数据解析方法、装置、计算机设备及存储介质与流程
本发明涉及数据存储,具体涉及一种数据解析方法、装置、计算机设备及存储介质。
背景技术:
1、本发明涉及到数据中心对于数据进行管理的领域。随着移动互联网和智能终端的普及,信息技术与经济社会的融合,引发了数据迅猛增长。面对海量的数据,数据中心如何高效地对数据进行管理显得尤为重要。
2、当前,数据中心接收到客户端采集的数据后,通过解析数据提取相应的数据标签,例如数据大小、数据类型以及数据特有的信息存入到数据库中,当数据的使用方需要数据时,通过数据标签请求自己想要的数据类型,再由数据中心将数据传送给使用方。然而,随着数据的增长,会增加新的数据源类型,每次增加新的数据源类型时,都需要对数据中心解析流程重新进行适配,不易于维护和扩展。当接收到不同数据源类型的数据时,将数据放到单一的解析队列中顺序执行解析,解析效率很低。
3、因此,相关技术存在接收到不同数据源类型的数据时,将数据放到单一的解析队列中顺序执行解析,解析效率很低的问题。
技术实现思路
1、有鉴于此,本发明提供了一种数据解析方法、装置、计算机设备及存储介质,以解决接收到不同数据源类型的数据时,将数据放到单一的解析队列中顺序执行解析,解析效率很低的问题。
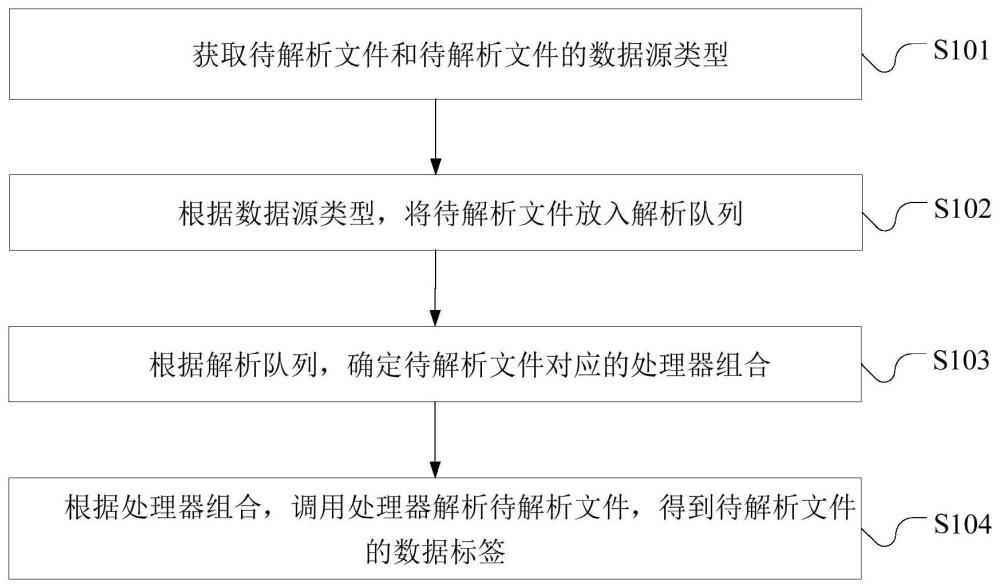
2、第一方面,本发明提供了一种数据解析方法,该方法包括:
3、获取待解析文件和待解析文件的数据源类型;
4、根据数据源类型,将待解析文件放入解析队列;
5、根据解析队列,确定待解析文件对应的处理器组合;
6、根据处理器组合,调用处理器解析待解析文件,得到待解析文件的数据标签。
7、本实施例提供的数据解析方法,数据接收模块接收客户端传输过来的待解析文件和数据源类型,根据数据源类型将待解析文件放到数据源类型对应的解析队列中,等待数据解析。数据预解析模块会监听解析队列,当有解析任务时,从解析队列中获取到待解析文件,匹配处理器组合并调用处理器对待解析文件进行解析,从待解析文件中提取相应的数据标签。以达到将不同数据源类型的文件放到不同的解析队列中,并交由不同的处理器组合进行解析,提高解析效率的效果。解决了相关技术存在接收到不同数据源类型的数据时,将数据放到单一的解析队列中顺序执行解析,解析效率很低的问题。
8、在一种可选的实施方式中,根据数据源类型,将待解析文件放入解析队列,包括:
9、获取数据库中每个数据源类型对应的解析队列,其中,每个解析队列对应一组用于解析文件的处理器;
10、将待解析文件的数据源类型与解析队列进行匹配,得到待解析文件对应的目标解析队列;
11、将待解析文件放入目标解析队列。
12、在本实施方式中,数据接收模块获取数据库中每个数据源类型对应的解析队列,将待解析文件的数据源类型与解析队列进行匹配,得到待解析文件对应的目标解析队列。使得数据预解析模块通过解析队列就能确定待解析文件的数据源类型,便于后续调用处理器。
13、在一种可选的实施方式中,方法还包括:
14、获取新增数据源类型,并确定已启用处理器;
15、判断已启用处理器能否解析新增数据源类型的文件;
16、如果已启用处理器能解析新增数据源类型的文件,则根据已启用处理器,生成新增数据源类型对应的新增处理器组合,并将新增处理器组合保存至数据中心的数据库;
17、如果已启用处理器不能解析新增数据源类型的文件,则获取新增处理器,并将新增处理器和已启用处理器组合,得到当前已启用处理器,其中,新增处理器用于解析新增数据源类型的文件;
18、根据当前已启用处理器,生成新增处理器组合,并将新增处理器组合保存至数据库。
19、在本实施方式中,当需要解析新增数据源类型的文件时,只需要将新增数据源类型和解析新增数据源类型文件所需要的解析器维护到数据库中。所需要的解析器如果已启用处理器中不存在,还可以新增处理器。便于后续对本发明进行维护和扩展,实现高效地管理数据:接收数据、解析数据、共享数据。
20、在一种可选的实施方式中,根据解析队列,确定待解析文件对应的处理器组合,包括:
21、根据解析队列对应的数据源类型和数据中心的数据库,确定数据源类型对应的处理器组合字符;
22、根据处理器组合字符、第一分隔符号以及第二分隔符号,得到处理器组合,其中,第一分隔符号用于确定处理器组合中处理器的并行关系,第二分隔符号用于确定处理器组合中处理器的串行关系。
23、在本实施方式中,先确定数据源类型对应的处理器组合字符;再根据处理器组合字符、第一分隔符号以及第二分隔符号,得到处理器组合中的处理器和处理器之间的并行、串行关系。便于后续调用处理器对待解析文件进行解析。
24、在一种可选的实施方式中,根据处理器组合,调用处理器解析待解析文件,得到待解析文件的数据标签,包括:
25、在数据源类型为第一类型的情况下,根据处理器组合字符和第一分隔符号,确定第一标签数据解析处理器和第二标签数据解析处理器;
26、将待解析文件加入第一标签数据解析处理器的第一任务队列和第二标签数据解析处理器的第二任务队列中;
27、基于第一任务队列,利用第一标签数据解析处理器对待解析文件进行解析,得到第一标签数据;
28、基于第二任务队列,利用第二标签数据解析处理器对待解析文件进行解析,得到第二标签数据;
29、将第一标签数据和第二标签数据进行标签组合,得到数据标签,并将数据标签保存至数据中心;
30、在数据源类型为第二类型的情况下,根据处理器组合字符、第一分隔符号以及第二分隔符号,确定第二标签数据解析处理器、第三标签数据解析处理器以及解压缩处理器;
31、将待解析文件加入解压缩处理器的第三任务队列和第二标签数据解析处理器的第二任务队列中;
32、基于第二任务队列,利用第二标签数据解析处理器对待解析文件进行解析,得到第四标签数据;
33、基于第三任务队列,利用解压缩处理器对待解析文件进行解压,得到解压后文件;
34、将解压后文件加入第三标签数据解析处理器的第四任务队列中;
35、基于第四任务队列,利用第三标签数据解析处理器对解压后文件进行解析,得到第三标签数据;
36、将第三标签数据和第四标签数据进行标签组合,得到数据标签,并将数据标签保存至数据中心。
37、在本实施方式中,先判断数据源类型为第一类型还是第二类型,针对不同类型调用不同的处理器,将待解析文件放到处理器的任务队列,交由不同的处理器组合进行解析,提高解析效率的效果。对不同处理器得到的解析结果进行标签组合,得到标签数据,完成对待解析文件进行解析。
38、在一种可选的实施方式中,在根据处理器组合,调用处理器解析待解析文件之后,方法还包括:
39、获取对待解析文件进行解析过程的参数,其中,参数包括利用解压缩处理器解压待解析文件所需的第一时间、解压后文件的总数、利用第三标签数据解析处理器解析每个解压后文件所需的第二时间以及利用第一标签数据解析处理器解析待解析文件所需的第三时间;
40、根据第一时间、第二时间以及第三时间,得到解压缩处理器的第一目标数量和第一标签数据解析处理器的第二目标数量;
41、根据第一时间、解压后文件的总数以及第二时间,得到第三标签数据解析处理器的第三目标数量;
42、根据第一目标数量、第二目标数量以及第三目标数量,调整已启用处理器的数量。
43、在本实施方式中,根据对待解析文件进行解析过程的参数,动态调整已启用处理器的数量,提高解析效率和服务器资源利用率。
44、在一种可选的实施方式中,在根据处理器组合,调用处理器解析待解析文件,得到待解析文件的数据标签之后,方法还包括:
45、获取客户端的数据请求;
46、将数据请求中的数据标签与数据中心保存的数据标签进行匹配,并根据匹配结果对数据中心保存的数据进行筛选,得到目标数据;
47、根据预设共享协议,将目标数据发送至客户端。
48、在本实施方式中,数据共享模块将数据请求中的数据标签与数据中心保存的数据标签进行匹配,得到目标数据,再通过预设共享协议将目标数据发送至客户端。使得数据使用方能够通过提供所需数据的数据标签,便可过滤出需要的目标数据,方便快捷。
49、第二方面,本发明提供了一种数据解析装置,该装置包括:
50、第一获取模块,用于获取待解析文件和待解析文件的数据源类型;
51、放入模块,用于根据数据源类型,将待解析文件放入解析队列;
52、确定模块,用于根据解析队列,确定待解析文件对应的处理器组合;
53、解析模块,用于根据处理器组合,调用处理器解析待解析文件,得到待解析文件的数据标签。
54、第三方面,本发明提供了一种计算机设备,包括:存储器和处理器,存储器和处理器之间互相通信连接,存储器中存储有计算机指令,处理器通过执行计算机指令,从而执行上述第一方面或其对应的任一实施方式的数据解析方法。
55、第四方面,本发明提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机指令,计算机指令用于使计算机执行上述第一方面或其对应的任一实施方式的数据解析方法。
- 还没有人留言评论。精彩留言会获得点赞!