基于油藏-井筒-设备评价指标集成的综合评价方法
本发明涉及油气田开发,具体涉及一种基于油藏-井筒-设备评价指标集成的综合评价方法。
背景技术:
1、油井生产状况评价作为指导现场作业的指向性信息,为后续优化生产奠定了基础,其通过定期评价油井的生产状况,能够识别生产过程中存在的问题,有助于采取措施提高生产效率,从而最大程度地利用油藏资源,确保资源的合理开采和分配,最大程度地满足市场需求并减少浪费。所以,油井生产状况评价对于确保油气田生产的高效性、可持续性和安全性至关重要。
2、传统的油井生产评价方法多为现场单兵作战,存在数据不共享且分析割裂的问题,其主要依托对各专业数据的单方面分析评价,经常会出现分析不到位的情况。同时,油藏井筒设备是一个相互关联且相互影响的有机整体,当油藏井筒复合型问题出现时,仅依赖油藏或井筒或设备单系统进行油井生产状况评价较为片面,治理措施针对性不强,特别是针对油藏、井筒和设备之间的共有节点分析薄弱。
3、现阶段针对石油生产的一体化分析方法较为匮乏,多采用油藏-井筒耦合分析方法、油藏-井筒-管网耦合分析方法、一体化产能分析方法等,但是,这些分析方法分析过程中均需使用节点流体模型,假设条件过多且依赖经验,通用性较差且评价准确度较低。因此,亟需提出一种基于油藏-井筒-设备评价指标集成的综合评价方法,综合考虑油藏、井筒和举升设备,全方位多目标的评估油井生产状态。
技术实现思路
1、本发明旨在提高油井生产状况评价的准确性,提供了一种基于油藏-井筒-设备评价指标集成的综合评价方法,解决了现有油田评价模式单一的问题,综合考虑油藏、井筒和举升设备对油田生产状态的影响,提高了油井生产评价结果的准确性。
2、为实现上述目的,本发明采用如下技术方案:
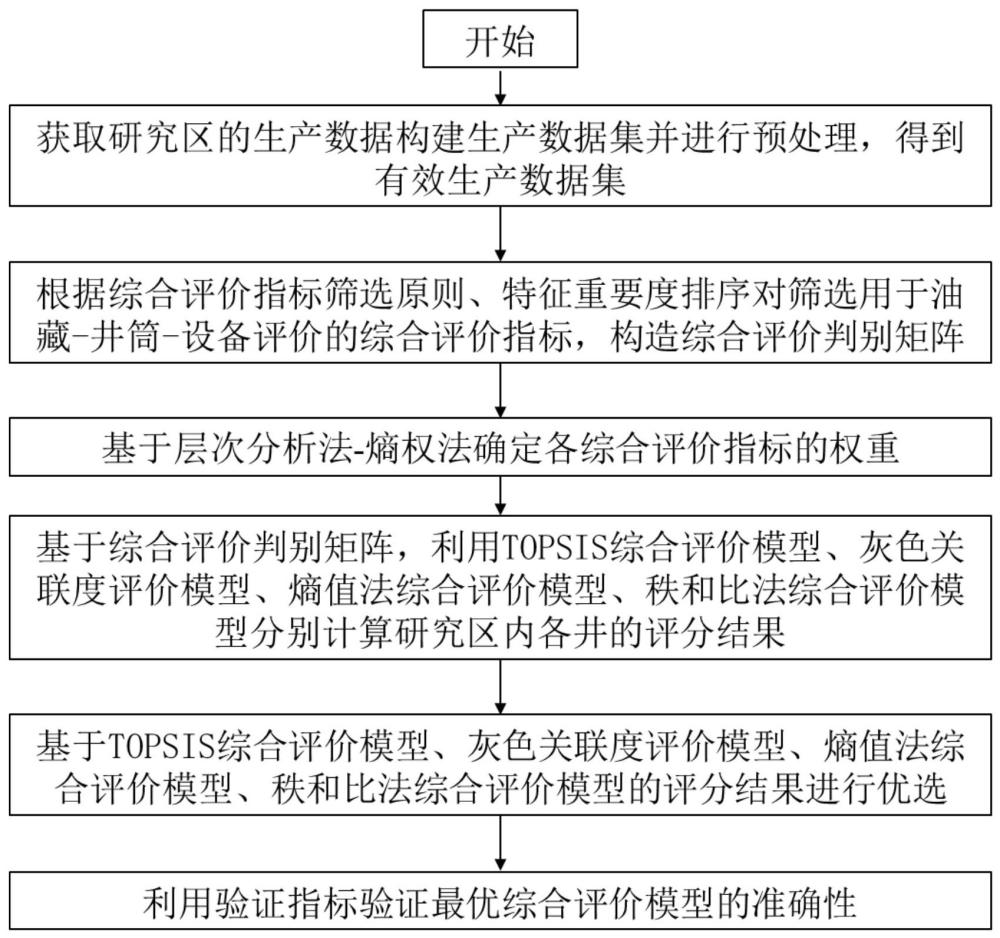
3、一种基于油藏-井筒-设备评价指标集成的综合评价方法,包括以下步骤:
4、步骤1,基于油藏资料、井筒资料和举升设备资料,获取研究区内所有井的生产数据,构建生产数据集,并对生产数据集中各井的生产数据进行预处理,得到有效生产数据集;
5、步骤2,基于有效生产数据集,根据综合评价指标筛选原则、特征重要度排序对筛选用于油藏-井筒-设备评价的综合评价指标,构造综合评价判别矩阵;
6、步骤3,基于层次分析法-熵权法确定各综合评价指标的权重;
7、步骤4,基于综合评价判别矩阵,利用topsis综合评价模型、灰色关联度评价模型、熵值法综合评价模型、秩和比法综合评价模型分别计算研究区内各井的评分结果,包括油藏评价分数、井筒评价分数、设备评价分数和综合评价分数;
8、步骤5,基于topsis综合评价模型、灰色关联度评价模型、熵值法综合评价模型、秩和比法综合评价模型的评分结果进行优选,得到最优综合评价模型及油井最优综合评分;
9、步骤6,利用验证指标验证最优综合评价模型的准确性。
10、优选地,所述步骤1中,包括以下步骤:
11、步骤1.1,获取研究区内所有井的生产数据,构建生产数据集,根据生产数据集中各生产数据的类型,确定各生产数据为数字型特征数据或文字型特征数据后,对生产数据集中的生产数据进行数据清洗,剔除油井生产数据集中的异常油井生产数据,并对生产数据集中缺失的生产数据进行空白值填充;
12、步骤1.2,基于数据处理后生产数据集中的生产数据,对生产数据集中的油藏数据、井筒数据和举升设备数据进行融合,根据井号将同一口井的生产数据合并形成子数据集;
13、步骤1.3,对生产数据集中的文字型特征数据进行标签编码,将文字型特征数据赋值转换为数字型特征数据后,对生产数据集中的各类生产数据进行标准化处理,得到有效生产数据集。
14、优选地,在生产数据集中搜寻异常生产数据确定数据异常井后,在生产数据集中删除所有数据异常井的生产数据进行数据清洗;
15、再在数据清洗后的生产数据集中搜寻缺失生产数据,确定存在生产数据空白值的井作为数据缺失井,获取数据缺失井的井号,判断缺失生产数据为数字型特征数据或文字型特征数据;
16、当缺失生产数据为数字型特征数据时,根据井号对数据缺失井的空白值进行填充,若与数据缺失井位于同一排的井存在同类生产数据,则利用相同排所有井的同类生产数据平均值填充数据缺失井的生产数据,若与数据缺失井位于同一排的井均不存在同类生产数据,则利用研究区内所有井的同类生产数据的平均值填充数据缺失井的空白值;
17、当缺失生产数据为文字型特征数据时,根据井号对数据缺失井的生产数据空白值进行填充,若与数据缺失井位于同一排的井存在同类生产数据,则利用相同排所有井中同类生产数据的众数所对应的生产数据填充数据缺失井的生产数据,若与数据缺失井位于同一排的井均不存在同类生产数据,则利用研究区内所有井的同类生产数据的众数所对应的生产数据填充数据缺失井的空白值。
18、优选地,所述步骤2中,包括以下步骤:
19、步骤2.1,基于综合评价指标筛选原则,根据有效生产数据集中各类生产数据所对应的生产指标,初步筛选用于油藏-井筒-设备评价的评价指标;
20、步骤2.2,对评价指标进行相关性分析,计算各评价指标的斯皮尔曼相关性系数并作为重要性得分;
21、步骤2.3,构建xgboost模型,利用有效生产数据集训练xgboost模型并验证,利用验证后的xgboost模型确定各评价指标的重要性;
22、步骤2.4,利用各综合评价指标所对应的生产数据构建综合评价指标矩阵,对综合评价指标矩阵进行归一化处理后,得到综合评价判别矩阵。
23、优选地,所述步骤2.3中,具体包括以下步骤:
24、步骤2.3.1,将有效生产数据集中的生产数据划分为评价指标和目标变量,设置xgboost模型的精度值,并将有效生产数据集划分为测试集和训练集;
25、步骤2.3.2,利用训练集中的生产数据训练xgboost模型,利用xgboost模型获取各评价指标所对应的生产数据计算各评价指标的重要性得分,并按照重要性得分降序输出,每次训练过程中获取当前xgboost模型的计算精度并与预设精度值进行对比,xgboost模型的计算精度已达到预设精度值,则进入步骤2.3.3中,否则,则重复步骤2.3.2继续训练xgboost模型;
26、步骤2.3.3,利用测试集验证xgboost模型的计算精度已达到预设精度值,得到验证后的xgboost模型;
27、步骤2.3.4,将有效生产数据集中的生产数据输入至验证后的xgboost模型中,利用xgboost模型计算各评价指标的重要性得分并按照降序输出,得到所有评价指标的重要性排名,选取前名评价指标作为综合评价指标。
28、优选地,所述步骤3中,包括以下步骤:
29、步骤3.1,构建层次结构模型,层次结构模型包括目标层、准则层和方案层,其中,目标层内设置有研究区内油井生产状况排名,准则层内设置有步骤2中筛选得到的各综合评价指标,方案层内设置有井号;
30、步骤3.2,采用熵权法构建判别矩阵,计算各综合评价指标的熵权法权重;
31、步骤3.3,基于层次分析法构建判别矩阵,将熵权法与层次分析法相耦合,通过标度替换各综合评价指数的熵权法权重,得到各综合评价指标的权重。
32、优选地,基于熵权法构建的判别矩阵为:
33、 (1)
34、式中,为行数,且为整数,为样本总数,为列数且为整数,为综合评价指标总数;为判别矩阵中第行第列样本数据,对应有效生产数据集中第行第列的生产数据;
35、基于线性比例变换方法标准化处理判别矩阵得到归一化矩阵;
36、若判别矩阵中的综合评价指标为正向指标,则利用正向指标变换公式进行变换得到处理后样本数据值,若判别矩阵中的综合评价指标为负向指标,则利用负向指标变换公式进行变换得到处理后的样本数据值;
37、所述正向指标的变换公式为:
38、 (2)
39、式中,为判别矩阵中第行第列样本数据经处理后的样本数据值,为最小值函数,为最大值函数;
40、所述负向指标的变换公式为:
41、 (3)
42、计算各综合评价指标的熵权法权重,如公式(4)所示:
43、 (4)
44、其中,
45、 (5)
46、式中,为第个综合评价指标的熵权法权重,为第个综合评价指标的信息熵,为第个综合评价指标中第个样本数据的比重;
47、基于层次分析法构建判别矩阵,将熵权法与层次分析法相耦合得到标度替换后的判别矩阵为:
48、 (6)。
49、优选地,所述步骤4中,所述topsis综合评价模型计算过程为:以研究区内的各井作为评价对象,先确定正理想解和负理想解,再计算各评价对象与正理想解和负理想解之间的距离,得到各评价对象对理想解的相对接近度,从而确定各评价对象的topsis综合评价模型评分;
50、所述灰色关联度评价模型计算过程为:以研究区内的各井作为评价对象,先选取各综合评价指标的最优样本数据,构建最优指标集,分别计算各评价对象中的各综合评价指标所对应的灰色关联度系数,得到各评价对象对理想解的灰色关联度,从而确定各评价对象的灰色关联度评价模型评分;
51、所述熵值法综合评价模型计算过程为:以研究区内的各井作为评价对象,基于步骤3.2中计算的各综合评价指标的熵权法权重,计算各评价对象的目标分数,从而确定各评价对象的熵值法综合评价模型评分;
52、所述秩和比法综合评价模型计算过程为:以研究区内的各井作为评价对象,基于综合评价判别矩阵计算评价对象中各综合评价指标的秩,得到秩矩阵后,计算各评价对象的秩和比值,从而确定各评价对象的秩和比法综合评价模型评分。
53、优选地,所述步骤5中,包括以下步骤:
54、步骤5.1,对topsis综合评价模型、灰色关联度评价模型、熵值法综合评价模型、秩和比法综合评价模型进行相关性分析,计算各评价模型的斯皮尔曼相关性系数,确定各评价模型之间的相关性值;
55、步骤5.2,以所选取评价模型与其他评价模型之间相关性值的总和作为优选样本,构建相关性矩阵,如公式(7)所示:
56、 (7)
57、式中,为topsis综合评价模型与其他三个评价模型之间相关性系数的总和,,;为灰色关联度评价模型与其他三个评价模型之间相关性系数的总和,,;为熵值法综合评价模型与其他三个评价模型之间相关性系数的总和,,;为秩和比法综合评价模型与其他三个评价模型之间相关性系数的总和,,;、均为评价模型的编号,当或时,表示topsis综合评价模型,当或时,表示灰色关联度评价模型,当或3时,表示熵值法综合评价模型,当或4时,表示秩和比法综合评价模型;
58、步骤5.3,根据各评价模型的优选样本,选取优选样本最大值所对应的评价模型作为最优综合评价模型,利用最优综合评价模型得到当前各井的油井最优综合评分。
59、优选地,所述步骤6中,预先获取研究区井的验证指标,基于kendall相关性系数分析计算最优综合评价模型所计算的油藏评价分数、井筒评价分数、设备评价分数和综合评价分数与验证指标之间的相关性系数,检验最优综合评价模型与验证指标之间的一致性;
60、所述kendall相关性系数计算公式为:
61、 (8)
62、式中,为kendall相关性系数,为一致对个数,为分歧对个数,为最优综合评价模型所计算得分序列中的并列排位数量,为验证指标的并列排位数量。
63、本发明所带来的有益技术效果为:
64、本发明方法通过将油藏评价指标、井筒评价指标和设备评价指标相结合,实现了对油井生产状态全方位多目标的准确评价,相比于传统油井生产评价方法采用单一指标进行评价时,油藏评价、井筒评价和设备评价三者彼此独立、相互割裂,本发明方法将油藏数据、井筒数据和设备数据三者相统一,通过分析筛选综合评价指标,并针对各评价方向选取综合评价模型,实现了对油井生产状态的多方位准确评价,有利于现场工作人员提高对当前油井生产状况的认知,为油井优化提供指向性的信息。
- 还没有人留言评论。精彩留言会获得点赞!