一种基于深度强化学习的直播商品实时调度系统及方法与流程
本发明涉及商品推荐,尤其涉及一种基于深度强化学习的直播商品实时调度系统及方法。
背景技术:
1、电子商务直播领域,现行的商品调度策略主要分为两种:一是预先安排的商品售卖顺序,二是依赖于直播过程中主播的即时调整。尽管前者能够确保直播内容的结构性和连贯性,它却缺乏对观众实时互动的响应能力,从而未能最大化观众参与度对商品售卖顺序的影响。相反,后者虽然在某种程度上增加了互动性,但却过分依赖于主播的个人判断,可能导致商品调度的准确性和效率受限。
2、经检索发现,申请号为cn202311050735.0的中国发明专利,公开了一种基于深度学习的商品推荐系统以及方法,具体公开了如下内容:首先通过监听模块,实时获取主播的直播语音,进一步的通过意图识别模块,对直播语音的关键信息进行意图识别,得到识别结果,最后根据智能推荐神经网络确定直播语音对应的推荐内容。但是上述专利存在的问题有:第一、系统在确定直播间商品售卖调度顺序时,仍然依赖于主播的个人判断,准确度和效率不高;第二、该系统未充分考虑到电商直播中社区互动的重要性,特别是忽视了观众与主播以及观众间互动对商品售卖顺序调整的影响。因此,如何提供一种多品类电商直播商品调度系统及其调度方法,以提高商品售卖顺序的调度效率和准确性,同时增强电商直播的社区互动感,成为一个重要的技术问题也是本领域技术人员亟需解决的问题。
技术实现思路
1、本发明的一个目的在于提出一种基于深度强化学习的直播商品实时调度系统及方法,本发明引入了深度强化学习与统计模型,通过对实时直播互动数据与历史销售数据进行分析,实现了直播过程中的多品类商品的实时调度。
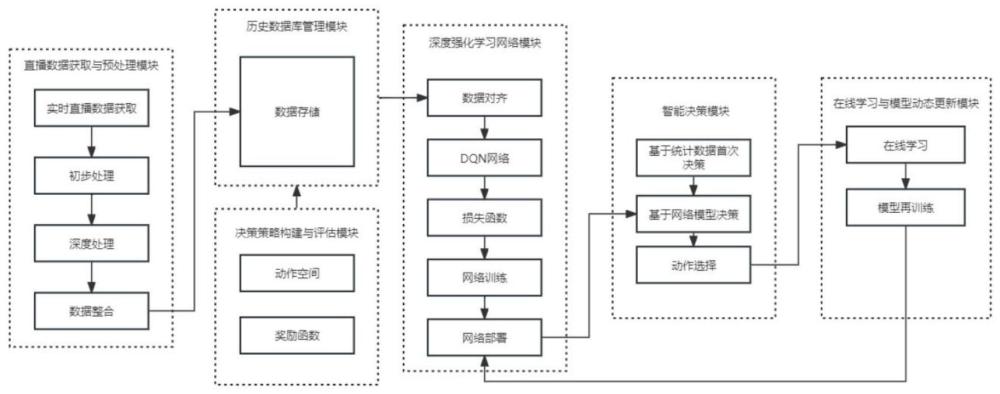
2、根据本发明实施例的一种基于深度强化学习的直播商品实时调度系统,包括
3、直播数据获取与预处理模块,用于实时数据采集和处理,提取互动与销售特征;
4、历史数据库管理模块,用于数据的存储和查询;
5、决策策略构建与评估模块,用于创建商品品类选择策略框架,并通过奖励机制评估策略效果;
6、深度强化学习网络模块,用于数据特征分析和策略优化;
7、智能决策模块,结合统计模型分析和强化学习网络模型输出,执行商品品类决策和动作选择;
8、在线学习与模型动态更新模块,用于响应市场变化,持续提升决策质量。
9、在上述方案的基础上,所述结合统计模型分析和强化学习网络模型输出具体包括:
10、统计模型,对历史直播销售数据进行分析,识别每个月销量最大的商品品类,并据此确定每月每天直播间首先售卖的商品;
11、深度强化学习网络模型,在直播过程中实时学习,对环境变化作出响应。并通过评估当前的销售环境和预测各商品品类的潜在销售效果,根据奖励函数指导下进行直播间商品售卖品类的调度。
12、一种基于深度强化学习的直播商品实时调度方法,包括如下方法步骤:
13、s1、通过直播平台的api接口,获取直播间的实时数据;
14、s2、对采集到的直播间实时数据执行初步处理操作,构建原始数据集;
15、s3、对原始数据集进行深度处理,所述深度处理包括直接特征提取、派生特征计算与文本数据深度特征提取;
16、s4、对深度处理后的原始数据集进行数据连接整合,并对整合后的数据集进行数据清洗、异常值处理、格式转换和归一化;
17、s5、对s4集中处理后的数据,所述处理后的数据包括每次单个商品的直播销售活动结束后,所产生的环境特征数据以及相应的时间戳,存储于历史数据库中;
18、s6、根据直播电商中商品品类的决策过程,进行动作编码并构建动作空间;
19、s7、根据s6动作编码结果,每次单个商品的直播销售过程中涉及的动作参数将被编码,并依据s5所述的环境特征数据及相应时间戳,统一存入历史数据库;
20、s8、设立奖励函数以衡量动作策略的效果,所述奖励函数包括即时奖励、延迟奖励与综合奖励;
21、s9、对应时间戳,将奖励值、环境特征数据与动作参数进行对齐,存储入历史数据库,同时,动作参数所产生的新的环境特征数据也记录在此条时间戳的历史数据库中;
22、s10、构建deep q-network模型网络;
23、s11、采用多重综合奖励时间差分误差值对s10中deep q-network模型添加损失函数;
24、s12、利用s9中历史数据库训练dqn网络;
25、s13、将s12训练好的dqn网络部署到直播间;
26、s14、构建历史销售数据统计模型,依据历史销售数据统计模型,确定每月每天直播间首先售卖的商品品类;
27、s15、利用训练好的deep q-network模型网络进行实际调度,网络输出在当前环境下价值最大化的行动策略,即直播间最应该推销的下一个商品品类;
28、s16、利用在线学习策略与即时奖励,对dqn网络模型进行实时更新与策略调整;
29、s17、对dqn网络模型进行再训练,奖励函数选择为综合奖励。
30、在上述方案的基础上,,所述s3中派生特征计算具体包括用户粘性指数与特定年龄段直播转换指数:
31、其中,派生特征计算中用户粘性指数表示为:
32、
33、其中,ρ为用户粘性指数,ne为某一品类商品结束售卖时留存的观众总数量,ni表示第i个时间戳数据对应的总观众数量,m表示商品展示售卖期间总记录的数据数目;
34、其中,派生特征计算中特定年龄段直播转换指数表示为:
35、
36、其中,σ为某一年龄段的购买率,s为该年龄段购买该商品品类的总数量,c为该年龄段在商品售卖期间某一时刻最多的观众总数量。
37、在上述方案的基础上,所述s5中环境特征数据包括当前商品售卖的品类、售卖期间观众点赞总数、观众性别比例、各年龄段人数与总人数的比例、观众间互动总次数、用户粘性指数、特定年龄段直播转换指数、积极与消极评论数量、与商品介绍关键词匹配的观众评论数量及主播与观众间有效互动总次数。
38、在上述方案的基础上,所述s6中动作编码具体表示为:
39、将下一个售卖商品调度为服装类别定义为动作1,美妆为动作2,电子产品为动作3,家居用品定义为动作4,食品和饮料为动作5,图书及教育材料为动作6,运动与户外多个领域为动作7。
40、在上述方案的基础上,所述s8中奖励函数包括即时奖励、延迟奖励与综合奖励:
41、其中,即时奖励表示为:
42、
43、其中,r1为即时奖励,vi-cur代表在直播过程中,切换到当前正在售卖的商品品类时,在第i个年龄段的观众中产生的转化指数,vi-pre代表在直播过程中,切换前一个品类的商品时,在第i个年龄段的观众中产生的转化指数,wi-cur为在第i个年龄段内,当前商品大类的一年销售额,wcur表示当前商品大类在所有年龄段的一年销售额;
44、其中,延迟奖励表示为:
45、r2=(br-ar)+pr;
46、其中,r2为延迟奖励,br为该调度商品品类的基准退货率,ar为该调度商品直播间售卖后反馈的实际退货率,pr为该调度商品直播间售卖后反馈的好评率;
47、其中,综合奖励表示为:
48、r3=r1+r2;
49、其中,r3为综合奖励,r1为即时奖励,r2为延迟奖励。
50、在上述方案的基础上,所述s11中采用多重综合奖励时间差分误差值对dqn网络模型添加损失函数:
51、其中,多重综合奖励时间差分误差值表示为:
52、
53、其中,lossw为多重综合奖励时间差分误差值,即dqn网络损失值,q*(st,a;w)为网络对当前状态和所有可能行动的q值的最大估计,maxaq*(st+3,a;w)为网络对3步后状态st+3所有可能行动的q值的最大估计,用就网络参数w计算。
54、在上述方案的基础上,所述s14中历史销售数据统计模型,该模型依据每月各直播间销售的各品类商品的总销售额进行统计分析,从而得出每个月各品类商品的累计销售总额。
55、在上述方案的基础上,所述每个月各品类商品的累计销售总额,将每月累计销售总额最高的品类作为当月每天直播间首先售卖的商品品类。
56、本发明的有益效果是:
57、本发明提供的系统和方法结合深度强化学习网络与统计模型,分析历史直播销售数据,并利用强化学习网络对直播过程中的环境状态进行最大化价值动作的决策。这种结合历史数据分析和实时决策的方法,使强化学习网络能够从高效率的起点开始,提高决策的精确度和响应速度。并且解决了传统方法在实时直播商品调度中实时响应不足和决策效率低下的问题,提高了商品调度策略的准确性和效率。
58、本发明的奖励机制采用即时奖励与综合奖励的双重设计,在常规训练阶段,系统主要采用综合奖励机制,以确保提高销售额的同时,提升好评率与降低退货率,而在模型的在线学习过程中,奖励则转向即时奖励机制,以快速适应市场的即时需求和变化。这种双重奖励机制的应用平衡了长期稳定性与实时响应性的需求,即确保了长期内持续优化业务性能,短期内提升市场竞争力。
59、本发明对直播间实时特征进行了充分的提取,包括观众评论及其时间戳、点赞总数、观众性别与年龄分布、观众间的@互动次数、主播语音,使用textblob数据库对观众评论即直播间总体氛围进行情感分析,并利用大型语言模型分析主播语音中的商品关键词,并与观众评论进行匹配,定量评估观众兴趣,系统还能通过大模型识别观众疑问句,分析主播与观众的互动频率,与传统特征相比,这些从直播间实时数据中提取的实时特征,能够更准确地指导销售策略,提升个性化直播间多品类商品调度的准确度。
60、本发明采用明确的模块化设计,并且直接从直播软件api接口提取数据,结合简易公式和大型模型对高阶特征进行提取,整体具备较快的计算速度并且易于搭建的特征。
61、本发明在调度多品类商品售卖方面,不同于传统方法那样主要依赖于规则和相似度计算,而是采用了强化学习网络进行商品调度和推荐。具备对数据不准确性有高度容错率的优势。
- 还没有人留言评论。精彩留言会获得点赞!