一种基于LTC流程的项目管理方法及系统与流程
本发明涉及适用于管理目的的数据处理,具体涉及一种基于ltc流程的项目管理方法及系统。
背景技术:
1、基于ltc流程的项目管理是一种以客户为中心的项目管理方法,关注从销售线索到订单执行和现金收款的整个流程。该方法强调整个业务流程的集成和协同,以确保客户需求得到满足,同时最大化组织的效率和盈利能力。为了满足上述需求,基于ltc流程的项目管理需要通过对一天内每个不同时间节点分别投入不同的人力分配,以最大的效率和盈利能力满足客户需求,现有方法通常基于数据预测,预测一天内不同时间节点的业务需求量。在此可以通过dbscan聚类算法,对历史业务需求量的时序数据曲线用聚类中心进行拟合,以得到历史数据的拟合曲线,从而对每个时间节点的业务需求量进行预测,进而进行资源分配管理。
2、现有的问题:由于业务需求量具有一定的随机性,而dbscan聚类算法中的邻域半径和最小样本数固定,故存在可能会陷入局部最优解的问题,导致聚类结果不准确,数据拟合效果不佳,影响预测结果,进而导致项目管理的效率降低。
技术实现思路
1、本发明提供一种基于ltc流程的项目管理方法及系统,以解决现有的问题。
2、本发明的一种基于ltc流程的项目管理方法及系统采用如下技术方案:
3、本发明一个实施例提供了一种基于ltc流程的项目管理方法,该方法包括以下步骤:
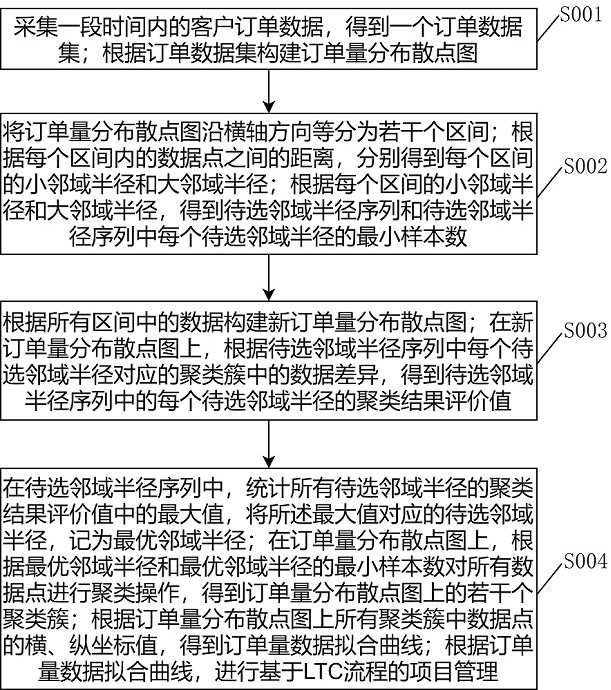
4、采集一段时间内的客户订单数据,得到一个订单数据集;根据订单数据集构建订单量分布散点图;
5、将订单量分布散点图沿横轴方向等分为若干个区间;根据每个区间内的数据点之间的距离,分别得到每个区间的小邻域半径和大邻域半径;根据每个区间的小邻域半径和大邻域半径,得到待选邻域半径序列和待选邻域半径序列中每个待选邻域半径的最小样本数;
6、根据所有区间中的数据构建新订单量分布散点图;在新订单量分布散点图上,根据待选邻域半径序列中每个待选邻域半径对应的聚类簇中的数据差异,得到待选邻域半径序列中的每个待选邻域半径的聚类结果评价值;
7、在待选邻域半径序列中,统计所有待选邻域半径的聚类结果评价值中的最大值,将所述最大值对应的待选邻域半径,记为最优邻域半径;在订单量分布散点图上,根据最优邻域半径和最优邻域半径的最小样本数对所有数据点进行聚类操作,得到订单量分布散点图上的若干个聚类簇;根据订单量分布散点图上所有聚类簇中数据点的横、纵坐标值,得到订单量数据拟合曲线;根据订单量数据拟合曲线,进行基于ltc流程的项目管理。
8、进一步地,所述根据订单数据集构建订单量分布散点图,包括的具体步骤如下:
9、以时间为横轴、订单数量为纵轴,构建平面直角坐标系;
10、在平面直角坐标系上,按照时间顺序,根据订单数据集中每个订单的产生时间,统计每一分钟内的订单数量,得到订单量分布散点图。
11、进一步地,所述根据每个区间内的数据点之间的距离,分别得到每个区间的小邻域半径和大邻域半径,包括的具体步骤如下:
12、将订单量分布散点图上的任意一个数据点,记为目标点;
13、在订单量分布散点图上,将目标点分别与其它所有数据点之间的距离中的最小值,记为目标点的最近距离;
14、将订单量分布散点图上所有数据点的最近距离的均值,记为基础距离;
15、将任意一个区间,记为目标区间;
16、将目标区间中以所有数据点的横坐标均值为横坐标值、以所有数据点的纵坐标均值为纵坐标值的数据点,记为目标区间中心点;
17、在订单量分布散点图上的目标区间中,将到目标区间中心点的距离小于基础距离的数据点,记为参考点;
18、在订单量分布散点图的横轴方向上,将目标区间中心点左侧的所有参考点,记为左参考点,将目标区间中心点右侧的所有参考点,记为右参考点;
19、在所有左参考点中,将距离目标区间中心点最小的左参考点,记为左近参考点,将距离目标区间中心点最大的左参考点,记为左远参考点;
20、在所有右参考点中,将距离目标区间中心点最小的右参考点,记为右近参考点,将距离目标区间中心点最大的右参考点,记为右远参考点;
21、根据基础距离、目标区间中数据点和参考点的数量、左近参考点到右远参考点的距离、左远参考点到右远参考点的距离,分别得到目标区间的小邻域半径和大邻域半径。
22、进一步地,所述根据基础距离、目标区间中数据点和参考点的数量、左近参考点到右远参考点的距离、左远参考点到右远参考点的距离,分别得到目标区间的小邻域半径和大邻域半径对应的具体计算公式为:
23、;
24、其中为目标区间的小邻域半径,为目标区间的大邻域半径,为基础距离,为左近参考点到右远参考点的距离,为左远参考点到右远参考点的距离,为目标区间中数据点的数量,为目标区间中参考点的数量,为向上取整函数。
25、进一步地,所述根据每个区间的小邻域半径和大邻域半径,得到待选邻域半径序列和待选邻域半径序列中每个待选邻域半径的最小样本数,包括的具体步骤如下:
26、将所有区间的小邻域半径中的最小值,记为最小邻域半径;
27、将所有区间的大邻域半径中的最大值,记为最大邻域半径;
28、从最小邻域半径开始,进行加1递增的迭代,依次统计每次迭代后的数据,直至到达最大邻域半径,得到一个待选邻域半径序列;
29、在待选邻域半径序列中,将每个待选邻域半径与预设的数量系数的乘积,记为每个待选邻域半径的最小样本数。
30、进一步地,所述根据所有区间中的数据构建新订单量分布散点图,包括的具体步骤如下:
31、在每个区间中,按照时间顺序,依次统计每个时间点上的订单数量,得到每个区间对应的订单量数据序列;
32、以序数值为横轴、订单数量为纵轴,构建新平面直角坐标系;所述序数值为每个区间对应的订单量数据序列中的序数值;
33、在所有区间对应的订单量数据序列中,以每个数据的订单量和序数值,确定每个数据对应在新平面直角坐标系上的数据点,根据所有数据对应在新平面直角坐标系上的数据点,得到新订单量分布散点图。
34、进一步地,所述在新订单量分布散点图上,根据待选邻域半径序列中每个待选邻域半径对应的聚类簇中的数据差异,得到待选邻域半径序列中的每个待选邻域半径的聚类结果评价值,包括的具体步骤如下:
35、分别对每个区间对应的订单量数据序列进行stl分解,得到每个区间对应的订单量数据序列的周期项和残差项;
36、将待选邻域半径序列中的任意一个待选邻域半径,记为目标邻域半径;
37、在新订单量分布散点图中,根据目标邻域半径和目标邻域半径的最小样本数,使用dbscan聚类算法进行聚类操作,得到新订单量分布散点图中的若干个聚类簇;
38、将新订单量分布散点图中的任意一个聚类簇,记为目标簇;
39、将所有区间对应的订单量数据序列中的任意一个订单量数据序列,记为目标序列;
40、将目标簇中所有数据点对应的目标序列中的数据,记为目标数据;
41、根据所有目标数据对应的目标序列的周期项和残差项中的数据差异,得到目标簇中的目标序列的异常程度;
42、在所有区间对应的订单量数据序列中,将目标簇中的所有订单量数据序列的异常程度的均值,记为目标簇的局部最优异常程度;
43、在新订单量分布散点图中的所有聚类簇中,计算1减去每个聚类簇的局部最优异常程度的差值,将1分别减去所有聚类簇的局部最优异常程度的差值的均值,记为目标邻域半径的聚类结果评价值。
44、进一步地,所述根据所有目标数据对应的目标序列的周期项和残差项中的数据差异,得到目标簇中的目标序列的异常程度,包括的具体步骤如下:
45、将目标序列的残差项中所有数据的均值,记为标准残差值;
46、在目标序列中,使用一阶导数法,得到若干个局部极值点;
47、在目标序列的周期项中,使用一阶导数法,得到若干个局部极大值和局部极小值;
48、在目标序列的周期项中,统计每个局部极大值相邻的两个局部极小值的序数值,将所述序数值的差值的绝对值,记为每个局部极大值的周期值,再统计所述两个局部极小值中的最小值,将每个局部极大值减去所述最小值的差值,记为每个局部极大值的波动值;
49、将每个局部极大值的波动值除以周期值的商值,记为每个局部极大值的陡峭值;
50、将所有目标数据对应的目标序列的周期项中的局部极大值,记为参考极大值;
51、将所有目标数据对应的目标序列的残差项中的数据,记为参考残差数据;
52、根据所有参考残差数据、所有参考极大值的陡峭值、所有目标数据中的局部极值点的数量,得到目标簇中的目标序列的异常程度对应的具体计算公式为:
53、;
54、其中r为目标簇中的目标序列的异常程度,为参考残差数据的数量,为第个参考残差数据,为标准残差值,为参考极大值的数量,为第个参考极大值的陡峭值,为所有参考极大值的陡峭值的均值,为所有目标数据中的局部极值点的数量,为线性归一化函数,为绝对值函数。
55、进一步地,所述根据订单量分布散点图上所有聚类簇中数据点的横、纵坐标值,得到订单量数据拟合曲线;根据订单量数据拟合曲线,进行基于ltc流程的项目管理,包括的具体步骤如下:
56、在订单量分布散点图上的每个聚类簇中,将以所有数据点的横坐标均值为横坐标值、以所有数据点的纵坐标均值为纵坐标值的数据点,记为每个聚类簇的中心点;
57、在订单量分布散点图上,使用最小二乘法对所有聚类簇的中心点进行曲线拟合,得到订单量数据拟合曲线;
58、根据订单量数据拟合曲线进行数据预测,得到所述一段时间内的下一分钟内的预测订单量;
59、根据所述一段时间内的下一分钟内的预测订单量,对所述一段时间内的下一分钟进行基于ltc流程的项目管理。
60、本发明还提出了一种基于ltc流程的项目管理系统,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述存储器存储的计算机程序,以实现前述所述的一种基于ltc流程的项目管理方法的步骤。
61、本发明的技术方案的有益效果是:
62、本发明实施例中,采集订单数据集构建订单量分布散点图,获取待选邻域半径序列和待选邻域半径序列中每个待选邻域半径的最小样本数,其通过计算邻域半径的选取范围和对应的最小样本数,提高了最优邻域半径选取的优异性,从而保障拟合曲线的可信度。构建新订单量分布散点图,在新订单量分布散点图上,根据待选邻域半径序列中每个待选邻域半径对应的聚类簇中的数据差异,得到待选邻域半径序列中的每个待选邻域半径的聚类结果评价值,由此获取最优邻域半径,其通过分析不同邻域半径的聚类效果,得到最好效果对应的邻域半径,由此进一步最优邻域半径选取的优异性,从而得到订单量分布散点图上的若干个聚类簇,由此获取订单量数据拟合曲线,保障了拟合曲线中数据的可信度,使用可信的拟合数据进行分析和预测,从而进行基于ltc流程的项目管理。至此本实施例通过自适应邻域半径和最小样本数,得到较好的聚类效果,提高了订单量数据拟合曲线的可信度,使用可信的拟合数据进行分析和预测,从而提高了基于ltc流程的项目管理的效果。
- 还没有人留言评论。精彩留言会获得点赞!