一种基于混合Transformer与CNN的图像压缩感知重建方法及系统
本发明涉及图像信号处理,尤其涉及一种基于混合transformer与cnn的图像压缩感知重建方法及系统。
背景技术:
1、在这个信息时代,数据的生成和存储呈现指数级增长,尤其是对于高维数据如图像和音频而言,需要大量的存储和传输带宽。压缩感知可以在采集信号时以远远低于传统采样率的方式进行采样,然后从稀疏或低维度的测量值中重构高维度数据,从而实现了数据的高效采集、传输和存储。但传统基于迭代优化的算法在大规模数据上的计算复杂度高,并且不适用于实际应用中存在的各种类型的复杂噪声。随着深度学习的发展,将深度学习的方法与压缩感知相结合可以克服传统压缩感知算法的局限性,深度压缩感知算法利用深度神经网络来学习信号的表征和重建过程,这些神经网络可以被训练成非线性稀疏变换,能够更好的处理信号中的信息,同时处理不完全采样和噪声等问题,提高了信号重建的质量和效率。
2、目前,压缩感知图像重建主要使用基于深度学习的方法,然而几乎所有的基于深度学习的图像压缩感知图像重建方法都是以卷积神经网络(cnn)作为基础,由于空间不变性和局部归纳偏差,cnn无法有效捕获像素间的远程依赖关系。这些局限性限制了深度学习方法的性能和应用范围。虽然基于局部窗口的视觉transformer可以有效的捕捉图像的全局特征信息,但是无法充分提取局部细节信息,此外基于窗口的transformer的性能受限于窗口大小,并且视觉transformer需要大量的样本进行训练才能获得良好的泛化性能。
3、在u型编码器与解码器的结构中,编码阶段将输入图像压缩为低维表示,然后解码阶段将其恢复为原始尺寸。在这个过程中,仅仅将相同大小的层次特征直接在通道维度上进行连接,这样并不能够充分利用编码阶段提取的多尺度特征。
技术实现思路
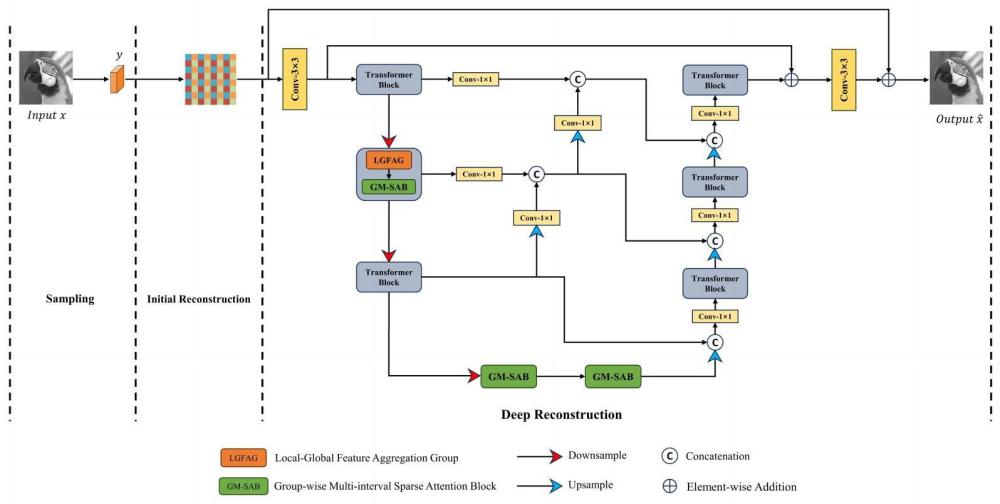
1、针对上述问题,本发明提出一种基于混合transformer与cnn的图像压缩感知重建方法及系统,使用卷积采样代替传统随机高斯正交矩阵对图像进行测量后得到测量值,测量值经过由多头转置注意力构成的初始重建子网完成测量向量到原始信号的初始重建。初始重建图像送入基于transformer与cnn的u型分层结构进行深度重建,混合transformer与cnn可以在建模像素远距离依赖关系的同时融合局部特征,使网络充分利用局部信息与全局信息的相互作用,在充分融合各层编码特征下提升重建图像质量。通过在深度重建子网阶段引入swin transformer和像素注意力充分利用局部特征和全局特征的相互作用,弥补了卷积神经网络在建模远距离依赖关系以及基于窗口的视觉transformer在提取局部特征方面的不足。通过使用分组多步幅稀疏注意力块弥补基于窗口transformer受限于窗口大小的问题,有效的提取全局信息。u型编码器与解码器结构中使用从下至上逐级融合多尺度特征的方式,解决了原始方案无法充分利用编码阶段的多尺度特征的问题。
2、为了实现上述目的,本发明采用以下技术方案:
3、本发明一方面提出一种基于混合transformer与cnn的图像压缩感知重建方法,包括:
4、根据采样率构建混合transformer与cnn的图像压缩感知重建模型,所述图像压缩感知重建模型包括采样子网,初始重建子网和深度重建子网;所述采样子网用于对图像进行特征提取,得到测量值;所述初始重建子网用于从测量值到原始信号的初始重建;所述深度重建子网用于基于初始重建后图像进行深度重建;
5、根据设置的网络损失函数及训练数据对构建的图像压缩感知重建模型进行训练;
6、基于训练好的图像压缩感知重建模型进行图像压缩感知重建。
7、进一步地,所述采样子网使用多个3×3卷积对图像进行特征提取,收集各个级别的特征,并使用池化残差连接传递层次信息,最后对各个层次的信息使用1×1卷积进行采样得到测量值y。
8、进一步地,所述初始重建子网包括层归一化层,多头转置注意力层,多层感知机层。
9、进一步地,所述初始重建子网使用转置注意力在通道维度应用自注意力计算以利用测量值的通道信息,同时使用深度可分离卷积逐通道编码空间上下文,最后通过使用像素混洗操作得到与原图大小一致的初始重建图像,然后对初始重建图像进行升维并送入深度重建子网中。
10、进一步地,所述深度重建子网为u型分层结构,包括transformer块和多尺度特征融合模块,利用transformer块对初始重建图像进行深度重建,利用多尺度特征融合模块对提取的特征进行融合,transformer块由局部全局特征聚合组和分组多步幅稀疏注意力块组成。
11、进一步地,所述局部全局特征聚合组协同利用局部特征和全局特征,通过对输入特征进行信道分离操作,分别使用基于窗口进行自注意力计算的swin transformer提取全局特征信息与像素注意力提取局部特征信息,然后将两种不同的特征信息在通道维度拼接并使用信道置乱和1×1组卷积进行融合。
12、进一步地,对于输入到分组多步幅稀疏注意力块的特征信息,分组多步幅稀疏注意力块将特征图按照通道维度分成3组,对三组特征分别使用间隔为8,16,32步幅获取不同位置的稀疏信息,然后通过进行标准自注意力计算,获得跨窗口间的信息交互。
13、进一步地,所述多尺度特征融合模块中,使用上采样和下采样操作对尺寸不一致的图像特征映射进行缩放,并使用1×1的卷积层来产生初步融合的结果。
14、进一步地,所述网络损失函数采用均方误差损失。
15、进一步地,该方法还包括:使用峰值信噪比与结构相似性作为评价指标来验证图像压缩感知重建模型的性能。
16、本发明另一方面提出一种基于混合transformer与cnn的图像压缩感知重建系统,包括:
17、模型构建单元,用于根据采样率构建混合transformer与cnn的图像压缩感知重建模型,所述图像压缩感知重建模型包括采样子网,初始重建子网和深度重建子网;所述采样子网用于对图像进行特征提取,得到测量值;所述初始重建子网用于从测量值到原始信号的初始重建;所述深度重建子网用于基于初始重建后图像进行深度重建;
18、模型训练单元,用于根据设置的网络损失函数及训练数据对构建的图像压缩感知重建模型进行训练;
19、图像压缩感知重建单元,用于基于训练好的图像压缩感知重建模型进行图像压缩感知重建。
20、与现有技术相比,本发明具有的有益效果:
21、1.初始重建子网,对比其它深度学习的图像压缩感知重建的初始重建子网的构建,仅仅使用简单的线性升维后拼接的操作得到初始重建图像,本发明对经过采样后得到的测量值使用多头转置注意力进行全局通道维度建模,充分利用测量值的通道维度的信息,增加初始重建图像质量,改善深度重建的性能和效率。
22、2.局部全局特征聚合组(lgfag),在深度重建子网中,对于输入的特征图,本发明使用信道分离操作得到两部分特征,分别针对这两部分特征使用swin transformer提取全局图像特征和使用像素注意力提取局部纹理细节信息,协同充分利用局部特征和全局特征,提高模型的泛化能力。
23、3.分组多步幅稀疏注意力块(gm-sab),对于输入到gm-sab的特征信息,本发明将特征图按照通道维度分成3组,对三组特征分别使用间隔为8,16,32步幅获取不同位置的稀疏信息,然后通过进行标准自注意力计算,获得更多的跨窗口间的信息交互,进一步增强深度提取模块对全局特征信息的提取能力。
24、4.多尺度特征融合模块,对比传统的编码器-解码器结构沿着特征图的通道维度将相同尺寸的特征图进行残差连接,聚集编码器的低级图像特征和解码器的高级图像特征,本发明设计了一种从下至上逐层融合编码器阶段的多尺度特征融合模块。使用上采样和下采样操作对尺寸不一致的图像特征映射进行缩放,并使用1×1的卷积层来产生初步融合的结果,使网络模型具有更好的特征传播和表示能力。
- 还没有人留言评论。精彩留言会获得点赞!