裁判文书摘要生成方法及系统、存储介质
本发明涉及摘要自动生成技术,特别是一种裁判文书摘要生成方法及系统、存储介质。
背景技术:
1、目前主流的文本摘要自动生成有三种方式,一种是抽取式(extractive),一种是生成式(abstractive),还有结合了前两种的混合式。抽取式摘要是按照一定权重,从原文中寻找跟中心思想最接近的一条或几条句子。抽取式摘要目前已经相对成熟,但抽取质量及内容流畅度均差强人意。生成式摘要是基于nlg技术,根据源文档内容,由算法模型自己生成自然语言描述,而非提取原文的句子,使用深度学习技术像人类一样解释和缩短原始文档。由于抽象机器学习算法可以生成代表源文本中最重要信息的新短语和句子,因此它们可以帮助克服基于抽取技术得到的摘要句内冗余高的问题。而混合式则结合了抽取和生成,先通过抽取的方式得到重要的候选句子,再对所有候选句子进行抽象摘要生成,混合式通过在抽象生成前以抽取技术对输入进行筛选,更好地适应了目前抽象生成模型对输入长度的限制,使得抽象生成模型在有限的文本内对更多重要的信息进行摘要概括。
2、然而将混合式抽象技术用于指导案例生成会存在关键信息丢失的问题。指导案例中的争议焦点部分在原文中可能只有两到三句话,并可能分散在不同段落中,若采取混合式摘要,在抽取式筛选环节很可能就会过滤掉这些低频且不集中但极为重要的句子。
3、目前以序列到序列预训练模型为主流的自然语言摘要生成相关研究更适用于在短文本的摘要生成,而不能有效地对案例长文本进行摘要生成。摘要生成领域的主流公开数据集为新闻,评论等短篇幅文本,本身语义较为集中,没有明显的结构,但重要信息往往在文本的首尾处,而司法案例不仅篇幅长,且不同国家不同案例类型有不同的总体编写结构,案例的重要信息会分布在案例的各处,且不同于新闻和评论的常见用语,案例中包含大量法律领域的专业术语。由于司法案例不同的篇幅,信息分布和词汇用语等特点,将目前主流的摘要技术直接用于案例无法得到令人满意的效果,不仅在输入时会发生截断,会丢失大量重要知识,且会出现oov问题,不准确问题。且这样生成出来的摘要,无法达到指导案例的结构要求。
4、生成符合既定结构的摘要文档的一种方式是先对原文按结构进行文意分段,在对各个文段进行摘要,有相关专利采用聚类的思想对司法文书进行了话题分割,使得到的文段具有话题上的连贯性。然而聚类方法仅适用于单一类型的文本,域外案例来自不同国家,案例格式各不相同,话题类别及分布也各不相同,除非针对各个国家的案例单独训练聚类模型,但这样的成本太高,且分开训练也会使各个模型能用于学习的数据量大幅下降,影响学习的性能。
技术实现思路
1、本发明所要解决的技术问题是,针对现有技术不足,提供一种裁判文书摘要生成方法及系统、存储介质,提高摘要文本表达的准确性。
2、为解决上述技术问题,本发明所采用的技术方案是:一种裁判文书摘要生成方法,包括以下步骤:
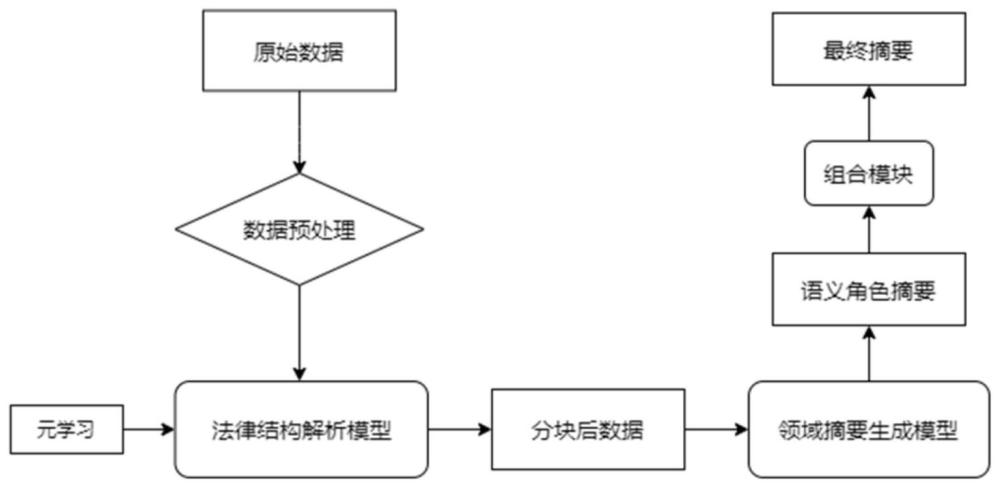
3、s1、对裁判文书进行数据清洗和分句处理,得到预处理后的裁判文书数据集;根据案例法律知识结构范式,分析裁判文书数据集,选取裁判文书中需要的法律结构角色类型;
4、s2、将选取的法律结构角色类型作为元学习测试任务的标签类型,采用元学习方法,利用所述预处理后的裁判文书数据集训练法律结构解析模型;
5、s3、利用训练后的法律结构解析模型对裁判文书进行结构解析,得到每个句子的法律结构角色类型;
6、s4、重组同一法律结构部分的语句,对重组后的各部分结构,以设定长度进行分块,得到多个文本块,为每个文本块附上对应的法律结构角色标签;
7、s5、将文本块输入经过领域数据微调的摘要生成模型,得到对应的摘要。
8、本发明能够自动对冗长的裁判文书进行指导性案例的生成,节省了人工编写方式的人力成本和时间成本。引入元学习,提出了序列标注形式的元学习任务数据集构造,通过在多任务上的训练使法律结构解析模型获得学习的能力,获得更优的初始参数,在有限的法律数据上通过较少次数的迭代即可获得较好的性能。本发明可以提高摘要生成结果的质量和准确性。
9、步骤s1中,对所述裁判文书进行分句处理时,添加以下规则:(?<!\w\.\w.)(?<![a-z]\.)(?<![a-z][a-z]\.)(?<![a-z]\.)(?<![a-z][a-z][a-z]\.)(?<=\.|\?|\!)\"*\s*\s*(?:\w*)([a-z]);[a-z]、[a-z]分别代表大、小写字母,\w代表字母数字或下划线,\w代表非除字母数字下划线外的其他字符;所述规则用来过滤缩略词,匹配以普通句号、问号、叹号和空格为标志的句子,标记出一个句子的开头。
10、所述法律结构角色类型包括:事实、下级法院的裁决、论点、法规、先例、判决理由和本院裁决。
11、所述法律结构解析模型包括依次连接的bert模型、bilstm模型和crf模型;所述bert模型的输入为预处理后的裁判文书数据的句子序列。
12、步骤s2中,所述法律结构解析模型的元学习训练过程包括:
13、1)将预处理后的裁判文书数据划分为多个子数据集,每个子数据集对应一个任务,任务包括训练任务和测试任务,将每个所述子数据集划分成支持集和查询集;
14、2)随机初始化法律结构解析模型参数θ,且所有任务对应的模型结构都和法律结构解析模型的结构相同;
15、3)对于第一个训练任务,将法律结构解析模型的参数赋给该任务对应的模型参数,在该任务的支持集上,基于任务对应的学习率αn优化该任务对应的模型,得到更新后的任务模型,基于更新后的任务模型参数,在该任务的查询集上计算该任务的损失,并计算该损失对更新后的任务模型参数的梯度,用该梯度乘以法律结构解析模型的学习率,得到更新后的法律结构解析模型的参数;
16、4)对于第二个训练任务,将第一个训练任务对应的更新后的法律结构解析模型的参数赋给该第二个训练任务对应的模型,重复步骤3);依此类推,直至最后一个训练任务训练完成,得到最终的法律结构解析模型参数;
17、5)对于最终的法律结构解析模型参数,用测试任务的子数据集再对该参数进行微调,得到训练后的法律结构解析模型。
18、本发明还提供了一种裁判文书摘要生成系统,其包括存储器和至少一个处理器;存储器上存储有一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现本发明上述方法的步骤。
19、本发明还提供了一种计算机可读存储介质,其存储有程序;所述程序被配置为用于执行本发明上述方法的步骤。
20、与现有技术相比,本发明所具有的有益效果为:
21、(1)本发明能够自动对冗长的裁判文书进行指导性案例的生成,节省了人工编写方式的人力成本和时间成本。
22、(2)引入元学习,提出了序列标注形式的元学习任务数据集构造,通过在多任务上的训练使法律结构解析模型获得学习的能力,获得更优的初始参数,在有限的法律数据上通过较少次数的迭代即可获得较好的性能。
23、(3)将法律结构解析模型与摘要生成模型结合,既有利于根据文本语义将文书映射成指导性案例所需的结构范式,也便于后续摘要模型在避免超出输入长度限制的同时,对含义更类同集中的文段进行摘要,提升摘要生成的质量。
24、(4)根据裁判文书的特点,对bart摘要生成模型进行了改进,加入copy模块,可通过固定词汇生成单词,也可以复制输入文本中的单词,使得裁判文书中一些低频但重要的词汇(如人名地名等)可以出现在生成的摘要中,提升摘要文本表达的准确性。
- 还没有人留言评论。精彩留言会获得点赞!