本发明涉及一种虚拟客服生成方法,特别是一种基于人脸识别的数字人客服模拟方法及数字人客服系统。
背景技术:
1、目前的客服系统主要使用语音的呼叫中心技术,可以对接电话、传真、信函web、email、wap、短信、视频等多种方式,其中视频接入则是由客服人员以视频的方式直接面对客户。但由于真人面对客户的方式,对客服人员的样貌、表情、着装等要求较高,使其很难展示统一的企业形象。另一方面,视频通话的方式还容易受到客服人员的情绪影响,从而造成不必要的问题。
2、针对上述问题,目前有企业采用虚拟人物形象代替真人出镜的方式进行视频通话,具体如专利202010146975.0所示,通过摄像头和麦克风采集客服人员的语音、面部表情和嘴型动作,然后通过blendshape动画技术渲染出对应的虚拟人形象。但该虚拟人形象的缺陷在于,由于客服人员在交流时的嘴型变化幅度较大且变化速度较快,使得blendshape动画技术很难准确的根据视频图像渲染出高拟真度的嘴部动作,并容易因前后嘴部动作的变化幅度差异过大导致出现虚拟人物的不规则表情,影响其展示效果。
3、另一方面,由于lipsync动画插件的嘴部动作生成方式是通过分析客服人员的音频信号,提取出音频中的语音特征,再根据语音特征和嘴部运动的关系推算出对应的嘴部动作;导致若是采用lipsync动画插件来代替blendshape动画技术生成虚拟人物的嘴部动作,一方面会存在虚拟人物的嘴部动作与客服人员的真实口型互不对应的情况,从而造成拟真度的下降;另一方面当客服人员的语速较快且前后两个嘴部动作的变化幅度较大时,其虚拟人物的嘴部动作仍会因动画生成难度过大出现不规则表情或嘴部动作不流畅的问题,并造成对算力资源的过度占用。
4、因此,现有对客服人员虚拟人物的生成方式存在嘴部动作拟真度差、虚拟人物容易出现不规则表情的问题。
技术实现思路
1、本发明的目的在于,提供一种基于人脸识别的数字人客服模拟方法及数字人客服系统。它能够有效提高对虚拟人物的嘴部动作拟真度,并减少虚拟人物动画的不规则表情。
2、本发明的技术方案:基于人脸识别的数字人客服模拟方法,包括以下步骤:
3、①获取客服人员的视频信息并从视频信息中捕捉客服人员的面部动作和肢体动作,并生成相关的动作数据;
4、②采用blendshape算法将动作数据、虚拟人模型和预设的blendshape动画进行拟合,渲染出带有客服人员面部动作和肢体动作的虚拟人动画;
5、③将虚拟人动画与预设的数字场景进行结合,并加入客服人员的语音信息,形成完整的视频流;
6、④将视频流推送至用户端的应用程序。
7、前述的基于人脸识别的数字人客服模拟方法中,所述步骤①中客服人员的面部动作包括客服人员的眉毛动作、嘴部动作和眼睛动作。
8、前述的基于人脸识别的数字人客服模拟方法中,所述步骤②中虚拟人动画在渲染时,将动作数据、虚拟人模型和及对应的blendshape动画传输至服务器,并由服务器进行渲染生成虚拟人动画。
9、前述的基于人脸识别的数字人客服模拟方法中,所述客服人员的嘴部动作和blendshape动画在拟合时,由lipsync插件根据客服人员的语音信息获取客服人员的音频口型数据,并由深度学习模型获取客服人员的人脸口型数据,然后对音频口型数据和人脸口型数据进行拟合,计算出对应的blendshape嘴部动画,再将该blendshape嘴部动画与虚拟人模型进行拟合,生成带有嘴部动作的虚拟人动画。
10、前述的基于人脸识别的数字人客服模拟方法中,所述音频口型数据的获取方法包括以下步骤:
11、a1.通过lipsync插件的声学特征识别数据对元音和预设的blen dshape嘴部动画进行匹配,使每个元音分别对应一个blendshape嘴部动画;
12、a2.对预设的blendshape嘴部动画的口型开合度进行赋值,使每个blendshape嘴部动画均对应一个口型开合度数值;
13、a3.由lipsync插件对客服人员语音信息中的元音进行获取,并根据获取到的元音推算出对应的blendshape嘴部动画及其口型开合度数值,该口型开合度数值即为客服人员的音频口型数据。
14、前述的基于人脸识别的数字人客服模拟方法中,所述人脸口型数据的获取方法包括以下步骤:
15、b1.对不同人脸图像中的开口嘴型的口型开合度进行赋值,并基于人脸图像和口型开合度数值对深度学习模型进行训练,使得深度学习模型能够基于人脸图像中不同开口大小的嘴型推算出对应的口型开合度数值;
16、b2.对客服人员的视频信息进行分解获得客服人员的人脸图像,然后由深度学习模型对人脸图像中的人脸进行识别,得到该人脸图像的口型开合度数值,该型开合度数值即为客服人员的人脸口型数据。
17、前述的基于人脸识别的数字人客服模拟方法中,所述音频口型数据和人脸口型数据的拟合方法包括以下步骤:
18、c1.对预设的blendshape嘴部动画的口型开合度进行数值限定,使blendshape嘴部动画的口型大小随口型开合度的数值进行变化,且各blendshape嘴部动画的口型开合度数值均在拟合范围内;
19、c2.对音频口型数据和人脸口型数据进行拟合,得到口型开合度的拟合值;
20、c3.基于拟合值对预设的blendshape嘴部动画进行选取,选择口型开合度数值与拟合值相同的blendshape嘴部动画作为对应的blendshape嘴部动画。
21、前述的基于人脸识别的数字人客服模拟方法中,所述步骤c2中音频口型数据和人脸口型数据的拟合方法具体为:
22、当音频口型数据和人脸口型数据的口型开合度均在拟合范围内,则口型开合度的拟合值为音频口型数据和人脸口型数据的均值;
23、当音频口型数据和人脸口型数据中任一个的口型开合度在拟合范围内,则以口型开合度在拟合范围内的音频口型数据或人脸口型数据作为口型开合度的拟合值;
24、当音频口型数据和人脸口型数据的口型开合度均不在拟合范围内,则对比拟合范围的端值和音频口型数据、人脸口型数据之间的数值差异度,选择数值差异度更小的拟合范围的端值作为口型开合度的拟合值。
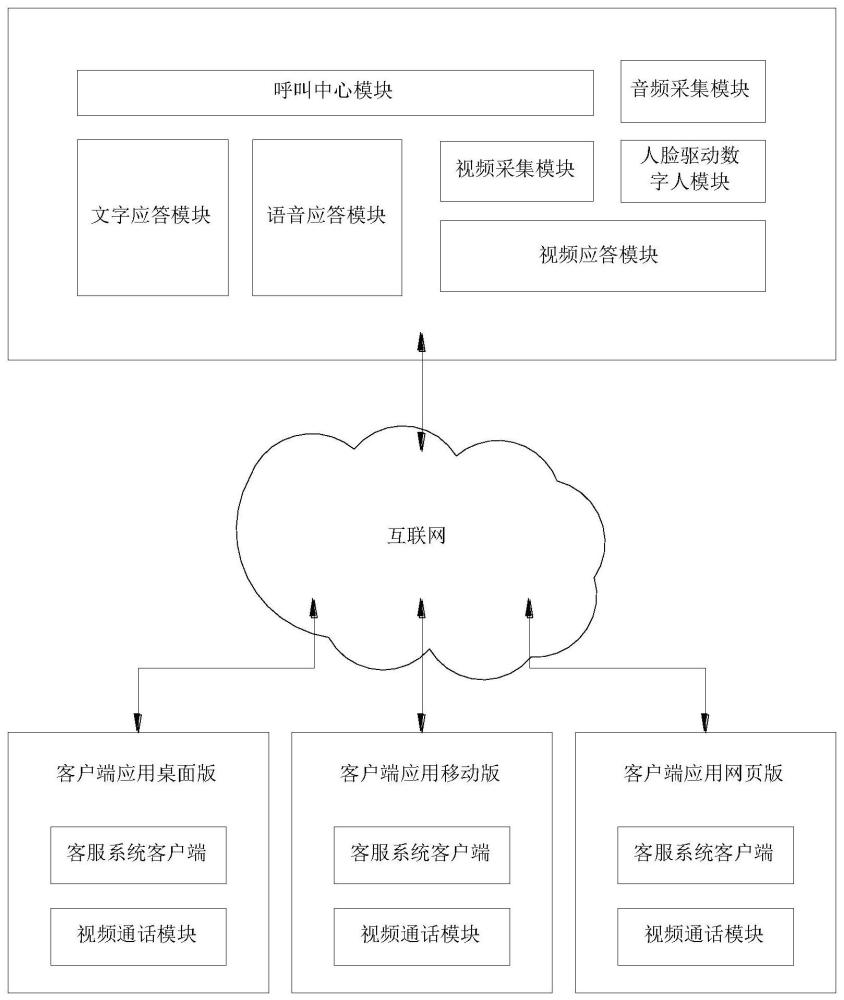
25、基于人脸识别的数字人客服系统,包括呼叫中心模块、文字应答模块、语音应答模块、视频应答模块、视频采集模块、音频采集模块和人脸识别驱动数字人模块;所述人脸识别驱动数字人模块包括人脸识别模块、数据通信模块、表情动作驱动模块、数字人渲染模块、视频推流模块和基础客服模块;
26、其中视频采集模块用于对客服人员的视频信息进行获取;
27、音频采集模块用于对客服人员的语音信息进行获取;
28、人脸识别模块用于对视频信息中的面部动作和肢体动作进行捕捉,生成相关的动作数据;
29、表情动作驱动模块用于对获取到的语音信息和动作数据进行分析和计算,从而获取到对应的blendshape动画;
30、数字人渲染模块用于将预设的虚拟人模型和blendshape动画进行拟合,渲染出带有客服人员面部表情的虚拟人动画;
31、视频推流模块用于对虚拟人动画、客服人员的语音信息和预设的数字场景进行结合,形成完整的视频流并推送至用户端的应用程序;数据通信模块用于连接服务器和外部应用程序。
32、与现有技术相比,本发明具有以下特点:
33、(1)本发明通过lipsync插件获取客服人员的音频口型数据,并由深度学习模型获取客服人员的人脸口型数据,使得blendshape算法在选择预设的blendshape嘴部动画时,能够对音频口型数据和人脸口型数据进行拟合,并根据拟合后的口型开合度数值对blendsh ape嘴部动画进行选取,从而获取到更趋近于客服人员嘴型的blend shape嘴部动画;在此基础上,通过对blendshape嘴部动画的口型开合度进行限定,则能够有效缩小两个blendshape嘴部动画之间的变化幅度,从而避免虚拟人物动画因嘴部动作变化过大造成的不规则表情,提高其展示效果和动画流畅度;
34、(2)通过对音频口型数据和人脸口型数据拟合方法的优化,则能够对客服人员的语音信息和视频信息进行结合,一方面提高对客服人员嘴型数据的获取稳定性,减少因客服人员嘴型变化过快或语速过快造成的嘴型数据获取不准确的情况,另一方面当两者获取的嘴型数据存均在偏差时,通过选择与音频口型数据和人脸口型数据差值更小的拟合范围的端值作为口型开合度的拟合值,则能够使选取的blend shape嘴部动画更趋近于客服人员真是的嘴型动作,并保证虚拟人物动画的流畅度和变化稳定性;
35、所以,本发明能够有效提高对虚拟人物的嘴部动作拟真度,并减少虚拟人物动画的不规则表情。