一种基于检索增强大语言模型的纠纷化解智能问答系统的制作方法
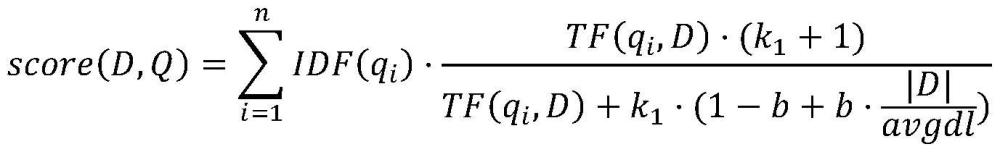
本发明涉及人工智能研究领域,具体涉及一种基于检索增强大语言模型的纠纷化解智能问答系统。
背景技术:
1、随着社会的发展,人们之间的矛盾纠纷日益增多,而目前矛盾纠纷的化解主要依赖于专业的调解专家进行,对于调解经验不足的工作人员和普通群众,在遇到矛盾纠纷时,并没有足够的专业知识去化解纠纷,这就导致了纠纷化解工作中经验丰富的调解专家的供需失衡。为了缓解这种失衡,工作人员在纠纷化解工作中引入了智能问答系统,帮助工作人员和普通群众提供纠纷化解建议。
2、目前在纠纷化解工作中引入的智能问答系统,主要是一种基于频繁问答对数据集构建的faq(frequently asked questions)问答系统。这种智能问答系统主要通过检索的方式从频繁问答对数据集中检索出与输入问题相似的候选问答对列表,再通过重排方式获取最相似的问答对,将该问答对的答案作为输入问答的答案返回。该技术主要存在以下两个问题:1、当表达方式与问答对中的问题差异较大时,检索的效果会很差。2、频繁问答对数据集的构建主要依赖纠纷化解领域专家人工构建,构建成本太大。
技术实现思路
1、为了克服现有技术的不足,本发明通过一种基于检索增强大语言模型的纠纷化解智能问答系统,在开源可商用的大语言模型基础上外挂纠纷化解领域的数据源来增强大语言模型对纠纷化解领域的专业问答能力。全程无需领域专家进行频繁问答对数据集的人工构建,而且由于使用了大语言模型,可以避免因表达方式差异导致系统表现较差的问题。技术方案如下:
2、一种基于检索增强大语言模型的纠纷化解智能问答系统,其构建基于如下步骤:
3、步骤1,基于数据采集技术,采集纠纷化解领域的法律法规、权责清单、案例经验等数据,构建纠纷化解知识库。
4、优选的,构建纠纷化解知识库具体方法如下:
5、步骤1.1,利用数据采集技术,从公开网站上采集纠纷化解领域的法律法规、权责清单、案例经验数据;
6、步骤1.2,对采集的数据进行清洗处理:进行对法律法规按照法条进行拆分、过滤掉已失效的法律法规、过滤掉没有处理意见的案例经验;
7、步骤1.3将清洗完的数据存储到本地数据库中。
8、优选的,本地数据库选用es,选择ik分词器作为分词器插件,创建索引时使用ik分词器的ik_max_word模式,对文本进行最细粒度的分词;搜索时使用ik分词器的ik_smart模式,对文本进行最粗粒度的分词,在es中添加构建好的自定义词典、同义词和停用词词典。
9、优选的,在构建完初始的纠纷化解知识库后,定期拉取新数据,实现对纠纷化解知识库的更新。
10、步骤2,基于文本向量化技术,将纠纷化解知识库中的数据进行向量化,构建纠纷化解知识向量库。
11、优选的,构建纠纷化解知识向量库的具体步骤如下:
12、步骤2.1,对所述纠纷化解知识库中的文本进行分段处理:
13、对于法律法规数据,按照法条进行拆分,每一个法条当作一段数据;
14、对于权责清单数据,按照模板对每一条权责清单中的多个字段进行组合以后当作一段数据,模板如下:“{权责清单字段}的责任单位是{责任单位字段},设立的法律依据为{法律依据字段}”;
15、对于案例经验数据,按照模板对每一条案例经验中的多个字段进行组合以后当作一段数据,模板如下:“{案例内容字段}的处理意见如下:{处理意见字段}”。
16、步骤2.2,将分段处理的后的数据使用文本嵌入模型进行文本向量化。
17、步骤2.3,将文本嵌入模型输出的向量存储到向量数据库中。
18、优选的,文本嵌入模型选用text2vec-base-chines;向量数据库选用faiss,选择ivfpq作为搜索索引。
19、步骤3,基于所述纠纷化解知识库和所述纠纷化解知识向量库检索输入问题的相关纠纷化解知识,具体如下:
20、步骤3.1,使用ik_smart模式的ik分词器对输入问题进行分词处理,得到分词结果q,包含关键词q1,q2,…,qn;
21、步骤3.2,从所述纠纷化解知识库中检索出包含q中任一关键词的文档d,并通过如下算法公式计算文档的相关性得分:
22、
23、其中,q表示分词结果,q1,q2,…,qn表示q中包含的关键词;
24、idf(qi)表示逆文档频率,算法公式如下:n表示所有文档数量,n(qi)表示包含qi的文档数量,ln函数是自然对数;
25、tf(qi,d)表示词频,算法公式如下:|d|表示文档d包含的词语数量,d(qi)表示文档d包含的词语中qi出现的次数;
26、avgdl表示所有文档包含的词语数量的平均值;
27、k1和b是两个超参数可调节变量,分别控制非线性词频归一化和文档长度对于分数的惩罚粒度。
28、优选的,k1和b分别为1.2和0.75。
29、步骤3.3,将从纠纷化解知识库(kd)中检索出的文档按照相关性得分进行排序,筛选出得分最高的k1个文档。
30、步骤3.4,从纠纷化解知识向量库(kvd)中检索出相似度得分最高的k2个文档,相似度得分算法公式如下:
31、
32、其中,
33、vec(d)表示文档d输入文本嵌入模型后输出的文本向量;
34、vec(q)表示问题输入文本嵌入模型后输出的文本向量;
35、|·|表示计算向量的模长;
36、步骤3.5,将从纠纷化解知识库中检索出来的文档的相关性得分与从纠纷化解知识向量库中检索出来的文档的相似度得分进行加权平均得到加权平均得分,对于缺少的相关性得分和相似度得分使用0分进行填充。
37、步骤3.6,将文档按照加权平均得分进行降序排列,选择最高的k3个文档,作为输入文档的相关纠纷化解知识。
38、优选的,k1值为10,k2值为10、k3值为5。
39、优选的,纠纷化解知识库中检索出来的文档的相关性得分与从纠纷化解知识向量库中检索出来的文档的相似度得分的加权权重为(0.5,0.5)。
40、步骤4,将输入问题和检索出来的相关纠纷化解知识按照提示模板生成提示内容,输入大语言模型后,输出回答。具体如下:
41、步骤4.1,将输入问题和检索出来的相关纠纷化解知识按照提示模板生成提示内容;
42、步骤4.2,将提示模板生成的提示内容输入到大语言模型中,得到输出结果;
43、步骤4.3,将输出结果作为输入问题的回答进行返回。
44、与现有技术相比,本发明的有益效果为:通过在外挂知识库中检索相关纠纷化解知识再和问题一起输入到大语言模型中,能够让大语言模型进行纠纷化解领域的专业智能问答。不再需要纠纷化解领域的专家人工构建频繁问答对数据集,而只需要通过数据采集技术自动化拉取相关知识,进行知识库更新,极大的减少了人工成本。
- 还没有人留言评论。精彩留言会获得点赞!