一种基于多层次交互的多模态情感识别方法
本发明涉及自然语言处理、深度学习、信号处理等领域,尤其是情感识别技术。具体而言,本发明提出一种基于多层次交互的多模态情感识别方法,通过多层次交互,充分挖掘语音和文本在不同细粒度级别的情感相关性,从而提高情感识别的准确性。
背景技术:
1、情感识别(emotion recognition,er)是判断某段信息所表达的情感。随着人工智能的发展,情感识别越来越受到重视。它在人机交互,测谎仪,医疗保健等方面有重要的应用。在人机交互方面,情感识别可以使机器自动识别人类的情感,提高用户体验。在审讯场景中,情绪识别可以辅助分析一个人的情绪变化,判断他是否在说谎。在情感识别领域,已经应用了多种模态,包括语音、面部表情、文本内容、生理信号和脑电图。许多研究人员致力于从这些模态中的一种来提高情感识别的性能。然而,由于单一模态所表达的情感的模糊性,这仍然是一个挑战。例如,一个话语可能包含情绪化的语调表达,这是无法通过单独的语音转录来捕捉的。由于人类通常同时通过多种模态来表达情感,因此多模态信息被用来提高性能。多种形式可以联合提供比单一形式更有价值的信息。例如,当通过语音表达的情感模棱两可时,该语音的文本内容可以提供能够减轻该不明确性的补充信息。因此多模态情感识别越来越受到大家的重视。
2、多模态情感识别需要融合不同模态之间的信息,将不同模态的信息进行互补。语音和文本情感识别的融合策略大致可分为三种。第一种是决策融合,在这种方法中,每个模态都进行情感预测,再由决策融合作出最终预测,但这种方法没有考虑模态间的相互作用。第二种是特征串联,提取不同模态的原始特征,然后连接成新特征,这个新特征被输入到一个模型中以获得最终的预测结果,但只使用一个模型会导致每个模态不能使用最适合自己的模型。第三种是嵌入交互,该方法每种模态都有自己的模型,以获得每个模态的嵌入,再进行嵌入的融合。但是嵌入级别的交互粒度相对较大,不能在更细粒度的细节中捕获模态的相关性。此外,由于语音和文本数据的采集方式,数据处理方式不同,他们在时间上是不对齐的,这使得很难在更细粒度的细节上进行模态之间的交互,一般需要添加强制对齐来解决。强制对齐是指将语音分成连续的片段,每个片段对应文本中一个单词的发音。一般来说,强制对齐需要知道每个单词的精确间隔,也就是需要预先获得每个单词对应语音的位置信息。但是由于许多数据没有预先准备的对齐信息,这种对齐方法应用起来有很大的局限性。
技术实现思路
1、本发明针对目前语音文本多模态情感识别技术中,由于不同模态在时间和语义上是不对齐的,导致难以实现不同模态细粒度级别的交互的问题,提出了一种基于多层次交互的多模态情感识别方法。该方法通过帧级别交互将片段中的语音帧与相应的文本单词进行自动对齐而不需要强制对齐,通过交互式transformer实现帧级别、词级别、句子级别的模态交互,充分挖掘语音和文本在不同细粒度级别的情感相关性,提高多模态情感识别的准确率。
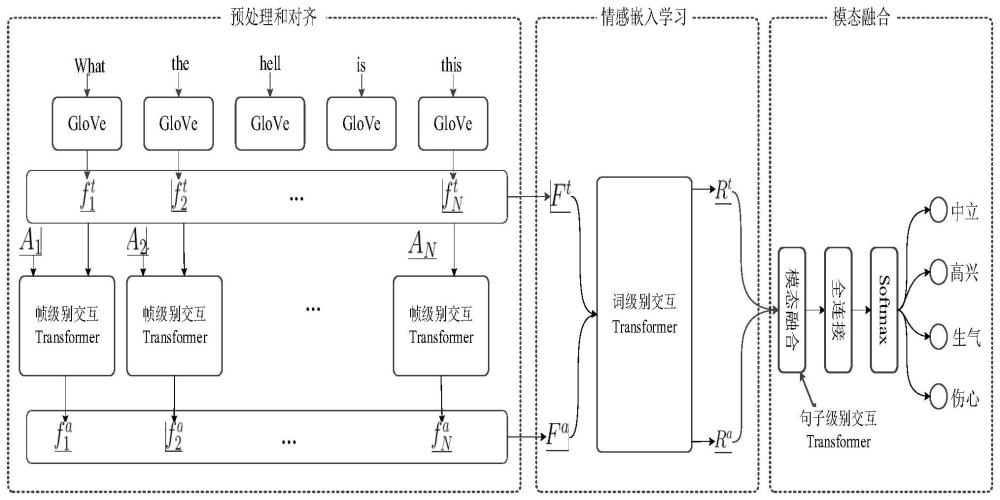
2、本发明提出了一种基于多层次交互的多模态情感识别方法,其特征在于分为三个步骤:1)预处理和对齐、2)情感嵌入学习、3)模态融合。预处理和对齐:对语音信号和文本信号的预处理,实现语音和文本信号的帧级别交互与对齐。情感嵌入学习:采用词级别交互transformer,学习文本模态和语音模态词级别的情感嵌入。模态融合:对提取的词级别嵌入进行融合,得到句子级别的情感嵌入,最后通过句子级别的情感嵌入获得最终的预测。具体步骤如下:
3、1)预处理和对齐
4、1.1)预处理
5、对于文本模态,对每个单词提取它的glove向量。给定具有n单词的句子,最终的glove向量组成词级别的文本特征其中,是第n个单词的glove向量。
6、对于语音模态,利用汉明窗进行分帧。提取log-mel谱(lms)作为语音特征。对于总共有tl帧和n个单词的一段语音,将其lms特征划分为n个片段。第n个片段的中间帧是
7、
8、其中表示将值向上取值到下一个整数。以中间帧为中点,每段的长度为l,并且
9、
10、其中r是整数,用于调整每个片段的长度。r的取值范围为1、2、3。当r>1时,表示片段之间有重叠。如果一个片段的位置超出了语音的范围,它将被零填充。第n个片段的lms特征被表示为矩阵an。
11、1.2)使用帧级别交互transformer进行帧对齐
12、由于时间的先后顺序,第n个片段包含第n个单词的发音帧的概率较高。因此,将第n个片段的帧与第n个单词的glove向量进行交互,学习每个帧与单词向量之间的相关性,从而实现对齐。通过对齐结果,可以获得语音词级别特征。具体如下:
13、将第n个片段的lms特征an和第n个单词的glove向量输入到帧级别交互transformer。在帧级别交互transformer中,an首先输入到transformer编码器以得到第n个片段对应的优化后的语音特征a′n。由于每个片段具有l个帧,a′n可以由l个向量表示,
14、
15、其中表示第n个片段中第l帧的优化后的语音特征向量。
16、通过注意力机制来实现文本模态和语音模态在帧级别的交互。注意力机制中的key和value来自语音模态,而queryqn来自文本模态。是将优化后的语音特征通过矩阵wk作线性变换得到的,是将优化后的语音特征通过矩阵wv作线性变换得到的,和的计算公式为
17、
18、
19、其中wk和wv为线性变换矩阵。qn是将第n个单词的glove向量通过矩阵wq做线性变换得到的,即
20、
21、经过上述线性变换得到qn,以便计算和之间的相关性。在模型训练阶段wk、wv、wq随机初始化的,模型训练时进行参数更新,模型训练完毕后保持不变。第n个片段的第l帧和第n个单词的相关性为
22、
23、其中dk是的维数,t表示转置。越大,第n个单词与第n个片段的第l帧越相关。反映了语音帧和单词之间的对齐。通过这个对齐结果,第n个语音片段的词级别的语音特征可以计算为
24、
25、最后,整条语音的词级别的语音特征表示为
26、2)情感嵌入学习
27、本步骤将步骤1)得到的词级别的文本特征ft和词级别的语音特征fa输入到词级别交互transformer中,提取文本的词级别情感嵌入rt和语音的词级别情感嵌入ra。
28、采用词级别交互transformer来学习文本模态和语音模态所有词级别特征之间的相关性。首先和传统transformer一样,对词级别的文本特征ft和词级别的语音特征fa进行位置编码分别得到带位置信息的词级别文本特征和带位置信息的词级别语音特征接着进行线性变换以获得文本模态的keykt和valuevt,以及语音模态的keyka和valueva,即
29、
30、文本和语音两种模态的query共享,表示成qs,通过以下公式获得
31、
32、qs包含来自文本和语音的词级别信息。上述都是transformer模型的参数,用来对作线性变换得到文本模态的value,用来对作线性变换得到文本模态的key,用来对作线性变换得到语音模态的value,用来对作线性变换得到文本模态的key,用来对和作线性变换得到两种模态共享的query。在模型训练阶段是随机初始化的,模型训练时进行参数更新,模型训练完毕后该参数保持不变。
33、对于文本模态,通过注意力机制可以得到文本模态的输出
34、
35、其中t表示矩阵的转置,dk表示kt的第一维维数。和传统transformer一样,将与输入到残差网络后得到其中ln表示做归一化。残差网络就是进行相加和归一化操作,没有参数。再将该结果输入到文本模态的全连接网络和残差网络从而获得文本词级别情感嵌入rt为
36、
37、是文本模态的全连接网络的参数矩阵,模型训练阶段随机初始化,模型训练时进行参数更新,模型训练完毕后该参数保持不变。rt是和语音词级别特征交互后得到的文本词级别情感嵌入,rt中的第n列表示第n个词的情感嵌入。
38、类似地,对于语音模态可以得到
39、
40、经过语音模态的全连接网络和残差网络的处理得到语音词级别情感嵌入ra为
41、
42、是语音模态的全连接网络的参数矩阵,模型训练阶段随机初始化,模型训练时进行参数更新,模型训练完毕后该参数保持不变。ra是和文本词级别特征交互后得到的语音词级别情感嵌入,ra中的第n列表示第n个语音片段的情感嵌入。
43、3)模态融合
44、上述步骤通过词级别交互transformer,得到了文本词级别情感嵌入rt和语音词级别情感嵌入ra。为了提取句子级别的情感嵌入,采用模态融合,在句子级别学习不同模态之间的相互作用。
45、首先,将文本词级别情感嵌入rt和语音词级别情感嵌入ra进行拼接得到总的情感嵌入r,也就是
46、
47、将r输入到transformer编码器中得到融合后的词级别情感嵌入r′=[r′1,…,r′n,…,r′n],其中r′n表示第n个词和第n个语音片段融合后的情感嵌入。再通过平均池化得到最终的句子级别情感嵌入向量其中e[r′]和e[r′]分别表示对融合后的词级别情感嵌入求数学期望和方差,具体计算如下:
48、
49、
50、最后,使用模态融合后的全连接层和softmax函数进行最终的情感分类,得到最终的属于各个情感的概率为:
51、p=softmax(wre)
52、w是模态融合后的全连接层的参数,模型训练阶段随机初始化,模型训练时进行参数更新,模型训练完毕后该参数保持不变。softmax函数和传统softmax函数是一样的,没有参数,用来使预测的属于各个类别的概率值为非负数,并且属于各个类别的概率之和等于1。
53、在模型训练时,使用带情感标签的文本和语音数据作为训练数据对模型进行训练。将训练数据中每个句子对应的文本和语音数据进行步骤1)2)3)处理后得到模型预测的情感输出。不断对模型参数进行更新,直至模型收敛,得到训练好的模型。模型训练完后,保持模型参数不变,在进行情感识别时,将输入语音和文本进行步骤1)2)3)的处理,即可得到情感识别的结果。
54、本发明的有益效果如下:
55、本发明提出一种基于多层次交互的多模态情感识别方法,在帧级别、词级别和句子级别交互语音和文本模态,实现多层次交互,并在不同的细粒度级别上充分探索文本和语音之间的情感相关性。此外,本发明在帧级别引入文本信息,并使用注意力机制来自动学习语音和文本之间的对齐,避免了人工强制对齐的繁琐过程。本发明通过自动对齐和多层次交互提高多模态情感识别的性能。
- 还没有人留言评论。精彩留言会获得点赞!