网络训练及数字人动画驱动方法、装置、设备及介质与流程
本技术实施例涉及数字媒体处理领域,具体而言,涉及一种网络训练及数字人动画驱动方法、装置、设备及介质。
背景技术:
1、随着虚拟现实、增强现实和视频内容制作技术的飞速发展,数字人的应用越来越广泛,尤其是在娱乐、新闻主播、虚拟教育以及视频会议等领域。在传统的动画产业中,由于高品质3d动画制作通常需要昂贵的资源和时间,这限制了其应用范围。特别是在实时或近实时的场景中,3d动画的生成往往要面临巨大的挑战。
2、在3d数字人的面部驱动领域,嘴部动画的真实性对于整体表情的自然度起着至关重要的作用。嘴型的准确同步是实现高质量面部动画的核心,尤其在配合语音时。遗憾的是,现有技术解决方案仍存在限制。例如,3d面部动画通常依靠复杂的形态目标(morphtargets)或基于捕捉的运动数据来产生动画,这不仅开销巨大,而且增加了动画流程的复杂性。
3、此外,传统的2d面部动画生成方法依赖于手工制作或半自动的软件工具,效率低下且可扩展性有限。虽然近年来机器学习和深度学习在此领域取得了进展,如利用生成对抗网络(generative adversarial networks,gan)进行面部表情的仿真,但这些方法通常需要大量的训练数据和高性能的计算资源,而且往往缺乏对嘴巴内部复杂动态的精细控制。
技术实现思路
1、本技术实施例的目的在于提供一种网络训练及数字人动画驱动方法、装置、设备及介质,能够降低传统3d建模所需的高昂渲染成本,并提高数字人面部动画的生成效率和自然度。
2、为了实现上述目的,本技术实施例采用的技术方案如下:
3、第一方面,本技术实施例提供了一种网络训练方法,所述方法包括:
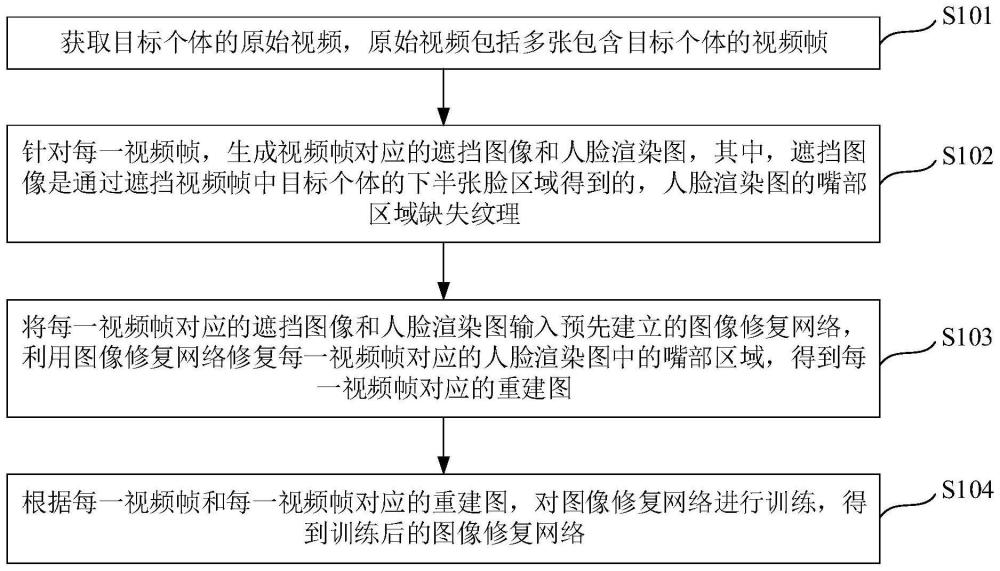
4、获取目标个体的原始视频,所述原始视频包括多张包含目标个体的视频帧;
5、针对每一所述视频帧,生成所述视频帧对应的遮挡图像和人脸渲染图,其中,所述遮挡图像是通过遮挡所述视频帧中目标个体的下半张脸区域得到的,所述人脸渲染图的嘴部区域缺失纹理;
6、将每一所述视频帧对应的遮挡图像和人脸渲染图输入预先建立的图像修复网络,利用所述图像修复网络修复每一所述视频帧对应的人脸渲染图中的嘴部区域,得到每一所述视频帧对应的重建图;
7、根据每一所述视频帧和每一所述视频帧对应的重建图,对所述图像修复网络进行训练,得到训练后的图像修复网络。
8、可选地,生成所述视频帧对应的人脸渲染图的步骤,包括:
9、获取所述视频帧中目标个体的人脸特征信息;
10、根据所述视频帧中目标个体的人脸特征信息,生成所述视频帧中目标个体的人脸纹理贴图;
11、对所述视频帧中目标个体的人脸纹理贴图进行渲染,并在渲染过程中去除目标个体嘴部区域的纹理,得到所述视频帧对应的人脸渲染图,所述人脸渲染图具有与所述视频帧中的目标个体一致的表情和头部姿态且嘴部区域缺失纹理。
12、可选地,所述人脸特征信息包括人脸几何形状、人脸表情和人脸姿态;
13、所述获取所述视频帧中目标个体的人脸特征信息的步骤,包括:
14、将所述视频帧输入预设的人脸特征提取模型,得到所述视频帧中目标个体的人脸几何形状、人脸表情和人脸姿态。
15、可选地,所述人脸特征信息包括人脸几何形状、人脸表情和人脸姿态;
16、所述根据所述视频帧中目标个体的人脸特征信息,生成所述视频帧中目标个体的人脸纹理贴图的步骤,包括:
17、利用所述视频帧中目标个体的人脸几何形状、人脸表情和人脸姿态进行三维重建,得到所述视频帧中目标个体的三维人脸模型;
18、对所述视频帧和所述三维人脸模型进行纹理映射,生成所述视频帧中目标个体的人脸纹理贴图。
19、可选地,所述根据每一所述视频帧和每一所述视频帧对应的重建图,对所述图像修复网络进行训练,得到训练后的图像修复网络的步骤,包括:
20、将每一所述视频帧作为正样本、将每一所述视频帧对应的重建图作为负样本,输入预设的判别器,得到判别结果;
21、根据所述判别结果和所述判别器对应的损失函数,计算所述判别器的损失值;
22、根据每一所述视频帧、每一所述视频帧对应的重建图、所述判别器的损失值以及所述图像修复网络对应的损失函数,计算所述图像修复网络的损失值;
23、根据所述判别器的损失值和所述图像修复网络的损失值,分别利用反向传播算法反复交替优化所述判别器和所述图像修复网络的参数,并在达到精度要求或者预设迭代次数后,将所述图像修复网络的参数固定,得到训练后的图像修复网络。
24、第二方面,本技术实施例还提供了一种数字人动画驱动方法,所述方法包括:
25、获取目标个体的原始视频,所述原始视频包括多张包含目标个体的视频帧;
26、获取每一所述视频帧对应的遮挡图像,所述遮挡图像是通过遮挡所述视频帧中目标个体的下半张脸区域得到的;
27、基于为每一所述视频帧预先设定的特定表情系数,生成每一所述视频帧对应的特定人脸渲染图,所述特定人脸渲染图的嘴部区域缺失纹理;
28、将每一所述视频帧对应的遮挡图像和特定人脸渲染图输入利用上述的网络训练方法训练后的图像修复网络,以修复每一所述视频帧对应的特定人脸渲染图中的嘴部区域,得到包括每一所述视频帧对应的特定重建图的重建视频;
29、其中,所述特定重建图中的目标个体具有与其关联的所述特定表情系数所表征的表情,所述重建视频反映全部特定表情系数所表征的表情变化。
30、第三方面,本技术实施例还提供了一种网络训练装置,所述装置包括:
31、第一获取模块,用于获取目标个体的原始视频,所述原始视频包括多张包含目标个体的视频帧;
32、第一生成模块,用于针对每一所述视频帧,生成所述视频帧对应的遮挡图像和人脸渲染图,其中,所述遮挡图像是通过遮挡所述视频帧中目标个体的下半张脸区域得到的,所述人脸渲染图的嘴部区域缺失纹理;
33、修复模块,用于将每一所述视频帧对应的遮挡图像和人脸渲染图输入预先建立的图像修复网络,利用所述图像修复网络修复每一所述视频帧对应的人脸渲染图中的嘴部区域,得到每一所述视频帧对应的重建图;
34、训练模块,用于根据每一所述视频帧和每一所述视频帧对应的重建图,对所述图像修复网络进行训练,得到训练后的图像修复网络。
35、第四方面,本技术实施例还提供了一种数字人动画驱动装置,所述装置包括:
36、第二获取模块,用于获取目标个体的原始视频,所述原始视频包括多张包含目标个体的视频帧;获取每一所述视频帧对应的遮挡图像,所述遮挡图像是通过遮挡所述视频帧中目标个体的下半张脸区域得到的;
37、第二生成模块,用于基于为每一所述视频帧预先设定的特定表情系数,生成每一所述视频帧对应的特定人脸渲染图,所述特定人脸渲染图的嘴部区域缺失纹理;
38、图像修复模块,用于将每一所述视频帧对应的遮挡图像和特定人脸渲染图输入利用上述的方法训练后的图像修复网络,得到包括每一所述视频帧对应的特定重建图的重建视频;
39、其中,所述特定重建图中的目标个体具有与其关联的所述特定表情系数所表征的表情,所述重建视频反映全部特定表情系数所表征的表情变化。
40、第五方面,本技术实施例还提供了一种电子设备,包括处理器和存储器,所述存储器用于存储程序,所述处理器用于在执行所述程序时,实现上述第一方面中的网络训练方法,和/或,上述第二方面中的数字人动画驱动方法。
41、第六方面,本技术实施例还提供了一种计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述第一方面中的网络训练方法,和/或,上述第二方面中的数字人动画驱动方法。
42、相对现有技术,本技术实施例供的一种网络训练及数字人动画驱动方法、装置、设备及介质,在训练预先建立的图像修复网络时,首先,获取多张包含目标个体的视频帧,并针对每一视频帧,生成对应的遮挡图像和人脸渲染图,遮挡图像是通过遮挡所述视频帧中目标个体的下半张脸区域得到的,人脸渲染图的嘴部区域缺失纹理;然后,将每一视频帧对应的遮挡图像和人脸渲染图输入预先建立的图像修复网络,利用图像修复网络修复每一视频帧对应的人脸渲染图中的嘴部区域,得到每一视频帧对应的重建图;最后,将每一视频帧作为标签,结合每一视频帧对应的重建图对图像修复网络进行训练,得到训练后的图像修复网络。这样,在利用训练后的图像修复网络进行数字人动画驱动时,能够准确地重建嘴部图像,实现动态、逼真的2d数字人面部动画,从根本上简化面部动画的制作流程,不仅减少了生成过程中的渲染成本和时间,也提高了数字人面部动画的自然度和表情的准确性。
- 还没有人留言评论。精彩留言会获得点赞!