面向低空安防场景的跨模态视觉定位方法
本技术实施例涉及视觉定位,特别涉及一种面向低空安防场景的跨模态视觉定位方法。
背景技术:
1、视觉定位是指通过分析图像或视频数据,确定相机、摄像头或传感器在现实世界中的位置(通常是三维坐标)和方向(通常是姿态或角度)的过程。视觉定位技术在无人驾驶、增强现实、智能导航等领域中发挥着重要的作用。传统的视觉定位方法主要依赖于特征点匹配和几何学模型,但在复杂场景、光照变化和遮挡等条件下,传统的视觉定位方法容易受到限制,无法满足高精度定位的要求。
2、近年来,深度学习技术的快速发展为视觉定位带来了新的机遇,基于深度学习的视觉定位方法能够利用卷积神经网络等深度学习模型,直接从图像数据中学习特征表示,具有更好的鲁棒性和泛化能力。但目前的基于深度学习的视觉定位方法在实际应用中仍然存在定位精度不高、实时性不足的问题。
3、目前点云地图中的视觉定位方法主要依赖于点云和图像匹配,比如基于2d-3d匹配的视觉定位方法。有一些方法则依靠点云和图像中的重叠场景来设计点云和图像匹配方法,比如基于特征的密集对应框架的点云和图像匹配方法。还有一些方法利用图像检索来完成大型点云中的视觉定位工作,比如移动传感器引导的跨时节六自由度视觉定位方法。然而,本技术的发明人发现,上述方法在处理大型密集点云数据时,均存在视觉定位精度较低,视觉定位速度较慢,无法满足实时视觉定位需求的问题。
技术实现思路
1、本技术实施例的目的在于提供一种面向低空安防场景的跨模态视觉定位方法,可以在大规模点云中快速实现精确的视觉定位,很好地满足了实时视觉定位的速度要求。
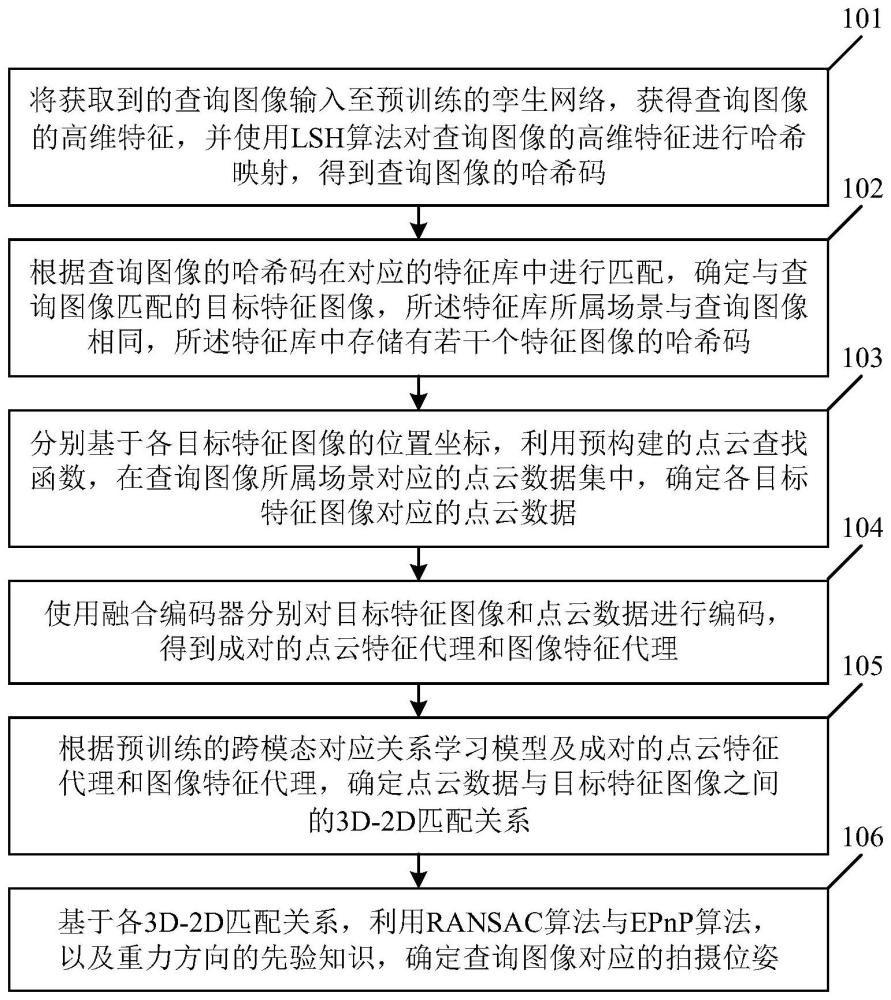
2、为解决上述技术问题,本技术的实施例提供了一种面向低空安防场景的跨模态视觉定位方法,包括以下步骤:将获取到的查询图像输入至预训练的孪生网络,获得所述查询图像的高维特征,并使用lsh算法(locality sensitive hashing,局部敏感哈希算法)对所述查询图像的高维特征进行哈希映射,得到所述查询图像的哈希码;根据所述查询图像的哈希码在对应的特征库中进行匹配,确定与所述查询图像匹配的目标特征图像;其中,所述特征库所属场景与所述查询图像相同,所述特征库中存储有若干个特征图像的哈希码;分别基于各所述目标特征图像的位置坐标,利用预构建的点云查找函数,在所述查询图像所属场景对应的点云数据集中,确定各所述目标特征图像对应的点云数据;分别对所述目标特征图像和所述点云数据进行编码,得到成对的点云特征代理和图像特征代理;根据预训练的跨模态对应关系学习模型及所述成对的点云特征代理和图像特征代理,确定所述点云数据与所述目标特征图像之间的3d-2d匹配关系;基于各所述3d-2d匹配关系,利用ransac算法(random sample consensus,随机抽样一致算法)与epnp算法,以及重力方向的先验知识,确定所述查询图像对应的拍摄位姿。
3、本技术的实施例提供的面向低空安防场景的跨模态视觉定位方法,通过从粗到细的图像到点云的跨模态学习,先建立点集(点云)和像素块(图像)之间的对应,再从点级和像素级上进行细化,实现高精确度的匹配关系预测,从而在大规模的点云数据中实现精确的视觉定位。视觉定位的过程中使用到的孪生网络、点云查找函数、融合编码器、跨模态对应关系学习模型使用了共享参数的图像特征提取器和点云特征提取器,这使得各模型的训练速度快,训练质量高,训练出的各模型的推理速度快,同时采用lsh算法,基于哈希码和特征库来进行相似图像的匹配,匹配出的目标特征图像的位置信息容易获取,从而使得对应的点云数据也能够快速获得,整个视觉定位的过程耗时短、速度快,非常适用于大规模点云数据的视觉定位,可以很好地满足需要进行实时视觉定位的使用场景。
4、在一些可选的实施例中,所述预训练的孪生网络通过以下步骤训练得到:对预设的图像数据集中的各图像进行数据增强,得到对应的增强数据集;其中,所述图像数据集中的各图像所属场景相同,所述数据增强至少包括随机的平移、旋转、缩放、镜像翻转、裁剪和色彩抖动;将所述增强数据集中的增强图像输入至基于resnet50构建的初始孪生网络,获得各所述增强图像的高维特征,并计算各所述增强图像的高维特征之间的欧氏距离;基于所述各所述增强图像的高维特征之间的欧氏距离,使用三元损失函数对所述初始孪生网络进行迭代训练至收敛,将训练完成的初始孪生网络作为预训练的孪生网络;其中,所述三元损失函数用于保证相同坐标下的图像具有相似的特征,不同坐标下的图像具有不相似的特征。图像增强过程为孪生网络的训练提供了更多高质量的训练样本,训练出的孪生网络在部署后,能够快速、准确地获取查询图像的高维特征,进一步提升了视觉定位的精度和速度。
5、在一些可选的实施例中,所述图像数据集中的各图像所属场景与所述查询图像相同,所述特征库通过以下步骤得到:将所述图像数据集中的各图像作为特征图像,并建立各所述特征图像的位置坐标映射;将各所述特征图像输入至所述孪生网络,获得各所述特征图像的高维特征,并使用lsh算法对各所述特征图像的高维特征进行哈希映射,得到各所述特征图像的哈希码;根据各所述哈希码,以及各所述哈希码与所述特征图像的映射关系,建立特征库。对于应用场景,本技术提前建立丰富的特征库,在哈希码匹配过程中保证可以使查询图像匹配到相似的目标特征图像,保证视觉定位能够顺利进行。
6、在一些可选的实施例中,所述根据所述查询图像的哈希码在对应的特征库中进行匹配,确定与所述查询图像匹配的目标特征图像,包括:根据所述查询图像的哈希码在对应的特征库进行匹配,计算所述查询图像的哈希码与所述特征库中的哈希码的匹配相似度;将所述特征库中的所述匹配相似度大于第一预设阈值的哈希码对应的所有特征图像,确定为与所述查询图像匹配的目标特征图像。为了增加容错,本技术设置将匹配相似度大于第一预设阈值的哈希码对应的所有特征图像都作为目标特征图像参与后续的配准、视觉定位环节,进一步提升了视觉定位的精度。
7、在一些可选的实施例中,所述分别基于各所述目标特征图像的位置坐标,利用预构建的点云查找函数,在所述查询图像所属场景对应的点云数据集中,确定各所述目标特征图像对应的点云数据,包括:遍历各所述目标特征图像,在所述查询图像所属场景对应的点云数据集中,获取以所述当前目标特征图像的位置坐标为中心,以所述点云查找函数对应的预设搜索半径为半径的圆形区域内的点云数据,作为所述当前目标特征图像对应的点云数据;在遍历完成各所述目标特征图像后,得到各所述目标特征图像对应的点云数据。
8、在一些可选的实施例中,所述使用融合编码器分别对所述目标特征图像和所述点云数据进行编码,得到成对的点云特征代理和图像特征代理,包括:采用pointnet架构提取所述点云数据的点特征,并对所述点云数据进行最远点采样获得预设数量的中心点及个中心点对应的中心特征,所述中心点表征对应局部区域的中心;采用点对点分组策略将每个点特征分配给最近的中心点,确定各层级的点云局部特征;将所述各层级的点云局部特征与所述目标特征图像的图像全局特征连接后,馈送到多层感知机中,确定所述各层级的点云局部特征对应的权重,得到各层级的加权点云特征;利用聚类算法对所述目标特征图像进行分层提取,确定各层级的图像局部特征;将所述各层级的图像局部特征与所述点云数据的点云全局特征连接后,馈送到多层感知机中,确定所述各层级的图像局部特征对应的权重,得到各层级的加权图像特征;分别对所述各层级的加权点云特征和所述各层级的加权图像特征进行上采样,得到成对的点云特征代理和图像特征代理。这样得到成对的点云特征代理和图像特征代理能够充分学习到不同层级的跨模态特征,进一步提升了视觉定位的精度。
9、在一些可选的实施例中,所述根据预训练的跨模态对应关系学习模型及所述成对的点云特征代理和图像特征代理,确定所述点云数据与所述目标特征图像之间的3d-2d匹配关系,包括:将所述成对的点云特征代理和图像特征代理输入至所述跨模态对应关系学习模型中,通过所述跨模态对应关系学习模型的粗匹配模块,计算所述成对的点云特征代理和图像特征代理之间的成对距离矩阵,并基于所述成对距离矩阵得到用于表征粗对应关系的掩码矩阵;通过所述跨模态对应关系学习模型的粗到精模块,对所述掩码矩阵进行重新采样,得到点级特征和像素级特征;通过所述跨模态对应关系学习模型的精匹配模块,对所述点级特征和像素级特征进行精细配准,得到所述点云数据与所述目标特征图像之间的3d-2d匹配关系。
10、在一些可选的实施例中,述计算所述成对的点云特征代理和图像特征代理之间的成对距离矩阵,通过以下公式实现:
11、
12、其中,fimg表示所述点云特征代理,fpc表示所述图像特征代理,dp为预设的点云特征的维度,d表示计算出的所述成对的点云特征代理和图像特征代理之间的成对距离矩阵。
13、在一些可选的实施例中,所述基于各所述3d-2d匹配关系,利用ransac算法与epnp算法,以及重力方向的先验知识,确定所述查询图像对应的拍摄位姿,包括:分别基于各所述3d-2d匹配关系,利用ransac算法与epnp算法,得到各所述3d-2d匹配关系对应的拍摄位姿;在各所述3d-2d匹配关系对应的拍摄位姿中,确定最符合重力方向的先验知识的拍摄位姿,作为所述查询图像对应的拍摄位姿。
14、在一些可选的实施例中,在所述确定所述查询图像对应的拍摄位姿之后,所述方法还包括:若再次获取到所述查询图像的拍摄方发送的新查询图像的定位请求,则判断所述新查询图像的定位请求与所述查询图像的定位请求之间的时间间隔是否小于第二预设阈值,并判断所述拍摄方的移动速度是否小于第三预设阈值;若所述新查询图像的定位请求与所述查询图像的定位请求之间的时间间隔小于第二预设阈值,且所述拍摄方的移动速度小于第三预设阈值,则直接将所述查询图像对应的拍摄位姿作为所述新查询图像对应的拍摄位姿;若所述新查询图像的定位请求与所述查询图像的定位请求之间的时间间隔不小于第二预设阈值,或者所述拍摄方的移动速度不小于第三预设阈值,则将所述新查询图像输入至所述孪生网络,获得所述新查询图像的高维特征,并使用所述lsh算法对所述新查询图像的高维特征进行哈希映射,得到所述新查询图像的哈希码。如果统一拍摄方发起的两次定位请求之间的时间间隔很短,并且拍摄方的移动速度很小,此时可以认为拍摄方没有进行移动,直接将上次视觉定位结果赋予本次视觉定位请求即可,否则再进行新的视觉定位流程,这样处理在满足视觉定位需求的同时避免了计算资源的浪费,节约了视觉定位的成本。
- 还没有人留言评论。精彩留言会获得点赞!