对话生成方法、装置、设备及计算机可读介质与流程
本发明的实施方式涉及大语言模型,更具体地,本发明的实施方式涉及一种对话生成方法、装置、设备及计算机可读介质。
背景技术:
1、本部分旨在为权利要求书中陈述的本发明的实施方式提供背景或上下文。此处的描述不因为包括在本部分中就承认是现有技术。
2、在现实的学习环境中,特别是对于语文学习来说,对话练习被认为是提升学生表达能力、逻辑思维能力以及语感的有效方式。然而,由于各种现实条件的限制,学生往往难以获得充足的对话场景,他们难以独立且快速地启动对话训练,尤其对于学生喜爱的卡通形象,学生难以与卡通形象自由对话,这无疑对学习效果产生了负面影响。
技术实现思路
1、在本上下文中,本发明的实施方式期望提供一种对话生成方法、装置、设备及计算机可读介质,以解决学生难以与卡通形象自由对话的技术问题。
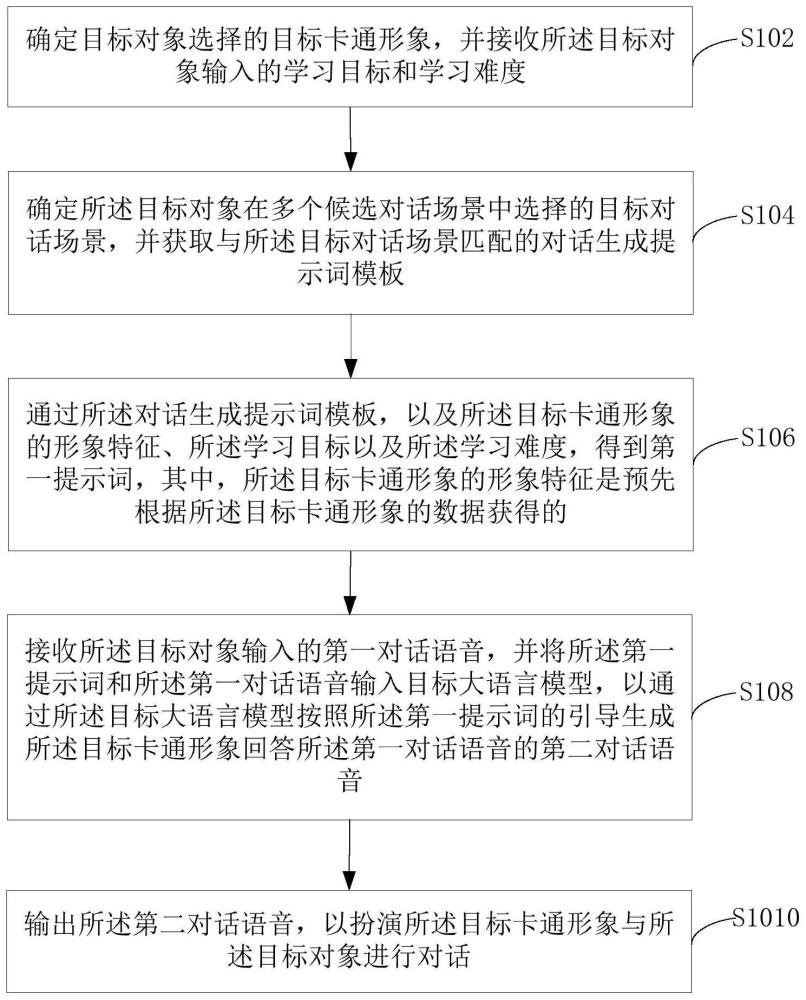
2、在本发明实施方式的第一方面中,提供了一种对话生成方法,包括:确定目标对象选择的目标卡通形象,并接收所述目标对象输入的学习目标和学习难度;确定所述目标对象在多个候选对话场景中选择的目标对话场景,并获取与所述目标对话场景匹配的对话生成提示词模板;通过所述对话生成提示词模板,以及所述目标卡通形象的形象特征、所述学习目标以及所述学习难度,得到第一提示词,其中,所述目标卡通形象的形象特征是预先根据所述目标卡通形象的数据获得的;接收所述目标对象输入的第一对话语音,并将所述第一提示词和所述第一对话语音输入目标大语言模型,以通过所述目标大语言模型按照所述第一提示词的引导生成所述目标卡通形象回答所述第一对话语音的第二对话语音;输出所述第二对话语音,以扮演所述目标卡通形象与所述目标对象进行对话。
3、在本发明的一个可选的实施例中,所述将所述第一提示词和所述第一对话语音输入目标大语言模型之前,所述方法还包括按照如下方式获取所述目标大语言模型:获取所述目标对象的教研信息和所述目标卡通形象的图文信息;将所述目标对象的教研信息和所述目标卡通形象的图文信息转换为结构化的知识数据;将所述知识数据划分为训练集和验证集;利用所述训练集对通用大语言模型进行训练,以更新所述通用大语言模型的模型参数;利用所述验证集验证所述通用大语言模型的训练结果;在验证结果指示所述通用大语言模型的回答准确率达到目标阈值时,保存当前的所述模型参数,得到具备所述知识数据的所述目标大语言模型。
4、在本发明的一个可选的实施例中,所述方法还包括按照如下方式获取所述目标卡通形象的形象特征:获取对所述目标卡通形象进行性格分析的第二提示词和对所述目标卡通形象进行语言风格分析的第三提示词;分别将所述第二提示词和所述第三提示词输入所述目标大语言模型,以引导所述目标大语言模型分析并总结出所述目标卡通形象的性格特征和语言风格特征作为所述目标卡通形象的形象特征。
5、在本发明的一个可选的实施例中,所述确定所述目标对象在多个候选对话场景中选择的目标对话场景之前,所述方法还包括:展示与所述学习目标和所述学习难度均匹配的多个候选对话场景。
6、在本发明的一个可选的实施例中,所述展示与所述学习目标和所述学习难度均匹配的候选对话场景之前,所述方法还包括按照如下方式从多个预先生成的对话场景中确定所述候选对话场景:根据当前登录账号的账号信息确定所述目标对象的年龄;根据所述学习目标和所述目标对象的年龄在多个预先生成的对话场景中确定适合所述目标对象且符合所述学习目标的第一候选场景;在所述第一候选场景中确定与所述学习难度匹配的第二候选场景;将所述第二候选场景确定为需展示的所述候选对话场景。
7、在本发明的一个可选的实施例中,所述从多个预先生成的对话场景中确定所述候选对话场景之前,所述方法还包括按照如下方式预先生成多个对话场景:基于多个预设对话场景类别和多个预设学习目标,引导所述目标大语言模型生成与所述预设对话场景类别和所述预设学习目标匹配的多个对话场景和对应的对话目标,并为每个对话场景设定适用年龄以及对话难度;基于所述对话场景、所述对话目标、所述适用年龄以及所述对话难度,引导所述目标大语言模型来生成不同年龄、不同对话难度下符合所述对话场景和所述对话目标的对话信息;根据所述对话信息调整所述对话场景的适用年龄和对话难度;保存所述对话场景、所述对话目标以及最终为所述对话场景设定的所述适用年龄和所述对话难度。
8、在本发明的一个可选的实施例中,所述基于多个预设对话场景类别和多个预设学习目标,引导所述目标大语言模型生成与所述预设对话场景类别和所述预设学习目标匹配的多个对话场景和对应的对话目标,并为每个对话场景设定适用年龄以及对话难度包括:将多个所述预设对话场景类别和多个所述预设学习目标分别填入预设的场景生成提示词模板,得到第四提示词,其中,所述场景生成提示词模板还预先设定了以所述对话场景、所述对话目标、所述适用年龄以及所述对话难度为输出;将所述第四提示词输入所述目标大语言模型,以使所述目标大语言模型按照所述预设对话场景类别和所述预设学习目标生成多个所述对话场景,并为每个所述对话场景设定所述对话目标、所述适用年龄以及所述对话难度。
9、在本发明的一个可选的实施例中,所述基于所述对话场景、所述对话目标、所述适用年龄以及所述对话难度,引导所述目标大语言模型来生成不同年龄、不同对话难度下符合所述对话场景和所述对话目标的对话信息包括:将所述对话场景、所述对话目标、所述适用年龄以及所述对话难度分别填入预设的对话训练提示词模板,得到第五提示词;将所述第五提示词输入所述目标大语言模型,以使所述目标大语言模型来生成不同年龄、不同对话难度下符合所述对话场景和所述对话目标的对话信息。
10、在本发明的一个可选的实施例中,所述目标卡通形象的形象特征包括目标卡通形象的名称、性格特征以及语言风格特征,所述对话生成提示词模板包括角色设定模块和任务目标模块,其中:所述角色设定模块用于根据目标卡通形象的名称、性格特征以及语言风格特征设定所述目标大语言模型扮演的卡通形象;所述任务目标模块用于设定所述目标大语言模型以输出与所述目标对象的属性信息相适配的对话为输出任务。
11、在本发明的一个可选的实施例中,所述对话生成提示词模板还包括实现步骤模块和输出格式限制模块二者至少之一,其中:所述实现步骤模块用于根据所述学习目标、学习难度和属性信息,设定从获取所述候选对话场景、确定所述目标对象选择的所述目标对话场景,直至设定所述目标大语言模型扮演所述目标卡通形象在所述目标对话场景下与所述目标对象对话的执行步骤;所述输出格式限制模块用于限制所述目标大语言模型的输出格式。
12、在本发明的一个可选的实施例中,所述输出所述第二对话语音之后,所述方法还包括:在检测到目标对象触发对话记录按钮时,展示扮演所述目标卡通形象与所述目标对象进行互动的对话记录。
13、在本发明实施方式的第二方面中,提供了一种对话生成装置,包括:形象设置及参数接收模块,用于确定目标对象选择的目标卡通形象,并接收所述目标对象输入的学习目标和学习难度;场景确定及模板获取模块,用于确定所述目标对象在多个候选对话场景中选择的目标对话场景,并获取与所述目标对话场景匹配的对话生成提示词模板;对话生成提示词获取模块,用于通过所述对话生成提示词模板,以及所述目标卡通形象的形象特征、所述学习目标以及所述学习难度,得到第一提示词,其中,所述目标卡通形象的形象特征是预先根据所述目标卡通形象的数据获得的;语音接收及对话生成模块,用于接收所述目标对象输入的第一对话语音,并将所述第一提示词和所述第一对话语音输入目标大语言模型,以通过所述目标大语言模型按照所述第一提示词的引导生成所述目标卡通形象回答所述第一对话语音的第二对话语音;对话输出模块,用于输出所述第二对话语音,以扮演所述目标卡通形象与所述目标对象进行对话。
14、在本发明实施方式的第三方面中,提供了一种电子设备,包括存储器、处理器、通信接口及通信总线,存储器中存储有可在处理器上运行的计算机程序,存储器、处理器通过通信总线和通信接口进行通信,处理器执行计算机程序时实现上述方法的步骤,
15、在本发明实施方式的第四方面中,提供了一种具有处理器可执行的非易失的程序代码的计算机可读介质,程序代码使处理器执行上述的方法。
16、本发明提供了一种对话生成方法,包括:确定目标对象选择的目标卡通形象,并接收所述目标对象输入的学习目标和学习难度;确定所述目标对象在多个候选对话场景中选择的目标对话场景,并获取与所述目标对话场景匹配的对话生成提示词模板;通过所述对话生成提示词模板,以及所述目标卡通形象的形象特征、所述学习目标以及所述学习难度,得到第一提示词,其中,所述目标卡通形象的形象特征是预先根据所述目标卡通形象的数据获得的;接收所述目标对象输入的第一对话语音,并将所述第一提示词和所述第一对话语音输入目标大语言模型,以通过所述目标大语言模型按照所述第一提示词的引导生成所述目标卡通形象回答所述第一对话语音的第二对话语音;输出所述第二对话语音,以扮演所述目标卡通形象与所述目标对象进行对话。本发明通过提示词引导的方式,引导目标大语言模型按照提示词设定的卡通形象和对话场景生成目标卡通形象与用户交流互动的对话,解决学生难以与卡通形象自由对话的技术问题,提升语言学习的趣味性和学习效果。
- 还没有人留言评论。精彩留言会获得点赞!