图形处理器及其数据处理方法和包含其的电子设备与流程
本发明涉及图形处理,尤其涉及一种图形处理器及其数据处理方法和包含其的电子设备。
背景技术:
1、因为gpu(graphics processing unit,图形处理器或图形处理单元)对ddr(全称ddr sdram,double data rate synchronous dynamic random access memory,双倍数据速率同步动态随机存储器)的访问的延时是非常高的,高达几百个cycles(周期),因此gpu常常会将数据压缩后再写入内存或显存中,减少对内存或显存访问的带宽需求,以降低延时。由于是无损压缩,因此一般压缩后的长度是不固定的,解压缩时需要根据压缩长度来进行解压缩,需要另外分配一块内存来保存压缩长度。如图1所示,将左边的原始图像按照压缩粒度(compress granularity,cg)进行划分,每个cg在进行压缩后,得到的压缩数据一般可以按照ddr接口位宽进行对齐后存入内存中,并且每个cg的压缩长度(compress length,cl)也会存到内存中,如图1的右边图像所示。若gpu到ddr的接口位宽是m bit(binarydigit,比特),压缩粒度cg的具体大小可从多方面考量,但一般为m*2nbit,最少用nbit表示cl即可。以m=256bit、n=2为例,则cg尺寸为1024bit,cl可以为2bit,可用cl=1表示压缩后数据为256bit,如图1中的cg0;cl=2表示压缩后数据为2*256bit,如图1中的cg1;cl=3表示压缩后数据为3*256bit,如图中的cg2;若压缩后数据为4*256bit,和原始数据大小一样,则可用cl=0表示压缩失败,如图中的cg3。在gpu读数据cg0时,需要先读出cl0,根据cl0=1,从内存中读出256bit,再由com模块(compressors,压缩解压缩模块)进行解压缩,将解压缩后的数据回给gpu。仅从cg0来说,压缩后的数据量仅为原来的1/4,节省了3/4的带宽需求。需要注意的是,对于cl值和尺寸的设计可由压缩器设计者自行定义,本例中只是提供了一种简单的设计来便于解释cl的作用。
2、为了提高读写cl的效率,通常设计一个缓存(cache)来存放压缩长度,当第一次cache miss(缓存未命中)时,cache从ddr中读回一整条cacheline(缓存行),该cacheline包含多个cl。这样除了第一个压缩长度需要从ddr中读回cl,后面的cg访问,可在cache中命中,直接在cache中进行读写,节省了从内存中读压缩长度的时间。
3、com模块与gpu和ddr的连接图一般如图2所示,其中com模块表示压缩解压缩模块,cl cache为存放压缩长度的缓存。在gpu往ddr写数据时,先由com模块进行压缩,再将压缩后的数据写到ddr,压缩长度写到cl cache。在gpu从ddr读数据时,先从cl cache中读出压缩长度,根据压缩长度从ddr中读出压缩后数据,并进行解压缩得到原始数据,返回给gpu。
4、由于对ddr的访问存在固定的延时,即一个ddr在收到一个访问后,必须至少隔一段固定时间才能处理另一个访问,因此gpu对图像进行连续访问时,连续地址的访问往往访问不同的ddr中来隐藏固定延时。如图3所示,以4通道ddr为例,图像中连续的cg在ddr中的排放如图所示。gpu对cg0、cg1、cg2……的访问往往是连续的,则在t0时间将cg0送入ddr0,在t1时间将cg1送入ddr1,在t2时间将cg2送入ddr2,在t3时间将cg3送入ddr3,在t4时间再将cg4送入ddr0……则两次对ddr0的访问间隔了t4-t0时间,这可以隐藏ddr访问的固定延时。
5、当芯片(chip)较小时可将ddr放在一侧,此时采用集中的com模块和cl cache是没有问题的。但是对于多核心处理器,且芯片尺寸较大时,为了让每个核心(core)对ddr访问的距离都相对平衡,ddr需要分布在芯片四周。此时若仍采用集中的压缩解压缩模块和clcache,则会造成:ddr到压缩解压缩模块的距离变长,增加延时和功耗。
技术实现思路
1、本发明的目的之一是为了克服现有技术中的不足,针对现有技术中存在的在具有较大尺寸芯片的多核心gpu中ddr与压缩解压缩模块之间的距离长,增加延时和功耗问题,提供一种图形处理器及其数据处理方法和包含其的电子设备。
2、为实现以上目的,本发明通过以下技术方案实现:
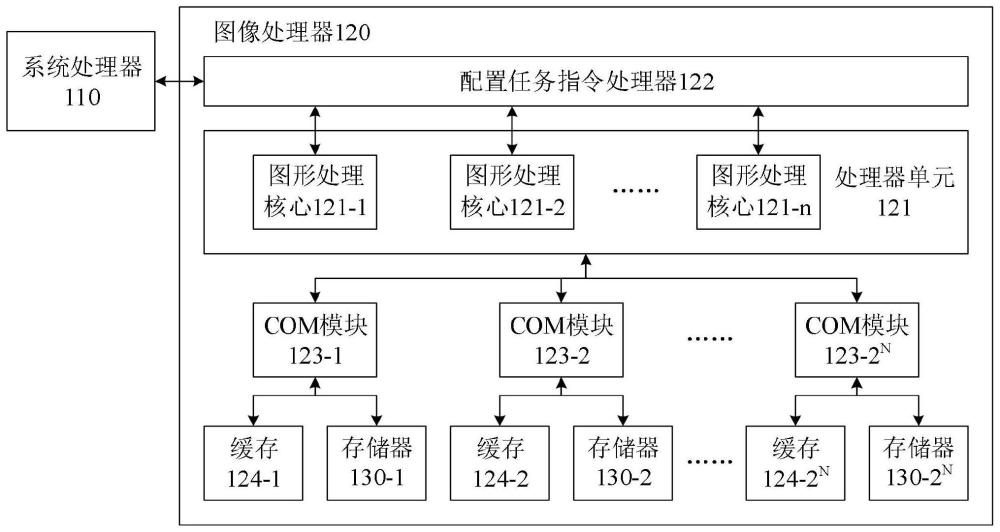
3、第一方面,本发明提供了一种图形处理器,包括处理器单元、多个存储器、多个压缩解压缩模块和多个缓存,所述处理器单元包括多个图形处理核心,第一图形处理核心为所述多个图形处理核心中的一个,每个所述压缩解压缩模块连接在所述处理器单元上并对应连接一个所述存储器和一个所述缓存;
4、所述第一图形处理核心用于生成第一访问请求并向各个所述压缩解压缩模块发出所述第一访问请求;
5、所述压缩解压缩模块用于向对应的缓存发送所述第一访问请求;
6、所述缓存用于对所述第一访问请求中的压缩粒度索引进行重映射,对所述压缩粒度索引中与所述缓存对应的所述存储器对应的压缩粒度对应的待请求的压缩长度进行重新排列,得到压缩长度地址;对所述压缩长度地址中与所述存储器对应的待请求的压缩长度进行命中测试,判断所述缓存中存储的缓存行中是否存在包含所述待请求的压缩长度的第一缓存行;
7、若所述命中测试的结果为未命中,则所述缓存从所述存储器中加载所述第一缓存行,并将所述缓存中任一替换缓存行作为替换存入所述存储器中;再根据所述第一访问请求的访问类型对所述待请求的压缩长度进行处理;
8、若所述命中测试的结果为命中,则所述缓存直接根据所述第一访问请求的访问类型对所述待请求的压缩长度进行处理。
9、在本技术的一个优选实施例中,所述第一访问请求的处理过程具体为:
10、所述第一图形处理核心根据任务指令选定待访问的多个存储器、确定访问所述多个存储器的访问顺序和分配每个所述存储器的访问类型;根据所述访问顺序对所述多个存储器各自对应的压缩粒度进行排列,并将排列后的压缩粒度与对应的压缩长度组成压缩粒度索引;根据所述访问类型进行第一处理;基于所述待访问的多个存储器、所述多个存储器的访问顺序、所述压缩粒度索引及各个所述存储器对应的所述访问类型和所述第一处理生成第一访问请求;根据所述访问顺序依次向所述多个存储器各自对应的压缩解压缩模块发出所述第一访问请求;
11、所述压缩解压缩模块根据所述第一处理执行第二处理;并向对应的缓存发出所述第一访问请求。
12、在本技术的一个优选实施例中,在所述访问类型为读请求时,所述第一处理为所述第一图形处理核心为所述存储器分配读取指令,所述第二处理为所述压缩解压缩模块从对应的缓存中读出待请求的压缩长度;在所述访问类型为写请求时,所述第一处理为所述第一图形处理核心为所述存储器分配输入数据,所述第二处理为所述压缩解压缩模块对所述输入数据进行压缩,得到压缩数据。
13、在本技术的一个优选实施例中,所述缓存的重映射过程具体为:
14、根据所述第一访问请求中待访问的存储器数量确定第一参数;
15、设置单个缓存行的大小、单个压缩长度的大小以及单个缓存行存放压缩长度的数量,确定第二参数;
16、根据所述处理器单元最大支持处理图像的大小和所述压缩粒度的大小得到每个压缩粒度最多需要的压缩粒度编码的大小,得到第三参数;
17、根据所述第一参数、所述第二参数和所述第三参数,对所述存储器待访问的各个压缩粒度对应的压缩粒度编码进行码位重排,得到各个压缩粒度的新地址编码;
18、将各个压缩粒度的新地址编码按照各个压缩粒度的顺序依次排序,形成压缩长度地址。
19、在本技术的一个优选实施例中,加载所述第一缓存行的具体过程为:
20、所述缓存选择给请求的第一缓存行腾出空间用作替换的替换缓存行;
21、所述缓存判断所述替换缓存行中各个压缩长度的数据是否被改写过;
22、若被改写过,则所述缓存将所述替换缓存行存储至所述存储器;再生成第二访问请求;
23、若未被改写过,则所述缓存生成第二访问请求,所述第二访问请求包括所述待请求的压缩长度;
24、所述缓存向对应的存储器发出所述第二访问请求;
25、所述存储器根据所述第二访问请求中所述待请求的压缩长度,找到包含所述待请求的压缩长度的第一缓存行;
26、所述存储器将所述第一缓存行发回给所述缓存,所述缓存存储所述第一缓存行。
27、在本技术的一个优选实施例中,所述缓存处理所述待请求的压缩长度的具体过程为:
28、所述缓存判断所述第一访问请求的访问类型;
29、若为读请求,则所述缓存从所述第一缓存行中读取所述待请求的压缩长度并发送给所述压缩解压缩模块;
30、若为写请求,则所述缓存将所述待请求的压缩长度写入所述第一缓存行中。
31、在本技术的一个优选实施例中,所述存储器均匀分布在所述处理器单元的周围,每个所述压缩解压缩模块分别连接在所述处理器单元的周围。
32、第二方面,本发明提供了一种图形处理器的数据处理方法,所述图形处理器包括处理器单元、多个存储器、多个压缩解压缩模块和多个缓存,所述处理器单元包括多个图形处理核心,第一图形处理核心为所述多个图形处理核心中的一个,每个所述压缩解压缩模块连接在所述处理器单元上并对应连接一个所述存储器和一个所述缓存;所述方法包括:
33、s10:所述缓存接收由所述第一图形处理核心向对应的所述压缩解压缩模块发出的第一访问请求;
34、s20:所述缓存对所述第一访问请求中的压缩粒度索引进行重映射,对所述压缩粒度索引中与所述缓存对应的所述存储器对应的压缩粒度对应的待请求的压缩长度进行重新排列,得到压缩长度地址;
35、s30:所述缓存对所述压缩长度地址中与所述存储器对应的待请求的压缩长度进行命中测试,判断所述缓存中存储的缓存行中是否存在包含所述待请求的压缩长度的第一缓存行;若所述命中测试的结果为未命中,则先执行s40后再执行s50;若所述命中测试的结果为命中,则直接执行s50;
36、s40:所述缓存从所述存储器中加载所述第一缓存行,并将所述缓存中任一替换缓存行作为替换存入所述存储器中;
37、s50:所述缓存根据所述第一访问请求的访问类型对所述待请求的压缩长度进行处理。
38、在本技术的一个优选实施例中,s10具体包括:
39、s11:所述第一图形处理核心根据任务指令选定待访问的多个存储器、确定访问所述多个存储器的访问顺序和分配每个所述存储器的访问类型;
40、s12:所述第一图形处理核心根据所述访问顺序对所述多个存储器各自对应的压缩粒度进行排列,并将排列后的压缩粒度与对应的压缩长度组成压缩粒度索引;
41、s13:所述第一图形处理核心根据所述访问类型进行第一处理;
42、s14:所述第一图形处理核心基于所述待访问的多个存储器、所述多个存储器的访问顺序、所述压缩粒度索引及各个所述存储器对应的所述访问类型和所述第一处理生成第一访问请求;
43、s15:所述第一图形处理核心根据所述访问顺序依次向所述多个存储器各自对应的压缩解压缩模块发出所述第一访问请求;
44、s16:所述压缩解压缩模块根据所述第一处理执行第二处理;
45、s17:所述压缩解压缩模块向对应的缓存发出所述第一访问请求。
46、在本技术的一个优选实施例中,在所述访问类型为读请求时,所述第一处理为所述第一图形处理核心为所述存储器分配读取指令,所述第二处理为所述压缩解压缩模块从对应的缓存中读出待请求的压缩长度;在所述访问类型为写请求时,所述第一处理为所述第一图形处理核心为所述存储器分配输入数据,所述第二处理为所述压缩解压缩模块对所述输入数据进行压缩,得到压缩数据。
47、在本技术的一个优选实施例中,s20具体包括:
48、s21:所述缓存根据所述第一访问请求中待访问的存储器数量确定第一参数;
49、s22:所述缓存设置单个缓存行的大小、单个压缩长度的大小以及单个缓存行存放压缩长度的数量,确定第二参数;
50、s23:所述缓存根据所述处理器单元最大支持处理图像的大小和所述压缩粒度的大小得到每个压缩粒度最多需要的压缩粒度编码的大小,得到第三参数;
51、s24:所述缓存根据所述第一参数、所述第二参数和所述第三参数,对所述存储器待访问的各个压缩粒度对应的压缩粒度编码进行码位重排,得到各个压缩粒度的新地址编码;
52、s25:所述缓存将各个压缩粒度的新地址编码按照各个压缩粒度的顺序依次排序,形成压缩长度地址。
53、在本技术的一个优选实施例中,s40具体包括:
54、s41:所述缓存选择给请求的第一缓存行腾出空间用作替换的替换缓存行;
55、s42:所述缓存判断所述替换缓存行中各个压缩长度的数据是否被改写过;若被改写过,则先执行s43,再执行s44;若未被改写过,则执行s44;
56、s43:所述缓存将所述替换缓存行存储至所述存储器;
57、s44:所述缓存生成第二访问请求,所述第二访问请求包括所述待请求的压缩长度;
58、s45:所述缓存向对应的存储器发出所述第二访问请求;
59、s46:所述存储器根据所述第二访问请求中所述待请求的压缩长度,找到包含所述待请求的压缩长度的第一缓存行;
60、s47:所述存储器将所述第一缓存行发回给所述缓存,所述缓存存储所述第一缓存行。
61、在本技术的一个优选实施例中,s50具体包括:
62、s51:所述缓存判断所述第一访问请求的访问类型;若为读请求,则执行s52;若为写请求,则执行s53;
63、s52:所述缓存从所述第一缓存行中读取所述待请求的压缩长度并发送给所述压缩解压缩模块;
64、s53:所述缓存将所述待请求的压缩长度写入所述第一缓存行中。
65、第三方面,本发明提供了一种电子设备,包括显示屏和如第一方面所述的图形处理器,所述图形处理器用于处理图形并将所述图形输出至所述显示屏上显示。
66、第四方面,本发明提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,当其在计算机上运行时,使得计算机执行如第二方面所述的图形处理器的数据处理方法。
67、本发明所公开的图形处理器及其数据处理方法和包含其的电子设备,将压缩解压缩模块、缓存和存储器一一对应成组配置,将存储器所访问的压缩数据对应的压缩长度进行重映射,从而提高缓存的利用率。此外,还采用分布式设计,缩短了存储器和压缩解压缩模块之间的距离,降低了访问存储器的延时和功耗。
- 还没有人留言评论。精彩留言会获得点赞!