基于多模态大语言模型的关系抽取方法
本发明涉及数据处理,具体涉及基于多模态大语言模型的关系抽取方法。
背景技术:
1、在过去的研究中,关系抽取任务主要集中于文本数据,这在处理社交媒体帖子等非结构化多模态数据时表现出局限性。近些年,多模态领域的研究热点之一是利用视觉信息来补充文本的上下文信息。现有的多模态关系抽取方法的输入形式可以分为文本+图像范式和将图像转换为文字描述再与文本组合的文本+文本范式。基于文本+图像范式的方法存在的局限包括不同模态间对齐方式过于浅层、不同模态特征的提取方式不一致等。目前使用文本+文本的范式来完成多模态命名实体识别和多模态关系抽取任务,显然,文本间的注意力机制要优于跨模态的注意力机制。然而,现有的基于该范式的方法仍存在一些问题,一些方法在需要额外的外部知识以增强文本理解时难以获得必要的相关知识,而其他方法从外部知识库检索到的知识又过于冗余,甚至会误导模型。
技术实现思路
1、为此,本发明提供基于多模态大语言模型的关系抽取方法,以解决背景技术中提出的问题。
2、为了实现上述目的,本发明提供如下技术方案:基于多模态大语言模型的关系抽取方法,包括以下步骤:
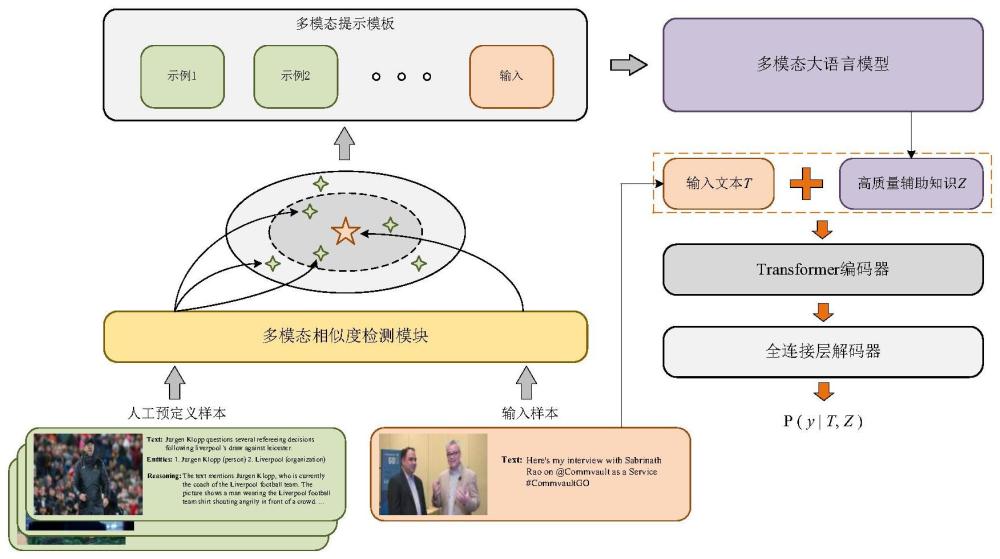
3、步骤1:采用多模态相似度检测模块为数据集中的每一个样本从一组人工预定义的样本中选择相关示例,将选定的示例与输入样本整合到特定格式的多模态提示模板中,用以启发大语言模型生成辅助知识;
4、步骤2:将输入文本与大语言模型生成的辅助知识拼接在一起,再将其送入编码器用于生成融合特征;
5、步骤3:将步骤2中的融合特征送入全连接层解码,以预测输入文本中两个实体间的关系。
6、优选的,步骤1中,形成多模态提示模板包括以下操作:
7、大语言模型是基于海量数据集进行预训练的自回归语言模型。在推理过程中,通过上下文少样本学习以文本序列生成任务的形式在预训练的大语言模型上完成新的下游任务,给定一个测试输入x,带有n个上下文示例的上下文c={c1,…,cn},输出y是基于格式化提示p(c,x)作为条件来预测的;其中,c和x都是图像文本序列,输出y={y1,…,yl}是长度为l的文本序列;对于序列中的第l个字符,解码过程可以表示为:
8、yl=argmaxpllm(yl|p,y<l) (1)
9、llm表示预训练的大语言模型的权重,这些权重在下游任务中被冻结,每个上下文示例ci=(xi,yi)都是相关任务的输入输出对,这些示例是手动构建或从训练集中抽样得到的。
10、优选的,形成多模态提示模板还包括以下操作:
11、一些构建在开源基础模型llama之上的强大的开源大语言模型,例如alpaca和vicuna,表现出与闭源大语言模型相媲美的性能。由于希望所提方法能够更容易被大多数研究人员使用,因此本发明选择开源大语言模型作为本发明的主要研究对象。
12、受到知识驱动的视觉问答中的pica和prophet的启发,多模态关系抽取的完整提示模板由一些上下文示例以及一个测试输入组成,用于输入大语言模型以生成辅助知识;将测试输入x格式化为:
13、text:t
14、image:v
15、question:q
16、answer:
17、其中,t、v和q代表特定的测试输入,v为二进制格式。每个上下文示例ci均以相似的模板定义,如下所示:
18、text:ti
19、image:vi
20、question:qi
21、answer:ai
22、其中,ti、vi、qi和ai分别指的是从人工预定义样本中检索到的文本-图像-问题-答案四元组。
23、对于何种辅助知识能够提升模型性能,本发明尝试了两种不同的方案。第一种方案采用了与现有大多数方法相似的方式,直接让大语言模型生成实体关系的预测结果。由于mnre数据集中实体关系的类别多达23种,所以通过上下文少样本学习进行实体关系预测的结果并不理想。实际上,关系抽取任务本质上包含两个关键子任务:首先是判别文本中两个实体的类型,其次是确定这两个实体之间的关系。考虑到这一点,本发明尝试了第二种方案,即先让大语言模型生成与实体类型相关的辅助知识,然后在下一阶段使用该辅助知识进行实体关系的预测。通过人工对两种方案生成的辅助知识进行分析,本发明认为第二种方案所产生的辅助知识更为准确和可靠。
24、使大语言模型在多模态关系抽取任务中表现更好的关键不仅在于任务的设计,还在于选择合适的上下文示例。获取既能准确反映数据集标注风格又提供额外辅助知识的上下文示例是一个显著的挑战,而从原始数据集中直接获取这些示例是不切实际的。为了解决这个问题,本发明采用了随机抽样的方法,从训练集中选择了一小部分样本进行人工注释。人工注释时需要对句子中的两个实体的类型进行了判断,并同时提供相关的辅助知识作为做出此类判断的依据,辅助知识应包含图像、文本内容以及相关先验知识。通过以上注释方式,可以更好地指导大语言模型生成最相关和有价值的回答。
25、大语言模型的少样本学习能力在很大程度上会受到上下文示例的影响。因此,本发明设计了一个多模态相似示例检测模块,以确保选取到合适的上下文示例。在多模态关系抽取这一典型任务中,预测结果取决于如何融合文本和视觉信息。因此,本发明将文本和图像的融合特征相似度用作评估相似示例的主要标准。值得注意的是,这种多模态融合特征可以从已有的多模态预训练模型中获取。
26、优选的,步骤2中融合特征的获取,具体操作包括:
27、多模态预训练模型由多模态编码器f和适用于不同下游任务的解码器组成,其中多模态编码器f包括视觉编码器、文本编码器和多模态融合模块;通过多模态编码器f,图像—文本输入对被编码成多模态融合特征h:
28、h=f(t,v) (2)
29、首先计算每个人工预定义样本与输入样本间的融合特征之间的余弦相似度,然后选择余弦相似度最高的n个人工预定义样本作为上下文示例;上下文示例c的定义如下:
30、
31、c={(tj,vj,yj)|j∈i} (4)
32、其中,i是人工预定义样本中前n个相似样本的集合,t、v和y是指文本、图像和原始标签;在获得上下文示例c后,结合测试输入构建一个完整的启发式增强提示,以利用大语言模型的少样本学习能力进行实体类型判断。
33、优选的,步骤3中预测原始文本中两个实体间的关系具体包括:
34、由大语言模型通过上下文学习生成的辅助知识为z={z1,…,zm},将辅助知识与原始文本t={t1,…,tn}连接起来得到[t;z];为了判断实体关系,首先使用特殊标记将需要评估关系的两个实体包裹起来,同时在文本两端和两段文本之间插入分类标记[cls]和分隔符标记[sep],接着将其输入transformer编码器中:
35、{h[cls],h1,…,hn,h[sep],hn+1…,hn+m,h[sep]}=e(addtoken([t;z])) (5)
36、由于辅助知识中已经包含了对应图像的文字描述,而分类标记的特征向量h[cls]通过transformer的注意力机制涵盖了辅助知识z的相关线索,因此无需再直接与原始图像特征进行融合,避免了冗余信息的引入;将h[cls]输入到由全连接层和softmax分类层组成的解码器中,该层定义了给定输入句子t时,句子中两个实体间存在关系y的概率:
37、
38、最后,通过最小化负对数似然损失对transformer编码器和全连接层解码器的参数进行微调:
39、
40、其中,m表示训练集的样本数量。
41、本发明具有如下优点:通过手动标注有限样本并利用相似度检测模块选择相关实例,并将其集成到为多模态关系抽取任务定制的多模态提示模板中,接着将其输入大语言模型以引入相关知识。通过这种方式,plfm成功地克服了以前方法的限制,包括对外部知识的依赖以及会从知识库中检索到冗余信息。最终,在将大语言模型生成的高质量辅助知识与原始文本结合并输入到下游关系抽取模型后,模型性能取得了显著的提升。
- 还没有人留言评论。精彩留言会获得点赞!