一种基于信创环境的实时计算框架搭建方法与流程
本发明涉及实时计算框架,尤其涉及一种针对静态批次数据、流式数据的基于信创环境的实时计算框架搭建方法。
背景技术:
1、信创环境,即信息技术应用创新环境,指的是国家构建自己的信息技术产业标准和生态,使得it产品跟技术安全可控。在传统的数据处理流程(离线计算)中,先是收集数据,然后将数据存储到数据库中。当需要某些数据时,可以通过对数据库中的数据做操作,得到所需要的数据,再进行其他相关的处理。这样的处理流程会造成结果数据密集,结果数据密集则数据反馈不及时。对于配网的数据采集、流式存储、实时计算等功能的实现而言,传统的数据处理流程反馈速度慢,难以满足业务场景的需求。对于电网一类的企业所使用的数据处理系统而言,海量数据的高效处理和安全性的高度保障都是不可或缺的,因此有必要基于信创环境搭建一套能够满足配网各种静态批次数据、流式数据处理需求的实时计算框架。
技术实现思路
1、鉴于此,本发明的目的在于提供一种基于信创环境的实时计算框架搭建方法,以apache flink为实时计算框架基础,实现流批一体实时计算,优化、提升其应用容错能力,满足电网应用场景的低延时、高呑吐、高健壮等方面的要求。
2、为实现上述发明目的,本发明提供一种基于信创环境的实时计算框架搭建方法,所述方法包括以下步骤:
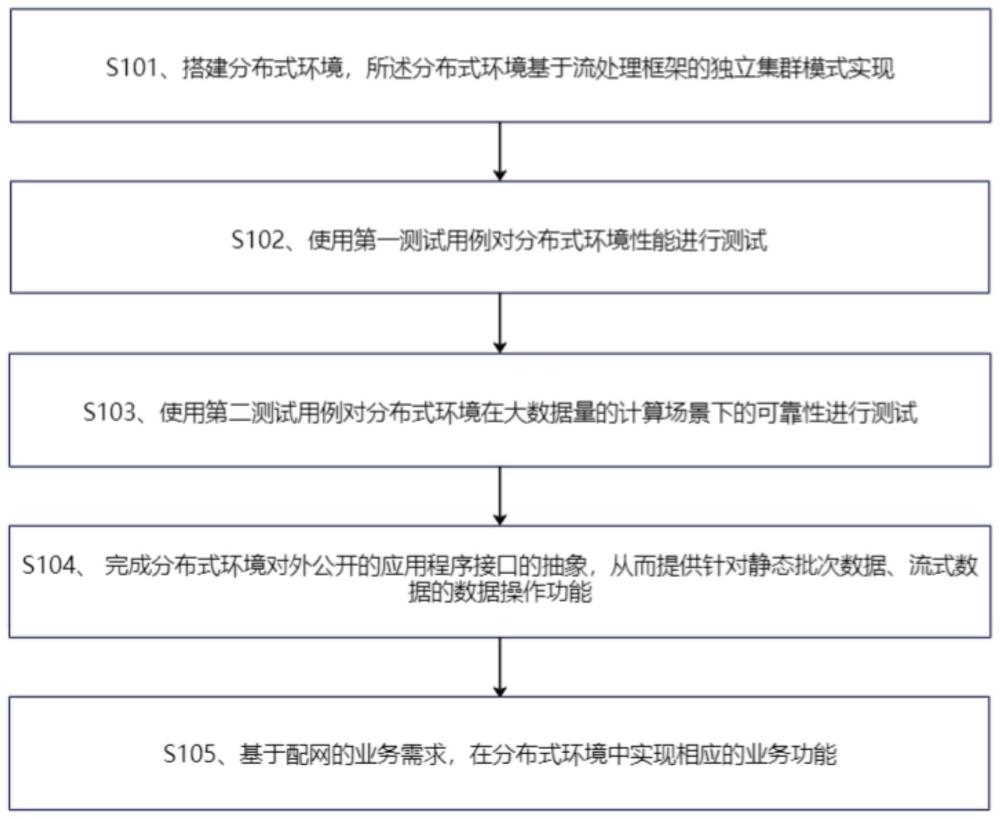
3、s101、搭建分布式环境,所述分布式环境基于流批一体处理框架的独立集群模式实现;
4、s102、使用第一测试用例对分布式环境性能进行测试;
5、s103、使用第二测试用例对分布式环境在大数据量的计算场景下的可靠性进行测试;
6、s104、完成分布式环境对外公开的应用程序接口的抽象,从而提供针对静态批次数据、流式数据的数据操作功能;
7、s105、基于配网的业务需求,在分布式环境中实现相应的业务功能。
8、进一步的,步骤s101中,流批一体处理框架采用flink流计算引擎。
9、进一步的,在步骤s102和s103之前,对分布式环境的测试环境进行软硬件配置,分布式环境包括三台服务器node0、node1和node2,其中node0上部署的软件包括flinkmaster、redis、flink worker、zookeeper和kafka broker;node1和node2上部署的软件包括flink worker、zookeeper和kafka broker。
10、进一步的,在步骤s102和s103之前,还包括步骤:生成测试数据,测试数据由数据生成器生成,并存储到kafka中,对于kafka的每个分区,数据生成器首先置入开始标记,用于标记计算开始,并按预设的程序参数要求生成测试数据,最后在kafka的每个分区置入结束标记,用于标记计算结束。
11、进一步的,步骤s102具体包括以下步骤:
12、s201、同步node1、node2和node3的系统时钟;
13、s202、将测试数据输入到应用程序中,将应用程序提交到分布式环境的flink集群中执行,应用程序执行预设算法对测试数据进行处理;
14、s203、在应用程序执行结束后获取结果;
15、s204、基于应用程序的执行过程获取性能评价指标。
16、进一步的,步骤s204中,性能评价指标包括计算总时间和任务调度时间,计算总时间的获取包括以下步骤:
17、s301、在应用程序执行过程中,当读取到测试数据中的开始标记时,将当前时间写入redis中的key中,将该key命名为voltage_start,若voltage_start已存在,则取最小值存入;
18、s302、当读取到测试数据中的结束标记时,将当前系统时间写入redis中的另一key中,将该key命名为voltage_end,若voltage_end已存在,则取最大值存入,并分别创建名为voltage_time、voltage_end_count的key,将voltage_end-voltage_start的结果存入voltage_time中,若voltage_time已存在则对其进行更新,更新voltage_end_count为自增1;
19、s303、当voltage_end_count与voltage_end_num相等时,读取voltage_time得到计算总时间,voltage_end_num为kafka分区数;
20、任务调度时间通过读取flink jobmanager的日志信息计算得到。
21、进一步的,步骤s105中,在分布式环境中实现低电压检测业务场景下的数据链路和数据处理算法,数据处理算法包括以下步骤:
22、s401、数据从数据源进入kafka,kafka中每个分区内的数据格式均为d(mpoint)(mptime),其中mpoint表示计量点编号,mptime表示计量点获取数据时间;
23、s402、flink kafka connector从kafka中读取数据,按照数据的key进行划分,将其发往对应处理该key的flink worker;
24、s403、flink worker维护一个keyedstate,每个key对应一个state,在接收到数据时,flink worker对当前key的state进行更新,并在所接收数据的mptime对应的一天结束时注册事件;
25、s404、当新一天的数据到来时,将该数据的mptime作为event time触发flink的watermark更新,使得之前注册的事件被触发,汇总前一天所有数据的state被存储到redis中,并把state更新为初始状态。
26、进一步的,当kafka有多个分区时,检测对应时间区间的状态已经输出的元素对于迟到的数据,将其从redis中取回state,更新后重新写回。
27、进一步的,在实现低电压检测业务场景下的数据处理算法时,对数据处理算法进行优化,所述优化包括复用dataformat对象,使用unix时间戳代替date对象,复用random对象。
28、进一步的,在触发watermark更新时,对每个mpoint管理各自的watermark和结果输出时间。
29、与现有技术相比,本发明的有益效果是:
30、本发明提供的一种基于信创环境的实时计算框架搭建方法,首先基于流批一体处理框架搭建分布式环境,随后分别通过第一测试用例、第二测试用例充分测试分布式环境的性能和在大数据量的计算场景下的可靠性,以便根据测试结果优化分布式环境配置,随后完成分布式环境对外公开的应用程序接口的抽象,从而提供针对静态批次数据、流式数据的数据操作功能,最后基于配网的业务需求,在分布式环境中实现相应的业务功能,以本发明所提供的实时计算框架为核心,能够实现配变重过载、低电压实时预警场景的数据采集、流式数据存储、实时业务计算、结果数据存储、预期提醒、统计结果展示等功能,支撑提升配网抢修响应效率、优化配网运行工作、辅助配网投资优化等业务。
- 还没有人留言评论。精彩留言会获得点赞!