具有图像子图数量适应性的模因图配文生成方法及装置
本发明属于机器高阶认知领域,具体涉及一种具有图像子图数量适应性的模因图配文生成方法及装置。
背景技术:
1、幽默是人类的一种基本特征,深深植根于对语言、文化和社会规范的理解。对于机器来说,理解“幽默”的本质尤其具有挑战性。在追求更自然和富有同情心的人机交互中,使机器具备幽默感成为了一个关键的研究方向。值得注意的是,尽管自然语言处理(nlp)领域的幽默很有趣,但现实世界中的幽默通常在多模态框架中找到共鸣,结合视觉和文本元素。这在模因中得到了典型体现,模因源自希腊词“mimema”,并由理查德·道金斯在他1976年的书《自私的基因》中普及。模因不仅仅是互联网现象,它们还捕捉了时代的精神,反映了社会的观点,并成为当今流行文化的关键部分,特别是由于社交媒体的兴起。
2、目前,多模态幽默研究正在扩展。有工作探索了电视情景喜剧的对话,而有工作专注于“生活大爆炸”来进行幽默检测。还有工作分别提供了来自电视和模因的幽默数据集。有工作考虑了机器人互动中的笑声。有工作讨论了幽默理论。有工作展示了多模态幽默理解和标记的模型。有工作深入研究了电视节目中的幽默和情感。关于幽默生成,有工作专注于机器人幽默。在模因生成方面,有工作提供了模因的工具、数据集和系统。文本幽默生成旨在产生喜剧内容。模板通常涉及使用像wordnet这样的工具进行词汇变化,正如有工作在日本喜剧和其他工作在双关语中所展示的。然而,它们可能过于公式化。相反,神经模型则承诺更多的原创性。例如,有工作使用这类模型来创建双关语。
3、此外,目前研究较少探讨的一面是模因中的图像数量。单图像与多图像模因之间的区别可能具有重要意义。单图像模因将关键视觉信息与其文本对应部分相关联,而多图像模因则需要对图像间的关系以及相关文本进行细致理解,而这些都是现有方法所忽略的。
4、总之,现有技术对于不同模因图进行幽默文本即配文生成还存在较大的提升空间。
技术实现思路
1、本发明是为了解决上述问题而进行的,目的在于提供一种具有图像子图数量适应性的模因图配文生成方法及装置。
2、本发明提供了一种具有图像子图数量适应性的模因图配文生成方法,具有这样的特征,包括以下步骤:步骤s1,根据现有的多个模因图构建中文模因数据集,中文模因数据集包括多个图片和配文;步骤s2,根据中文模因数据集对现有的大语言模型进行训练,得到最终大语言模型和强化学习模型;步骤s3,将指定图像输入现有的多模态大模型,得到指定幽默链和指定图像特征;步骤s4,将指定幽默链和指定图像特征输入最终大语言模型,得到初始配文;步骤s5,将初始配文输入强化学习模型,得到最终配文,其中,步骤s2包括以下子步骤:步骤s2-1,根据多模态大模型,得到中文模因数据集中各个图片对应的幽默链和图像特征;步骤s2-2,根据幽默链和图像特征对大语言模型进行有监督微调,计算得到有监督微调损失;步骤s2-3,将中文模因数据集中的各个配文分别输入大语言模型,得到对应的文本特征;步骤s2-4,根据文本特征和图像特征进行自适应转换和注意力机制加强,计算得到先验损失;步骤s2-5,根据先验损失和有监督微调损失计算得到有监督学习总损失;步骤s2-6,根据有监督学习总损失更新大语言模型,得到训练好的大语言模型作为最终大语言模型;步骤s2-7,将中文模因数据集中各个图片对应的幽默链和指定图像特征分别输入最终大语言模型,得到对应的训练配文;步骤s2-8,根据所有训练配文和配文构建得到奖励模型;步骤s2-9,根据奖励模型和所有训练配文对最终大语言模型进行强化学习,得到强化学习模型。
3、在本发明提供的具有图像子图数量适应性的模因图配文生成方法中,还可以具有这样的特征:其中,模因图包括单图模因图和多图模因图,单图模因图包括仅含有一个子图像的图片和对应的一个配文,多图模因图包括含有多个子图像的图片和对应的一个配文。
4、在本发明提供的具有图像子图数量适应性的模因图配文生成方法中,还可以具有这样的特征:其中,在步骤s2-4中,先验损失的计算公式为:式中和为先验损失,ssft为大语言模型预测的图像与配文之间的相似度,si为基于先前知识计算出的图像与配文之间的相似度,为通过监督微调得到的图片i的第i个图像区域和图片i配文的第j个分词之间的相似度分数,为基于先前知识(如全局和词汇级相似性)计算出的图片i的第i个图像区域和图片i配文的第j个分词之间的相似度即分词级注意力,λg和λt为可训练的权重,kl为kl散度,si和分词级注意力的计算表达式为:式中和均为可训练的权重矩阵,和均为相应的偏置项,为图片i的第i个图像区域对应的图像特征,ti为图片i对应的配文的第j个分词对应的文本特征,wq和wk分别为自注意力机制中的查询的权重矩阵和键的权重矩阵,dk为键向量的维数,为归一化前的注意力得分,si,j为图片i的全局注意力,n为图片i中子图像的数量。
5、在本发明提供的具有图像子图数量适应性的模因图配文生成方法中,还可以具有这样的特征:其中,根据全局注意力和分词级注意力构建对比损失函数,用于最大化图片和相关的配文之间的相似度的同时,最小化图片和不相关的配文之间的相似度,对比损失函数的计算表达式为:式中τ为温度参数,li为图片i的第i个图像区域与图片i的配文的第j个分词之间的损失,n’是图片i的配文的分词数量
6、在本发明提供的具有图像子图数量适应性的模因图配文生成方法中,还可以具有这样的特征:其中,在步骤s2-5中,有监督学习总损失的计算表达式为:式中为有监督学习总损失,为有监督微调损失,λsft-ori、λt和λg分别为对应项的可训练的权重。
7、在本发明提供的具有图像子图数量适应性的模因图配文生成方法中,还可以具有这样的特征:其中,步骤s2-8包括以下子步骤:步骤s2-8-1,从所有训练配文中选取a%的训练配文,并进行评估排序,得到第一配文序列;步骤s2-8-2,将softmax层修改为线性层的现有大语言模型作为初始奖励模型;步骤s2-8-3,根据第一配文序列和配文,对初始奖励模型进行训练,计算得到第一损失lr;步骤s2-8-4,根据第一损失lr对初始奖励模型进行更新,得到奖励模型。
8、在本发明提供的具有图像子图数量适应性的模因图配文生成方法中,还可以具有这样的特征:其中,第一损失lr的计算表达式为:式中k为第一配文序列中训练配文的数量,x为配文,d为根据第一配文序列中的训练配文构建的排名对的集合,排名对包含排名较高的训练配文yw和排名较低的训练配文yl。
9、在本发明提供的具有图像子图数量适应性的模因图配文生成方法中,还可以具有这样的特征:其中,步骤s2-9包括以下子步骤:步骤s2-9-1,将最终大语言模型作为初始强化学习模型;步骤s2-9-2,将训练文本输入初始强化学习模型,得到对应的优化配文;步骤s2-9-3,根据训练文本和对应的优化配文,结合奖励模型,计算得到第二损失lrl;步骤s2-9-4,根据第二损失lrl对初始强化学习模型进行更新,得到训练好的初始强化学习模型作为强化学习模型。
10、在本发明提供的具有图像子图数量适应性的模因图配文生成方法中,还可以具有这样的特征:其中,第二损失lrl的计算表达式为:式中为初始强化学习模型生成的优化配文,πsft(y/x)为优化配文对应的训练配文,和均为可训练的权重,rθ(x,y)为奖励模型根据训练配文x和优化配文y计算得到的分数即奖励。
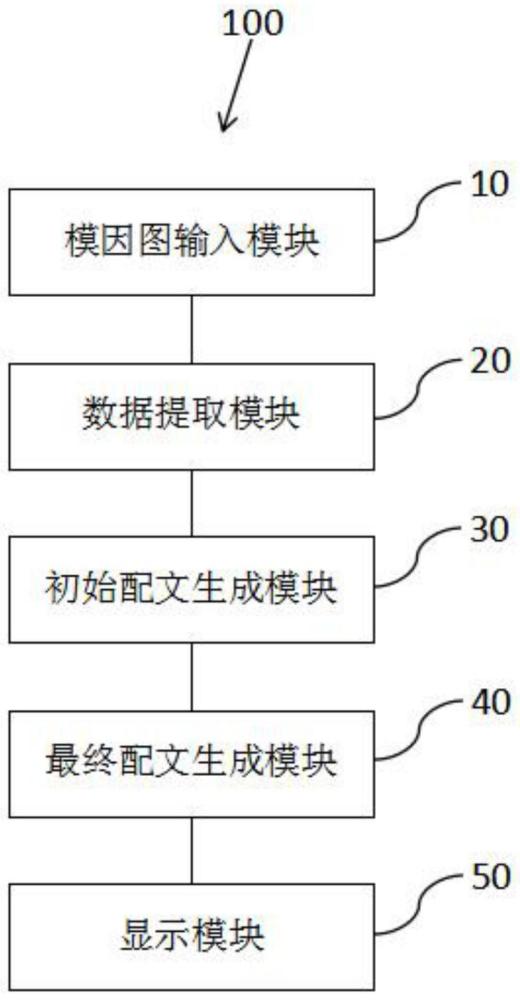
11、本发明还提供了一种具有图像子图数量适应性的模因图配文生成装置,用于对用户的指定图像生成对应的最终配文,具有这样的特征,包括:模因图输入模块,用于用户输入指定图像;数据提取模块,包含现有的多模态大模型,用于从指定图像中提取指定幽默链和指定图像特征;初始配文生成模块,包含最终大语言模型,用于根据指定幽默链和指定图像特征生成初始配文;最终配文生成模块,包含强化学习模型,用于根据初始配文生成最终配文,其中,最终大语言模型和强化学习模型由中文模因数据集对现有的大语言模型训练得到,中文模因数据集根据现有的多个模因图构建得到,包括多个图片和配文,最终大语言模型和强化学习模型的构建过程包括以下步骤:步骤s2-1,根据多模态大模型,得到中文模因数据集中各个图片对应的幽默链和图像特征;步骤s2-2,根据幽默链和图像特征对大语言模型进行有监督微调,计算得到有监督微调损失;步骤s2-3,将中文模因数据集中的各个配文分别输入大语言模型,得到对应的文本特征;步骤s2-4,根据文本特征和图像特征进行自适应转换和注意力机制加强,计算得到先验损失;步骤s2-5,根据先验损失和有监督微调损失计算得到有监督学习总损失;步骤s2-6,根据有监督学习总损失更新大语言模型,得到训练好的大语言模型作为最终大语言模型;步骤s2-7,将中文模因数据集中各个图片对应的幽默链和指定图像特征分别输入最终大语言模型,得到对应的训练配文;步骤s2-8,根据所有训练配文和配文构建得到奖励模型;步骤s2-9,根据奖励模型和所有训练配文对最终大语言模型进行强化学习,得到强化学习模型。
12、发明的作用与效果
13、根据本发明所涉及的具有图像子图数量适应性的模因图配文生成方法及装置,因为对大语言模型进行监督微调和强化学习时,通过全局注意力和分词级注意力考虑视觉和文本之间的全局和局部相似性,并结合通过排名对训练得到的奖励模型,得到最终大语言模型和强化学习模型,从而对指定图像生成具有幽默感的最终配文。所以,本发明的具有图像子图数量适应性的模因图配文生成方法及装置能够生成更匹配模因图的幽默配文。
- 还没有人留言评论。精彩留言会获得点赞!