一种基于可穿戴设备的多模态情绪识别方法及系统
本发明涉及情绪识别领域,尤其涉及一种基于可穿戴设备的多模态情绪识别方法及系统。
背景技术:
1、随着人工智能和可穿戴设备技术的快速发展,多模态情绪识别成为了研究和应用的热点。这种技术在心理健康监测、人机交互、用户体验优化等多个领域发挥着关键作用。然而,传统的情绪识别方法,如单纯依赖面部表情分析或生理信号监测,往往在复杂情境下表现不佳,特别是难以处理微妙或隐蔽的情绪表达。对于特殊群体,例如自闭症谱系障碍(asd)患者,这种方法的效果尤其有限。此外,在处理情绪相关的复杂生理信号如eeg时,这些系统还面临着信号噪声和数据解析的挑战。
2、由于在各个领域中的巨大应用潜力,多模态情绪识别技术成为了活跃的研究课题。特别是在增强现实(ar)、虚拟现实(vr)以及日益兴起的元宇宙领域,这种技术展现出巨大的市场潜力。随着智能技术的普及和人们对沉浸式体验的追求,情绪识别被集成到ar/vr应用中,极大地提升了用户的互动体验。在这些沉浸式环境中,用户不仅仅关注虚拟世界的真实感和交互性,更期待这些技术能够理解和适应他们的情绪状态,从而提供更加个性化和富有同理心的体验。情绪识别技术在这些领域的应用,如在vr心理治疗、ar互动游戏,甚至是元宇宙的社交平台中,已经开始展现其改变游戏规则的潜力。
3、对于开发者和设计师而言,将多模态情绪识别技术融合进ar/vr应用中,不仅能够优化产品设计和提升用户体验,还能在更深层次上与用户建立连接。例如,在vr环境中,系统能够根据用户的情绪反应实时调整场景和互动元素,提供更加身临其境的体验。同样,在ar应用中,情绪识别可以帮助系统更好地理解用户的情绪状态,从而提供更加贴合用户情感需求的信息和服务。
4、公开号为cn114424940a的中国专利公开了“一种基于多模态时空特征融合的情绪识别方法” 通过预处理心电图、呼吸和眼动数据,使用cnn和lstm网络提取特征,融合这些特征进行情绪识别,但心电图主要反映心脏活动,即使结合呼吸和眼动数据,在更复杂的情绪识别环境如ar应用、asd患者情绪识别中,可能无法准确判断识别对象的微妙情绪表达。
5、因此,亟待设计一种基于可穿戴设备的多模态情绪识别方法及系统,解决上述现有技术存在的问题。
技术实现思路
1、本发明的目的在于提供一种基于可穿戴设备的多模态情绪识别方法及系统,旨在实现对用户情绪状态的综合判断,能够适用于各种情境下,更准确地识别和分析用户各种情绪状态。
2、为了实现上述目的,本发明采用了如下技术方案:
3、本发明第一方面提供了一种基于可穿戴设备的多模态情绪识别方法,所述方法包括以下步骤:
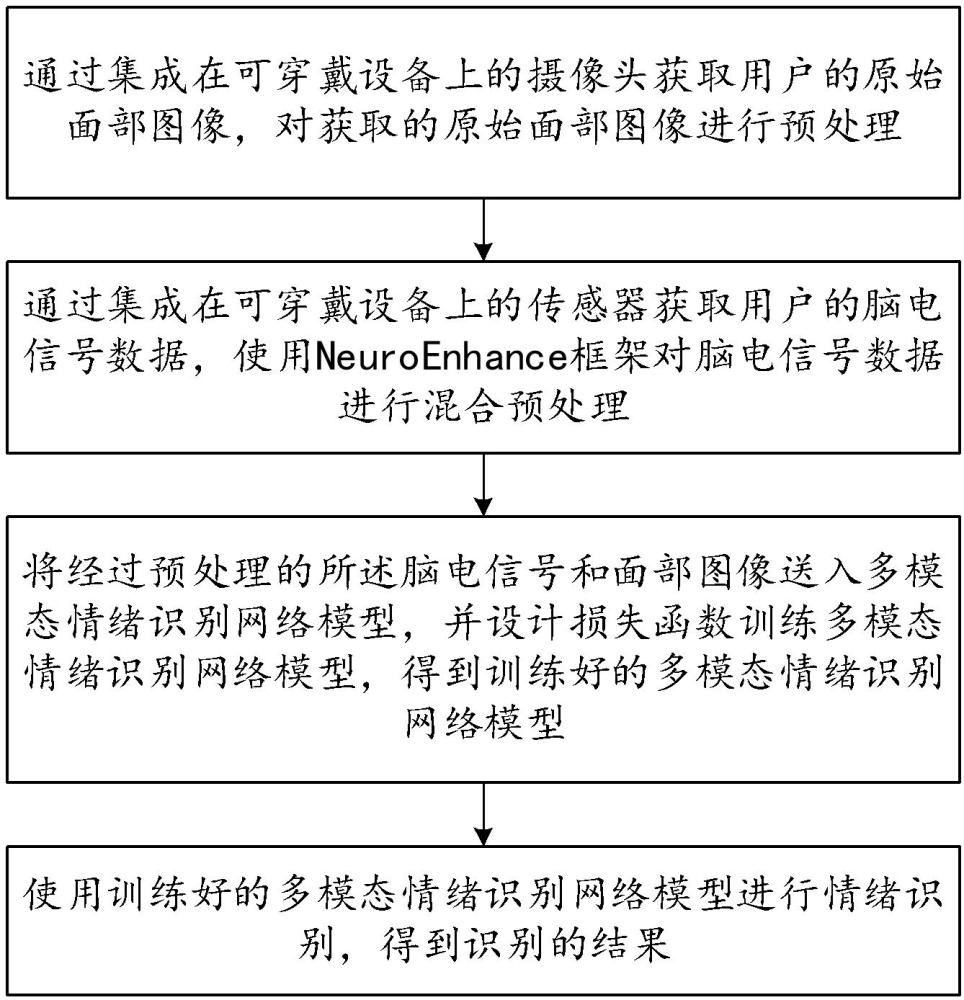
4、s1:通过集成在可穿戴设备上的摄像头获取用户的原始面部图像,对获取的原始面部图像进行预处理;
5、s2:通过集成在可穿戴设备上的传感器获取用户的脑电信号数据,使用neuroenhance框架对脑电信号数据进行混合预处理,所述neuroenhance框架包括信号处理和机器学习增强处理,其步骤具体包括:
6、s21:通过信号处理技术识别和剔除传入脑电信号的外源性伪迹,所述外源性伪迹包括环境噪声、操作误差和干扰;
7、s22:通过机器学习增强处理训练svm模型,针对脑电、肌电、眼电和心电信号进行分类,并剔除生理来源的内源性伪迹,所述内源性伪迹包括肌电、眼电和心电信号;
8、s3:将经过预处理的所述脑电信号和面部图像送入多模态情绪识别网络模型,并设计损失函数训练多模态情绪识别网络模型,得到训练好的多模态情绪识别网络模型;
9、所述多模态情绪识别网络模型包括脑电信号特征提取模块、面部图片特征提取模块、脑电信号与面部图片特征提取模块和多模态情绪识别模块;
10、s4:使用训练好的多模态情绪识别网络模型进行情绪识别,得到识别的结果。
11、作为本技术一实施例,所述步骤s21具体包括:
12、s211:使用带通滤波器去除脑电信号中的高频和低频噪声,保留4-30hz频率的脑电信号,其传递函数为:
13、
14、其中,是滤波器的频率响应,是信号的频率,和分别是滤波器的下限和上限截止频率,是滤波器的阶数;
15、s212:通过基线校正消除脑电信号中的直流偏移即长期的平均值,所述基线校正公式为:
16、
17、其中,是原始脑电信号,是经过基线校正的信号,是一个局部窗口内信号的平均值,这个窗口覆盖从时间点到的范围,其中是窗口的大小;
18、s213:通过归一化去除数据中的比例效应,其公式为:
19、
20、其中,是原始数据,是归一化后的数据,是数据中的最小值,是数据中的最大值,和是可调整的缩放因子和偏移量。
21、作为本技术一实施例,所述步骤s22具体包括:
22、s221:首先对采集的脑电、肌电、眼电和心电信号提取时域特征,首先提取每个脑电时域信号的均值、标准差、最大值、最小值,使用快速傅里叶变换得到对应的频域信号,并提取相关的频域信息,其计算公式为:
23、
24、
25、其中,是第个频率分量的幅度,是时域信号的第个样本,是样本总数,的模表示频率分量的幅度,表示频率分量的能量;所述肌电、眼电和心电信号均通过上述和脑电信号相同的操作得到对应的频率分量的能量、、;
26、s222:将脑电信号的时域和频域特征组合成一个特征向量,特征向量公式为:
27、
28、其中,是在fft处理后得到的不同频率分量的能量,所述肌电、眼电和心电信号均通过上述和脑电信号同样的操作构建相应的特征向量、和;
29、s223:设计一个综合损失函数,用于处理脑电信号数据中的不平衡性和噪声问题,所述综合损失函数包括铰链损失函数和l2正则化项,其计算公式如下:
30、
31、其中,是铰链损失函数,表示类别权重,是l2正则化项,表示模型权重向量的平方范数,是正则化强度参数;
32、s224:将所述脑电、肌电、眼电和心电的特征向量、、、输入到svm模型,进行信号识别与处理。
33、作为本技术一实施例,所述步骤s3中脑电信号特征提取模块具体包括:
34、s311:输入经过预处理的脑电信号,使用的卷积核进行时域特征提取,经过relu激活层后采用的卷积核进行频域特征提取,再次经过relu激活层;
35、s312:经过最大池化和平均池化,再使用深度可分离卷积层对每个输入通道进行空间上的卷积;
36、s313:引入自注意力机制,设置一个dropout层,加入一个全连接层,经过一个relu激活函数,再加入批量归一化层,输出脑电信号特征向量;所述自注意力机制计算公式如下:
37、
38、其中,表示应用了注意力机制后的特征图,为生理驱动的通道注意力,代表经过编码的脑电通道的生理意义的嵌入向量,和是学习得到的权重和偏置,是时间动态注意力,是时间序列特征,和是学习的得到的权重和偏置,和是自适应学习的权重系数,表示原始脑电特征图,其中表示逐元素乘法。
39、作为本技术一实施例,所述步骤s3中面部表情特征提取模块具体包括:
40、s321:输入经过预处理的面部图像,使用的卷积核进行初始卷积,经过relu激活函数后再使用的卷积核进行深层特征提取,再次经过relu激活函数;
41、s322:引入动态注意力机制,调整注意力权重,使用平均池化层来进一步减少参数数量;所述动态注意力机制计算公式如下:
42、
43、其中,是第个面部区域的局部特征;表示全连接层;是全局特征图,代表面部表情的整体特征;是第个区域的动态权重,由全连接网络计算得到,并通过函数确保权重在0到1之间;表示逐元素乘法;
44、s323:加入dropout层,经过全连接层,应用自适应激活函数,输出图像特征向量;所述自适应激活函数表示如下:
45、
46、其中,和是基于输入特征的统计特性的动态调整系数,,,,是可学习的参数,表示输入特征的标准差,表示输入特征的均值。
47、作为本技术一实施例,所述步骤s3中脑电信号与面部图片特征提取模块具体包括:
48、s331:输入经过预处理的脑电信号,使用的卷积核以捕捉频域特征;
49、s332:输入经过预处理的面部图像,使用的卷积核以提取空间特征;
50、s333:将经过不同卷积核的脑电信号和面部图片同时加入leakyrelu激活函数,再使用多头注意力机制进行融合,所述多头注意力机制计算公式如下:
51、
52、其中,表示第个注意力头的输出;为查询矩阵,为键矩阵,为值矩阵,表示键/查询向量的维度,是一个常数,用于避免分母为0的情况;
53、s334:设置dropout层并加入全连接层,使用pca降维技术来减少特征空间的维度;
54、s335:将经过pca降维后的数据输入lstm情感状态编码器并输出融合后的特征向量。
55、作为本技术一实施例,所述步骤s3中情绪识别模块具体包括:
56、s341:通过拼接操作将脑电信号特征提取模块、面部图片特征提取模块和脑电信号与面部图片特征提取模块的输出特征向量进行融合得到统一的特征向量;
57、s342:将统一的特征向量经过的卷积核进行初始卷积操作后经过relu激活函数,在应用的卷积核进行深度卷积后再次经过relu激活函数;
58、s343:经过最大池化和平均池化层后再经过relu激活函数,得到固定长度的特征向量;
59、s344:将固定长度的特征向量输入到全连接层,再经过dropout层,应用softmax激活函数得到情绪的分类结果。
60、作为本技术一实施例,所述步骤3中设计的损失函数计算公式如下:
61、
62、其中,为情感类别总数,是基于类别的历史分类准确率动态调整的权重,和分别表示第个情感类别的真实标签和模型的预测概率。
63、本技术还提供了一种基于可穿戴设备的多模态情绪识别系统,包括:
64、可穿戴设备,用于获取用户的原始面部图像和脑电信号数据;
65、图像处理模块,用于将获取到的用户的原始面部图像进行预处理;
66、信号处理模块,用于将获取到的用户的脑电信号进行预处理;
67、脑电信号特征提取模块,用于将经过信号处理模块的脑电信号数据进行特征提取,输出脑电信号特征向量;
68、面部图片特征提取模块,用于将经过图像处理模块的面部图像进行特征提取,输出图像特征向量;
69、脑电信号与面部图片特征提取模块,用于将经过信号处理模块的脑电信号和经过图像处理模块的面部图片提取相应的特征并进行融合,输出融合后的特征向量;
70、多模态情绪识别模块,将脑电信号特征提取模块、面部图片特征提取模块、脑电信号与面部图片特征提取模块的输出的特征向量进行融合,并应用softmax激活函数得到情绪的分类结果。
71、本发明的有益效果为:
72、(1)本发明通过对采集到的用户的面部图像和脑电信号进行预处理,将经过预处理后的面部图像和脑电信号送入多模态情绪识别网络模型进行特征提取,并设计损失函数对多模态情绪识别网络模型进行训练,训练好的多模态情绪识别网络模型能够更准确地识别和分析用户的各种情绪状态。
73、(2)本发明通过集成在可穿戴设备上的高分辨率摄像头实时捕捉用户的面部图像,通过集成在可穿戴设备上的传感器实时捕捉用户的脑电信号,同时采集用户的面部图像和脑电信号,将面部图像和脑电信号进行融合,相比传统的单一模态方法更为全面,能够捕捉更丰富的情绪相关信息。
74、(3)本发明通过使用neuroenhance框架对脑电信号数据进行混合预处理,neuroenhance框架结合了传统信号处理技术和现代机器学习增强处理方法,能够提取到更干净的脑电信号数据,提高多模态情绪识别网络模型的识别准确率。
75、(4)本发明通过脑电信号特征提取模块将脑电信号数据进行特征提取,面部图片特征提取模块将面部图像进行特征提取,脑电信号与面部图片特征提取模块将脑电信号和面部图像提取相应的特征并进行融合,本发明不仅融合了脑电信号和面部图像的单独特征,还创新性地将两者的交互信息编织进了多模态特征向量中,这种综合利用多模态数据的方法增强了多模态情绪识别网络模型对于复杂情绪状态的捕捉能力,显著提高了情绪识别的准确性和效率。
76、(5)本发明通过设计创新的损失函数,不仅关注常见的情感类别,而且对难以分类的情感状态给予额外的关注,进一步提高了多模态情绪识别网络模型在复杂情感分类任务中的准确性和敏感性。
- 还没有人留言评论。精彩留言会获得点赞!