一种基于进化策略生成细微扰动的黑盒决策攻击方法
本技术涉及黑盒对抗攻击,特别涉及一种基于进化策略生成细微扰动的黑盒决策攻击方法。
背景技术:
1、近年来,深度神经网络模型在各种应用中取得了巨大的成功。然而,最近的研究表明深度神经网络极易受到对抗样本的攻击。攻击者将精心生成的微小扰动添加到原始图像中,从而生成对抗样本。这些对抗样本很难被人眼识别,但会导致深度神经网络产生错误的预测。特别是在人脸识别系统中,深度神经网络对这些对抗样本极为敏感。例如,攻击者可以使用攻击算法生成的眼镜来逃避模型的识别或冒充另一个人。因此,深度神经网络模型在现实应用中会存在相应的安全隐患。
2、为了评估深度神经网络的鲁棒性,我们可以使用对抗攻击算法生成的对抗样本来有效地识别模型中的漏洞,并将这些对抗样本加入神经网络中进行对抗性训练,以提高模型的鲁棒性。对抗攻击方法可分为白盒攻击和黑盒攻击两种类型。在白盒攻击中,攻击者能够获取目标模型的内部结构和参数,因此通常可以使用基于梯度的方法来优化目标函数,从而生成对抗样本。而在黑盒攻击中,攻击者无法获取目标模型的参数和结构,只能通过查询目标模型并根据返回的标签来实施攻击。由于黑盒攻击方法更贴近实际应用场景,因此研究者们对其进行了深入研究和探索。
3、主流的黑盒攻击方法包括基于迁移的攻击、基于零阶优化的攻击和基于决策的攻击方法。其中,基于迁移的攻击方法利用已攻击模型的知识和生成的对抗样本来欺骗新模型,使其产生错误的预测。这种方法可以节省攻击过程中的查询时间和计算资源,并且能够绕过目标模型的防御机制,具有一定的攻击优势。然而,由于大部分深度神经网络模型具有不同的架构和参数设置,因此迁移攻击的成功率并不高。鉴于这一情况,后续的研究主要集中在对目标模型本身进行攻击,采用基于零阶优化的攻击方法和基于决策的攻击方法对攻击问题进行研究。
4、基于零阶优化的攻击方法是通过优化对抗样本的特征或像素值来最小化目标模型的输出误差。这种方法不需要了解目标模型的内部结构和参数,而是基于模型的输出来进行优化。如果攻击者在查询的过程中能够获取模型输出每个类别的分数或者在攻击查询预算相对充足的情况下,可以使用零阶优化方法生成对抗样本。
5、在更为严格的黑盒攻击场景中,攻击者仅通过查询目标模型的预测标签来获取信息,无法获得其他有效的数据。为了应对这种复杂的攻击场景,研究者提出了基于决策的黑盒攻击方法,该方法是利用目标模型的输出信息来指导对抗样本的生成。攻击者通过不断调整对抗样本的特征,使目标模型产生特定的错误决策。
技术实现思路
1、鉴于上述问题,本发明的目的在于提供一种基于进化策略生成细微扰动的黑盒决策攻击方法,该方法能够在严格的黑盒决策攻击场景中高效地生成对抗样本,并且生成的对抗样本具有较低的l2范数。
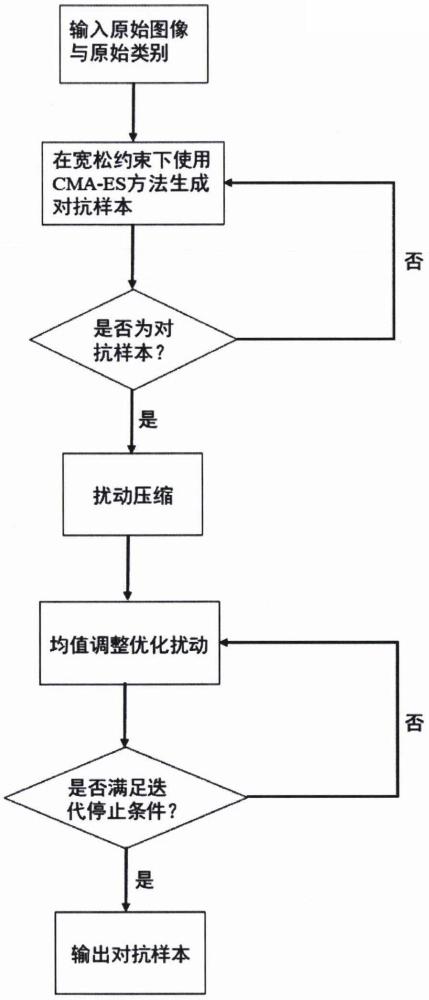
2、技术方案:本发明的黑盒决策对抗攻击方法包括如下步骤:
3、(1)首先建立目标函数,将决策攻击问题重新表述为无约束优化问题;
4、(2)从原始图像出发,使用进化策略在宽松约束的条件下快速跨越决策边界找到具有较大扰动的对抗样本;
5、(3)在获得扰动较大的对抗样本后,通过扰动压缩方法减小采样空间,提高后续算法的效率;
6、(4)利用原始图像引导算法的搜索方向;
7、(5)记录搜索过程中失败的采样与失败的采样数;
8、(6)根据失败的采样进一步调整进化策略分布的均值;
9、(7)满足迭代停止条件,生成具有细微扰动的对抗样本。
10、进一步,所述步骤(1)的具体实现步骤如下:
11、(s11)决策攻击的目标是寻找高质量的对抗样本xadv,使得xadv尽可能与原始图像x相似,同时分类器将样本从正确的类别c错分到其他类别:
12、min||xadv-x||p,s.t.d(xadv)≠c
13、(s12)由于在攻击中无法计算softmax层的概率,因此我们定义决策改变分数i(·)来衡量模型决策的变化程度以生成对抗样本:
14、
15、其中,θi是生成的扰动。当添加扰动后分类不正确时,否则
16、(s13)结合(s11)和(s12),进一步将基于决策攻击问题的目标函数重新表述为无约束优化问题:
17、
18、当对抗样本xadv被错误分类时,i(xadv)的值为0,因此我们的目标就是优化上式。
19、进一步,所述步骤(2)的具体实现步骤如下:
20、(s21)通过进化策略寻找具有较大扰动的对抗样本时,使用无穷范数攻击p=∞并且将ε设置为0.3;
21、(s22)在算法的每一次迭代中从n(θt,σt2ct)产生λ个解:
22、x′=θt+σtzi,zi∈n(0,ct)
23、其中,协方差矩阵搜索分布的均值为θt,σt为标准差,zi为搜索方向;
24、(s23)对新产生的解计算相应的目标函数值l(x′i),并根据目标函数值进行排序:
25、l(x′1:λ)≤l(x′2:λ)≤…≤l(x′λ:λ)
26、(s24)选择排名靠前的解进行分布参数的更新,其中分布均值的更新定义如下:
27、
28、ωi为权重系数,x′1:λ表示来自x1,x2,…,xλ的第i个最佳个体;
29、(s25)接下来更新进化策略的协方差矩阵:
30、
31、ct+1为协方差矩阵,学习率pt+1为搜索方向,也称为进化路径;
32、(s26)最后,更新进化策略的步长:
33、
34、在平稳性条件下有st+1~n(0,i),即搜索路径可以看作是一个n维标准正态分布的随机向量;
35、结合(s21)~(s26)步骤可以生成具有较大扰动的对抗样本。
36、进一步,所述步骤(3)的具体实现步骤如下:
37、(s31)如果当前对抗样本中的某个区域扰动幅度较小,则可以认为该区域对扰动不太敏感。因此,在后续的采样过程中,只需要对扰动幅度较大的像素进行调整:
38、
39、
40、其中,是θ*中具有最大值的像素集合,φ是和θ*中像素数的比值,根据比值φ选择θ*中绝对值最大的像素。这个选择过程确保了最具影响力的像素被选择,过滤了对扰动敏感度较低的区域;
41、(s32)获得扰动压缩后的对抗样本。
42、进一步,所述步骤(4)的具体实现步骤如下:
43、(s41)从扰动压缩后的对抗样本开始,获得采样分布的均值;
44、(s42)利用原始图像引导当前分布均值进行移动,使得采样的解更靠近原始图像。
45、进一步,所述步骤(5)的具体实现步骤如下:
46、(s51)记录失败的采样数为k;
47、(s52)记录失败采样的解为
48、进一步,所述步骤(6)的具体实现步骤如下:
49、(s61)为了减少失败的查询,通过历史的采样记录来调整下一个样本的分布均值:
50、
51、
52、其中,分布均值是所选μ个解的最大似然估计,k表示当前对抗样本中失败的采样总数,qk保存了所有失败的采样。在迭代过程中,我们记录对抗样本的采样历史,并将当前所有失败样本保存下来。
53、进一步,所述步骤(7)满足以下迭代停止条件时,则输出对抗样本,具体步骤如下:
54、(s71)当查询次数超出设定的最大次数时,停止迭代;
55、(s72)当迭代的步长极小时,停止迭代输出对抗样本;
56、(s73)当成功搜索到的对抗样本满足细微扰动的条件时停止迭代,输出对抗样本。
57、由上可见,本发明提供了一种基于进化策略生成细微扰动的黑盒决策攻击方法,该方法首先使用进化策略在宽松约束下得到扰动较大的对抗样本,接着通过扰动压缩方法减小采样空间进一步提高后续算法的效率,最后,利用原始图像引导算法搜索方向,并结合均值调整优化策略记录失败采样的历史信息,避免大量无效查询的情况。本发明与现有技术相比,其显著效果如下:1.在最为严格的黑盒决策攻击场景中,本发明以较少的查询次数成功生成对抗样本,可以更好地适用于真实世界的攻击场景;2.通过扰动压缩与均值调整方法可以生成接近于原始图像的对抗样本,从而更好地逃避人眼与防御系统的检测;3.通过分布采样生成大量靠近原始图像的对抗样本,这些对抗样本可以与dnn模型的对抗训练相结合,进一步提高模型的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!