一种基于双教师结构的半监督脑出血图像分割方法
本发明涉及图像分割,具体来说,涉及一种基于双教师结构的半监督脑出血图像分割方法。
背景技术:
1、脑出血是一种十分普遍且严重的神经系统疾病,并且是导致脑卒中的主要原因。脑出血在30天内的死亡率高达百分之40,并且高达百分之80的患者半年内不能独立生活,具有很高的发病率、致残率、死亡率和复发率,已经构成了严重的公共卫生问题。因此在脑出血早期进行快速并准确的诊断和治疗对于拯救患者生命和预后恢复有着至关重要的意义。计算机断层扫描(ct)等放射成像能够准确反应脑出血位置,量化脑血肿体积,是诊断脑出血的主要手段。在脑出血的早期阶段,准确测量血肿体积,是医生做出治疗决策,预测患者的术后的关键。目前临床实践中由具有丰富经验的放射科医生人工采用基于ct面积的半自动abc/2方式进行血肿体积估计,这是十分耗时的并且评估结果没有很好的稳定性和一致性,评估精度会受不同医生经验和不规则和大规模的脑出血影响。为了在临床中快速并且精确估算脑出血体积,在ct医学图像上进行精准的全自动脑出血分割就变得尤为重要。
2、随着深度学习的高度发展,最近已经有研究开始关注在ct图像上的脑出血分割任务,这些依赖于大量标记数据的自动分割模型取得了不错的进展。然而,脑出血会在ct图像上呈现不同信号强度,从明亮到暗淡,脑出血在ct上也会呈现的不同的分布特征,有时是明显的致密区域,有时是分散的出血点。这使很多分割模型在对于模糊的出血边界,分散的小出血点还有和脑实质密度相似的血肿不能很好的识别。更重要的是,逐切片标记这些像素级的注释是费时且昂贵的,需要拥有丰富经验的专业医生耗费大量时间和精力去进行标注。相比之下,未标记的医学图像数据便宜且较容易获取。因此通过半监督学习策略,只使用有限的标记数据和易获得的无标签数据来进行脑出血图像分割变得十分重要。
技术实现思路
1、针对相关技术中的问题,本发明提出一种基于双教师结构的半监督脑出血图像分割方法,以克服现有相关技术所存在的上述技术问题。
2、为此,本发明采用的具体技术方案如下:
3、一种基于双教师结构的半监督脑出血图像分割方法,该脑出血分割方法包括以下步骤:
4、s1:获取脑出血ct图像数据集并进行整理;
5、s2:对获取的脑出血ct图像数据集进行图像预处理;
6、s3:构造脑出血分割主干网络;
7、s4:构造基于双教师结构的半监督脑出血图像分割网络模型,并将s3构造的脑出血分割主干网络嵌入模型中;
8、s5:将预处理的脑出血ct图像作为网络模型的输入,利用模型提取特征并通过前向传播的方式不断对特征进行深度提取,训练网络模型并保存模型参数;
9、s6:加载网络模型,利用脑出血ct图像分割网络模型对脑出血ct图像进行分割,并依据预设的评判指标对模型的预测结果进行分割性能评估;分割性能评估达预期则保存模型参数并作为最优网络模型,进行s7;分割性能评估未达预期则返回s5调整微参数重新训练模型;
10、s7:获取待分割的脑出血ct图像,参照s2进行图像预处理;将预处理的脑出血ct图像作为最优网络模型的输入,最优网络模型输出脑出血图像的自动分割结果。
11、s1:获取脑出血ct图像数据集并进行整理中具体采用如下方式:
12、s11:构建脑出血ct图像数据集,数据集中包括诊断为各种类型脑出血患者的非增强脑部ct数据,脑出血类型包含了脑实质出血,硬膜外出血,硬膜下出血和蛛网膜下腔出血;
13、s12:将少量脑出血ct图像划分出2种类型区域,分别为:背景和脑出血区域;剩余大部分脑出血ct图像不进行手动分割;
14、s13:将脑出血ct图像数据集按预设比例分为训练集、验证集和测试集;
15、s2:对获取的脑出血ct图像数据集进行图像预处理包括以下步骤:
16、s21:标准化多模态,采用z-score方式对图像标准化之前,先去除图像中1%的最大和最小强度值;
17、s22:裁剪,考虑计算机设备对于内存的限制对数据进行裁剪,去除多余的黑色背景信息。
18、s23:将原始ct数据的(窗口,窗宽)分别设置成(40,40),(80,100)和(40,190),并合并成三通道图像数据。
19、s24:应用随机强度偏移和随机平移、旋转来进行数据增强。
20、s3:构造脑出血分割主干网络采用如下方法所示:
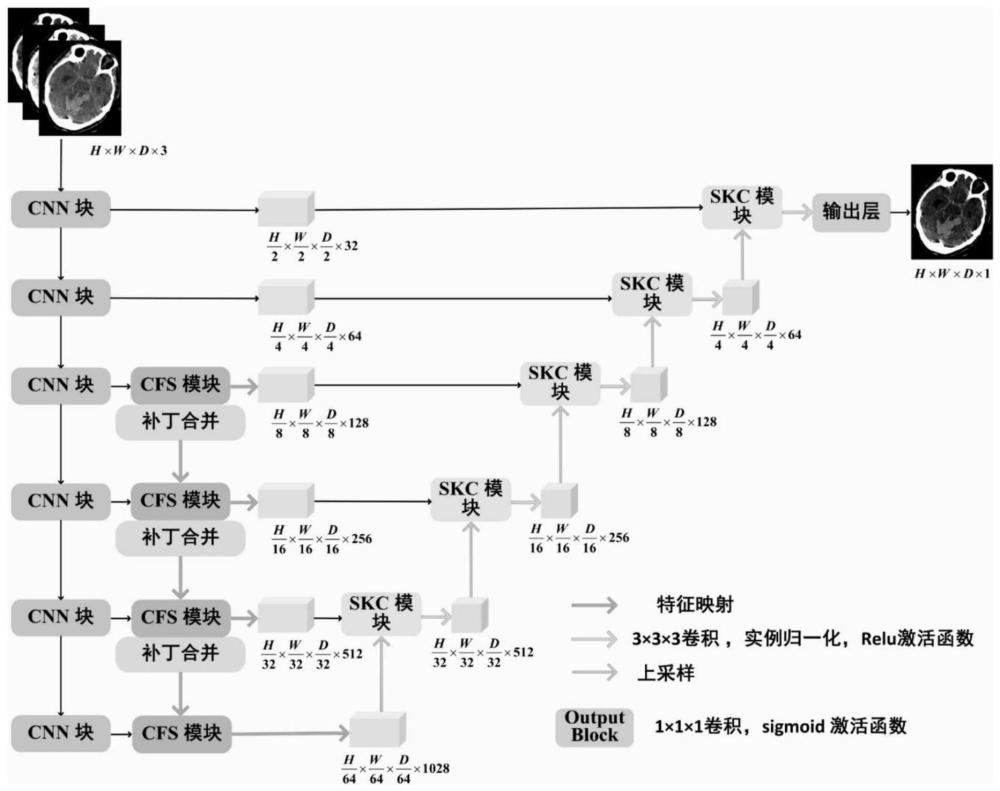
21、s31:构造cnn编码器,cnn编码器由一个拥有4个3d cnn块,每个3d cnn块包括了两个3d卷积层和一个下采样层。
22、s32:构造跨特征空间感知transformer(cfs)模块,跨特征空间感知transformer模块由轴感知注意力msaz,水平感知注意力msaxy和窗口感知注意力msaw组成,不仅可以增强全局空间特征的表达,高效率的建立远程依赖关系,还能够充分考虑两种不同信息的空间一致性,深度融合局部信息和全局信息。
23、s33:构造跳转连接transformer(skc)模块,跳转连接transformer替代了普通的concat操作,通过将编码器中丰富的低级特征融合进上解码器的特征,使得上采样过程中脑出血的高精度细节信息得以保留。先将来自编码器的特征和上采样过程中解码器的特征通过补丁嵌入层变成特征序列再将这两个特征序列送进跳转连接transformer模块中,其中:h、w、d、c分别表示图像数据的高度、宽度、切片数和通道数,具体计算细节如下:
24、
25、其中qt,kt,vt分别表示查询、键和值,这里的是qt,kt,vt的权重注意力计算如下:
26、
27、其中,msasc(·)表示注意力计算,dt为kt的维度大小,softmax(·)为softmax激活函数。
28、最终的跳转连接transformer计算如下:
29、
30、其中,catten(·)为跳转连接transformer的总计算过程。
31、s4:基于双教师结构的半监督脑出血图像分割网络模型的构造,具体方法如下所示:
32、s41:构建更为严格的置信度加权ce损失函数,它是由有监督的损失函数和一致性损失函数构成;
33、s42:构建网络扰动,网络扰动是由教师模型和学生模型产生的,而为了使教师模型预测结果稳定性更好;
34、s43:构建特征扰动,特征扰动是由对抗特征噪声组成的。我们找到使模型输出差别最大的扰动方向,以此生成对抗特征噪声,提高一致性学习的效率。
35、s5:将预处理的脑出血ct图像作为网络模型的输入,利用模型提取特征并通过前向传播的方式不断对特征进行深度提取,训练网络模型并保存模型参数,具体方法如下所示:
36、s51:训练时使用adam优化器,并将学习率设置为0.0004,损失函数使用置信度加权ce损失。使用具有20次容忍性的提前停止技术,最大300个epochs。使用5折交叉验证,保存最优训练权重。
37、s6:加载网络模型,利用脑出血ct图像分割网络模型对脑出血ct图像进行分割,并依据预设的评判指标对模型的预测结果进行分割性能评估;分割性能评估达预期则保存模型参数并作为最优网络模型,进行s7;分割性能评估未达预期则返回s5调整微参数重新训练模型;具体方法如下所示:
38、s61:加载网络模型,利用脑出血ct图像分割网络模型对脑出血ct图像进行分割,得到分割结果;
39、s62:使用dice相似系数、hausdorff距离、相对体积差和表面dice评判指标对模型的预测结果进行分割性能评估。dice系数是一种评估相似度的系数,通常用于计算两个样本的相似度或者重叠度,取值为[0,1],越接近1,相似程度越高;hausdorff距离表示预测结果与真实标签最近点距离的最大值,值越小,代表两个集合的相似度越高;相对体积差是一种用于衡量分割结果和真实标签之间体积差异的指标,其计算方式是将分割结果的体积和真实标签的体积之差除以真实标签的体积。表面dice是给定一个容许的误差距离,在此容差范围内的表面视作重叠部分,计算真实标签和预测结果的表面重叠值。
40、s63:分割性能评估达预期则保存模型参数并作为最优网络模型,进行s7;分割性能评估未达预期则返回s5调整微参数重新训练模型;
41、s7:获取待分割的脑出血ct图像,参照s2进行图像预处理;将预处理的脑出血ct图像作为最优网络模型的输入,最优网络模型输出脑出血图像的自动分割结果。具体方法如下所示:
42、s71:获取待分割的脑出血ct图像,参照s2进行图像预处理;
43、s72:将预处理的脑出血ct图像作为最优网络模型的输入,最优网络模型输出脑出血图像的自动分割结果。
44、本发明的有益效果
45、在脑出血的早期阶段,精准定位脑出血位置,准确分割脑出血并血肿体积,是医生做出治疗决策,预测患者的术后的关键。而目前临床实践中由具有丰富经验的放射科医生进行脑出血分割和脑血肿体积估计,这是十分耗时的并且评估结果没有很好的稳定性和一致性。本发明提出一种全自动分割脑出血的方法,可以精确地分割脑出血,为脑血肿体积估计做准备。逐切片标记像素级的脑出血注释是费时且昂贵的。本发明是第一个提出使用半监督方法进行脑出血分割的模型,解决了训练脑出血模型时标记数据集较小的问题,用少量标记数据和一定数量的未标记数据就可以很大提升脑出血分割精度。
- 还没有人留言评论。精彩留言会获得点赞!