所示,在公式(3)中,kl表示kl散度;pi表示softmax i(i=1,2,3,4,5)函数t=3时的输出;α表示该损失的权重,
20、
21、loss3:计算softmax 5函数t=1时的输出与真实标签的交叉熵损失,记为loss1,计算softmax i(i=1,2,3,4)函数t=1时的输出与真实标签的交叉熵损失,再对4个损失值求和,得到的值乘上损失权重后,记为loss2,loss1与loss2的和即为loss3的值,loss3的损失如公式(4)所示,在公式(4)中,cr表示交叉熵损失函数;qi表示softmax i(i=1,2,3,4)函数t=1时的输出;y表示真实标签label的值;(1-α)表示loss2的权重,
22、
23、总的损失函数loss由以上三部分构成,数学表达式如公式(5)所示,
24、
25、综上所述,本发明所述方案以resnet34网络为基础搭建集成自蒸馏框架,以集成分类器作为教师网络,再以resnet34和浅层分类器作为学生网络进行蒸馏训练,通过实验数据显示,该方法能够提升网络表现,进一步提升自蒸馏效果。
26、与现有技术相比,本发明的有益效果为:
27、1、本发明通过构建集成分类器作为教师网络,可将更高质量的知识传递给神经网络和浅层分类器,相较于单一网络提供的知识,集成分类器的知识包含更丰富的信息,可以进一步提升神经网络的泛化性和鲁棒性。
28、2、本发明通过仿真表明,在cifar100数据集和tiny imagenet上,整体准确率得到一定的提升,对于cifar100,仅使用resnet34网络进行训练的准确率为77.9%,而本蒸馏训练方案的准确率达到了80.7%,提高了2.8%,对于tiny imagenet,仅使用resnet34网络进行训练的准确率为65.2%,而本蒸馏训练方案的准确率达到了67.7%,提高了2.5%。
29、3、本发明具有普适性,可广泛应用于基于resnet34网络的图像分类、图像识别、图像分割及图像去噪等任务。
- 还没有人留言评论。精彩留言会获得点赞!