一种虚拟筛选深度学习模型的训练方法及系统
本技术实施例涉及深度学习,尤其涉及一种虚拟筛选深度学习模型的训练方法及系统。
背景技术:
1、深度学习方法被应用于诸多领域,药物研发中也可以采用深度学习的方法,该方法通过对药物的分子特征、作用机理等进行深入研究,构建一个药物预测模型,无需合成对应化合物就可以预测药物性质。而基于深度学习的药物研发方法较为核心的问题是如何从化学结构中学习分子特征。
2、对比学习是自监督学习领域中的一种主流方法,可以用于学习分子结构的相似性和差异性,从而预测分子的性质和药物作用的靶点。通过将对比学习与一维分子表示或二维分子表示结合来学习分子特征。
3、然而,仅使用一种模态的分子表示用于描述分子的分子身份和化学特征是有局限性的,无法更全面地学习到分子特征,降低模型的预测精度。
技术实现思路
1、本技术提供一种虚拟筛选深度学习模型的训练方法及系统,能够提高药物预测模型的精度。
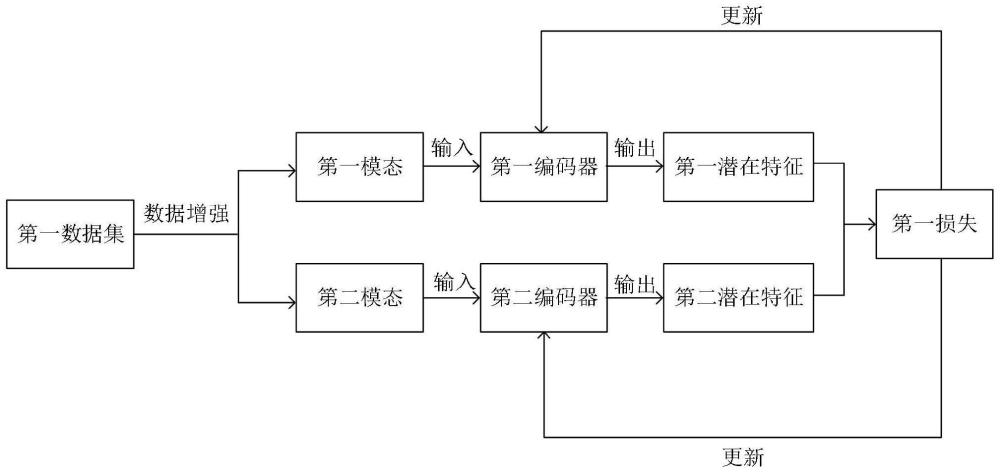
2、第一方面,本技术提供一种虚拟筛选深度学习模型的训练方法,包括:获取第一数据集,其中,第一数据集包括分子数据,所述分子数据包括第一模态和第二模态;将第一数据集输入虚拟筛选深度学习模型,其中,虚拟筛选深度学习模型包括第一编码器和第二编码器;通过虚拟筛选深度学习模型将第一数据集中的分子数据对应的第一模态输入第一编码器,得到第一潜在特征;并将第一数据集中的分子数据对应的第二模态输入第二编码器,得到第二潜在特征;根据第一潜在特征和第二潜在特征计算第一损失;根据第一损失更新第一编码器和第二编码器的模型参数。
3、上述方法中,虚拟筛选深度学习模型包括第一编码器和第二编码器,将数据集输入该模型中,数据集中的分子数据的第一模态输入第一编码器,第二模态输入第二编码器,第一编码器对分子数据的第一模态进行处理得到第一潜在特征,第二编码器对分子数据的第二模态进行处理得到第二潜在特征,根据第一潜在特征和第二潜在特征共同计算第一损失,可以得到更精确的第一损失用以更新第一编码器和第二编码器的模型参数,提高药物预测模型的精度,进而提高模型的有效性和可靠性。
4、在第一方面的一种可实现方式中,所述方法还包括获取第二数据集,第二数据集包括分子数据和标签数据,分子数据包括第一模态和第二模态,第二数据集被划分为训练集、验证集和测试集;为虚拟筛选深度学习模型添加第一分类器和第二分类器,第一分类器连接第一编码器的输出端;第二分类器连接第二编码器的输出端;将训练集输入虚拟筛选深度学习模型;通过虚拟筛选深度学习模型将训练集中分子数据对应的第一模态输入第一编码器,得到第一潜在特征,再将第一潜在特征输入第一分类器,得到第一逻辑值;将训练集中分子数据对应的第二模态输入第二编码器,得到第二潜在特征,再将第二潜在特征输入第二分类器,得到第二逻辑值;根据第一逻辑值、第二逻辑值和标签数据计算第二损失;根据第二损失更新第一编码器、第二编码器、第一分类器和第二分类器的模型参数。
5、上述方法中,在虚拟筛选深度学习模型中输入带有标签数据的第二数据集中的训练集数据,并且在第一编码器的输出之后添加第一分类器,在第二编码器的输出之后添加第二分类器,第一分类器可以根据输入的第一潜在特征输出第一逻辑值,第二分类器可以根据输入的第二潜在特征输出第二逻辑值,再根据第一逻辑值、第二逻辑值和标签数据共同计算出第二损失,根据第二损失更新第一编码器、第二编码器、第一分类器和第二分类器的模型参数,进一步提高模型的预测精度。
6、在第一方面的一种可实现方式中,所述方法还包括将所述验证集输入虚拟筛选深度学习模型;通过虚拟筛选深度学习模型将验证集中的分子数据对应的第一模态输入第一编码器,得到第一潜在特征,再将第一潜在特征输入第一分类器,得到第三逻辑值;将训练集中的分子数据对应的第二模态输入第二编码器,得到第二潜在特征,再将第二潜在特征输入第二分类器,得到第四逻辑值;根据第三逻辑值、第四逻辑值和标签数据计算第三损失;若第三损失大于预设阈值,根据第三损失更新第一编码器、第二编码器、第一分类器和第二分类器的模型参数。
7、上述方法中,通过验证集中的数据进一步更新模型参数,在虚拟筛选深度学习模型中输入带有标签数据的第二数据集中的验证集数据,数据经过第一编码器、第一分类器、第二编码器、第二分类器处理后,得到第三逻辑值和第四逻辑值,根据第三逻辑值和第四逻辑值计算出第三损失,再根据第三损失进一步更新第一编码器、第二编码器、第一分类器和第二分类器的模型参数,以验证虚拟筛选深度学习模型,并提高模型的精度。
8、在第一方面的一种可能实现方式中,所述方法还包括将测试集输入虚拟筛选深度学习模型;通过虚拟筛选深度学习模型将测试集中的分子数据对应的第一模态输入第一编码器,得到第一潜在特征,再将第一潜在特征输入第一分类器,得到第五逻辑值;将训练集中分子数据对应的第二模态输入第二编码器,得到第二潜在特征,再将第二潜在特征输入第二分类器,得到第六逻辑值;根据第五逻辑值和第六逻辑值计算预测结果。
9、上述方法中,在虚拟筛选深度学习模型中输入带有标签数据的第二数据集中的测试集数据,数据经过第一编码器、第一分类器、第二编码器、第二分类器处理后,得到第五逻辑值和第六逻辑值,根据第五逻辑值和第六逻辑值计算出模型预测的结果,用以检验模型的精度。
10、在第一方面的一种可实现方式中,第二数据集中训练集、验证集和测试集的比例为8:1:1。
11、将第二数据集中的数据数量按照8:1:1划分为训练接、验证集和测试集,既可以保证模型得到充分的训练,又可以验证模型的精度。
12、在第一方面的一种可实现方式中,第一数据集为无标签数据集。
13、由于虚拟筛选深度学习模型在预训练阶段需要大量数据作为支撑,标签数据数据量小无法满足条件,因此在预训练阶段选用无标签数据集,并采用对比学习的方式对虚拟筛选深度学习模型进行预训练。
14、在第一方面的一种可实现方式中,第一模态包括分子数据的简短有机分子结构式,第二模态包括分子数据的分子图像,对分子数据的简短有机分子结构式进行数据增强,进而获得分子数据的分子图像。
15、上述方法中,分子数据包括第一模态和第二模态两种不同的形式,可以使虚拟筛选深度学习模型更全面地学习到分子特征,提升模型的预测精度。
16、在第一方面的一种可实现方式中,第一编码器包括双向长短期记忆网络,第二编码器包括深度残差神经网络。
17、双向长短期记忆网络可以对分子数据的第一模态进行处理,以得到分子数据的第一潜在特征;深度残差神经网络可以对分子数据的第二模态进行处理,以得到分子数据的第二潜在特征。
18、在第一方面的一种可实现方式中,还可以在第一模态输入到第一编码器时,对分子数据的简短有机分子结构式进行枚举,以使虚拟筛选深度学习模型学习到简短有机分子结构式的所有表示;并且在第二模态输入到第二编码器时,对分子数据的分子图像进行随机水平翻转和随机旋转,得到变换后的分子图像。
19、上述方法中,对分子数据的第一模态和第二模态分别进行数据增强处理,便于寻找分子数据不同模态间的关联与差异,增加对比学习的准确度,提升模型的预测精度。
20、第二方面,提供一种虚拟筛选深度学习模型的训练系统,包括:数据获取单元、数据输入单元、特征生成单元、损失计算单元和参数更新单元,
21、其中,数据获取单元用于获取第一数据集,第一数据集包括分子数据,分子数据包括第一模态和第二模态;数据输入单元用于将第一数据集输入虚拟筛选深度学习模型,虚拟筛选深度学习模型包括第一编码器和第二编码器;特征生成单元用于通过虚拟筛选深度学习模型将第一数据集中的分子数据对应的第一模态输入第一编码器,得到第一潜在特征;并将第一数据集中分子数据对应的第二模态输入第二编码器,得到第二潜在特征;损失计算单元用于根据第一潜在特征和第二潜在特征计算第一损失;参数更新单元用于根据第一损失更新第一编码器和第二编码器的模型参数。
22、可以理解的是,上述提供的第二方面所述的系统所能达到的有益效果,可参考第一方面的有益效果,此处不再赘述。
23、由以上技术方案可知,本技术提供一种虚拟筛选深度学习模型的训练方法及系统,方法包括:获取第一数据集,第一数据集包括分子数据,分子数据包括第一模态和第二模态;将第一数据集输入虚拟筛选深度学习模型,虚拟筛选深度学习模型包括第一编码器和第二编码器;通过虚拟筛选深度学习模型将分子数据对应的第一模态输入第一编码器,得到第一潜在特征;将分子数据对应的第二模态输入第二编码器,得到第二潜在特征;根据第一潜在特征和第二潜在特征计算第一损失;根据第一损失更新第一编码器和第二编码器的模型参数;上述方法中,根据第一潜在特征和第二潜在特征共同计算第一损失,可以得到更精确的第一损失用以更新第一编码器和第二编码器的模型参数,提高药物预测模型的精度。
- 还没有人留言评论。精彩留言会获得点赞!