基于分布式计算的高效大数据处理系统及方法与流程
本发明涉及数据处理,特别涉及一种基于分布式计算的高效大数据处理系统及方法。
背景技术:
1、目前,在各种零售和服务行业中经常会使用pos收款机,pos收款机(point ofsale)是一种用于商户接受支付的设备。它可以连接银行账户、信用卡、移动支付等多种支付方式,方便顾客进行消费,并实现资金的交易和结算。可以提供快速便捷的支付方式,增加顾客满意度,提高工作效率,同时也提供了更安全、更准确的交易记录和结算凭证。
2、现有技术中在同一局域网中会有多台pos收款机进行工作,但是各台pos收款机只是单独进行工作,处理简单且单一的数据运算,无法实现多台联动,来完成复杂的业务,不能有效的利用各台pos收款机的计算资源,造成计算资源的浪费。
技术实现思路
1、本发明旨在至少一定程度上解决上述技术中的技术问题之一。为此,本发明的第一个目的在于提出一种基于分布式计算的高效大数据处理系统,实现多台联动,来完成复杂的业务,有效的利用各台pos收款机的计算资源,避免计算资源的浪费。
2、本发明的第二个目的在于提出一种基于分布式计算的高效大数据处理方法。
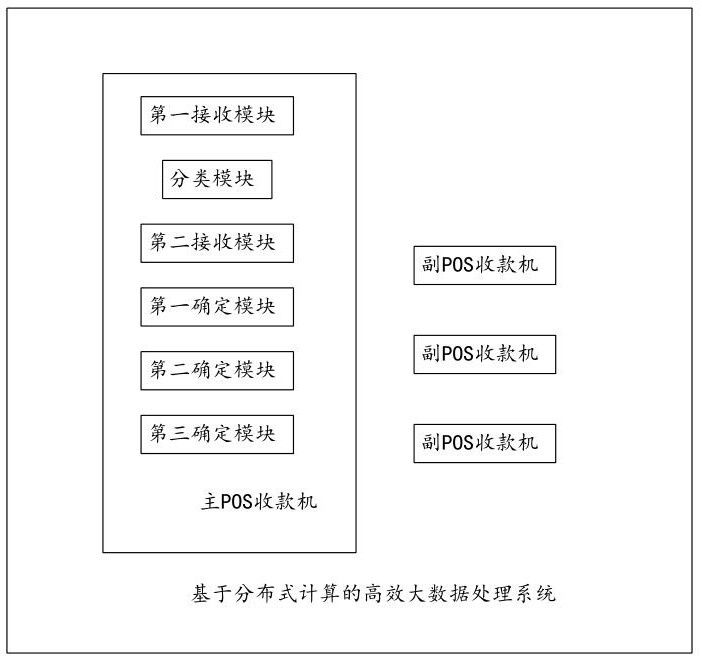
3、为达到上述目的,本发明第一方面实施例提出了一种基于分布式计算的高效大数据处理系统,包括:一台主pos收款机和若干台副pos收款机;
4、所述主pos收款机,包括:
5、第一接收模块,用于接收待处理数据集;
6、分类模块,用于解析待处理数据集包括的若干条待处理数据的属性信息,根据所述属性信息对若干条待处理数据进行分类,得到分类结果;
7、第二接收模块,用于接收用户终端发送的数据处理需求,对数据处理需求进行解析,得到解析结果;
8、第一确定模块,用于根据分类结果及解析结果确定数据处理任务;
9、第二确定模块,用于根据数据处理任务确定对应的逻辑节点拓扑图;
10、第三确定模块,用于根据逻辑节点拓扑图中确定若干台副pos收款机中对应的目标副pos收款机,作为分布式节点对数据处理任务进行计算。
11、根据本发明的一些实施例,所述分类模块,包括:
12、计算模块,用于:
13、将若干条待处理数据映射到向量空间,确定每条待处理数据对应的特征向量;
14、计算每个特征向量之间的欧式距离;根据各个特征向量之间的欧式距离计算出若干条待处理数据的平均距离;
15、确定每条待处理数据在平均距离内包含的数据量及每条待处理数据在平均距离内包含的数据量之间的欧式距离均值,计算出数据密度值;
16、根据数据密度值查询预设的数据密度值-扫描半径数据表,确定目标扫描半径;
17、获取模块,用于:
18、随机选取一条待处理数据作为聚类中心,获取与所述聚类中心之间的间距未超出扫描半径的待处理数据,作为一个分类集合;
19、在若干条待处理数据中除分类集合外再次选取一条待处理数据作为又一个聚类中心,重复以上方法进行聚类,得到若干个分类集合,进而得到分类结果。
20、根据本发明的一些实施例,所述第二接收模块,包括:
21、转换模块,用于:
22、接收用户终端发送的数据处理需求,基于汤普森算法调用正则表达式集对数据处理需求进行转换,得到非确定有限状态自动机;
23、基于子集构造法将非确定有限状态自动机转换为确定有限状态机;
24、基于分割法通过将状态分组并合并等价状态来减少确定有限状态机的状态数,得到最小状态的确定有限状态机,作为目标状态机;
25、根据目标状态机的转换表及状态机模拟器组成词法解析器;
26、解析模块,用于:
27、基于词法解析器对数据处理需求进行解析,确定词法解析结果;
28、对词法解析结果基于抽象语法树进行语义分析,得到解析结果。
29、根据本发明的一些实施例,所述第一确定模块,包括:
30、查询模块,用于根据分类结果及解析结果查询预设的分类结果-解析结果-数据处理任务数据表,确定数据处理任务。
31、根据本发明的一些实施例,第二确定模块,包括:
32、划分模块,用于对数据处理任务进行划分,得到若干个子数据处理任务;
33、融合模块,用于:
34、确定每个子数据处理任务对应的子逻辑节点拓扑图;
35、根据若干个子逻辑节点拓扑图进行融合,得到逻辑节点拓扑图。
36、根据本发明的一些实施例,所述第二确定模块,包括:
37、判断模块,用于判断数据处理任务的处理难度等级;
38、查询模块,用于根据处理难度等级查询预设的处理难度等级-逻辑节点拓扑图数据表,确定对应等级的逻辑节点拓扑图。
39、根据本发明的一些实施例,所述判断模块,包括:
40、提取模块,用于获取数据处理任务,并进行特征提取,得到特征向量d,特征向量d包括n个特征值;
41、存储模块,用于存储预设数据处理任务数据库,在预设数据处理任务数据库中拥有不同的数据处理任务的p条数据及每条数据对应的n个特征值,基于p条数据形成矩阵a,并在每条数据后面标注该数据所对应的处理难度等级,形成向量y;
42、对矩阵a进行标准化处理,得到标准化矩阵b;
43、
44、其中,为标准化矩阵b中的第i行第t列的值;为矩阵a的第i行t列的值;为向量d的第t个值; i=1、2、3……p,t=1、2、3……n;
45、计算标准化矩阵b的修正矩阵cy;
46、
47、其中,为修正矩阵cy的第j行t列的值,t=1、2、3……n, j=1、2、3……n;
48、根据修正矩阵计算修正系数向量c;
49、
50、其中, 为单位矩阵,求解以上等式,则能得到修正系数向量c;
51、根据修正系数向量及数据处理任务对应的特征向量d,计算特征向量d与第i条数据的关联系数;
52、
53、其中,为特征向量d与第i条数据的关联系数;ct为修正系数向量c的第t个值;
54、确定具有最大的关联系数的数据对应的处理难度等级,作为数据处理任务的处理难度等级。
55、为达到上述目的,本发明第二方面实施例提出了一种基于分布式计算的高效大数据处理方法,应用于基于分布式计算的高效大数据处理系统,处理系统包括:一台主pos收款机和若干台副pos收款机;所述处理方法,包括:
56、基于主pos收款机接收待处理数据集;
57、解析待处理数据集包括的若干条待处理数据的属性信息,根据所述属性信息对若干条待处理数据进行分类,得到分类结果;
58、接收用户终端发送的数据处理需求,对数据处理需求进行解析,得到解析结果;
59、根据分类结果及解析结果确定数据处理任务;
60、根据数据处理任务确定对应的逻辑节点拓扑图;
61、根据逻辑节点拓扑图中确定若干台副pos收款机中对应的目标副pos收款机,作为分布式节点对数据处理任务进行计算。
62、根据本发明的一些实施例,解析待处理数据集包括的若干条待处理数据的属性信息,根据所述属性信息对若干条待处理数据进行分类,得到分类结果,包括:
63、将若干条待处理数据映射到向量空间,确定每条待处理数据对应的特征向量;
64、计算每个特征向量之间的欧式距离;根据各个特征向量之间的欧式距离计算出若干条待处理数据的平均距离;
65、确定每条待处理数据在平均距离内包含的数据量及每条待处理数据在平均距离内包含的数据量之间的欧式距离均值,计算出数据密度值;
66、根据数据密度值查询预设的数据密度值-扫描半径数据表,确定目标扫描半径;
67、随机选取一条待处理数据作为聚类中心,获取与所述聚类中心之间的间距未超出扫描半径的待处理数据,作为一个分类集合;
68、在若干条待处理数据中除分类集合外再次选取一条待处理数据作为又一个聚类中心,重复以上方法进行聚类,得到若干个分类集合,进而得到分类结果。
69、根据本发明的一些实施例,接收用户终端发送的数据处理需求,对数据处理需求进行解析,得到解析结果,包括:
70、接收用户终端发送的数据处理需求,基于汤普森算法调用正则表达式集对数据处理需求进行转换,得到非确定有限状态自动机;
71、基于子集构造法将非确定有限状态自动机转换为确定有限状态机;
72、基于分割法通过将状态分组并合并等价状态来减少确定有限状态机的状态数,得到最小状态的确定有限状态机,作为目标状态机;
73、根据目标状态机的转换表及状态机模拟器组成词法解析器;
74、基于词法解析器对数据处理需求进行解析,确定词法解析结果;
75、对词法解析结果基于抽象语法树进行语义分析,得到解析结果。
76、本发明提出了一种基于分布式计算的高效大数据处理系统及方法,实现对待处理数据集进行分类以及对数据处理需求进行解析,准确确定数据处理任务,进而确定若干台副pos收款机中对应的目标副pos收款机,作为分布式节点对数据处理任务进行计算。实现多台联动,来完成复杂的业务,有效的利用各台pos收款机的计算资源,避免计算资源的浪费。
77、本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书以及附图中所特别指出的结构来实现和获得。
78、下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
- 还没有人留言评论。精彩留言会获得点赞!