基于重排序器的医疗问题摘要生成方法和装置
本发明涉及人工智能、自然语言处理,具体地说是一种基于重排序器的医疗问题摘要生成方法和装置。
背景技术:
1、随着当前互联网的快速发展,医疗行业积极与互联网接轨,涌现了一大批既能方便患者又能减轻医生压力的网络应用。其中,在线医疗问答社区发展非常迅速。患者可以在网络社区中发布自己的医疗相关问题,由医生在方便的时间,在线解疑答惑。这种模式,大大减少了患者向医生直接进行咨询的环节,避免了传统就医环节中前往医院、挂号、排队的流程,降低了医疗咨询的门槛,也提高了医生的工作效率。然而,随着在线提问的用户数量的增加,提出问题的患者数量远远高于解答问题的医生数量,问题的增加速度远远大于解答的速度。这导致在线医疗问答的患者体验迅速下降。针对于此,许多研究人员基于自然语言处理技术提出了各式各样的医疗自动问答系统。这些医疗自动问答系统大多是基于文本匹配技术实现的,即为患者问题在已有的问答数据库中选择匹配的答案,并将其推荐给患者;这样既能快速满足患者需求,又能减少医生的工作量。然而,患者提出的医疗健康问题通常包含许多无用的外围信息,例如一些日常用语或者患者病史;而且,患者通常缺乏医学专业知识,他们描述的医疗问题中可能会包含一些与医生用词不同的非专业词汇。这些原因导致基于文本匹配技术的医疗自动问答系统很难为患者在数据库中匹配出此类问题的正确答案,严重限制了医疗自动问答系统的发展。在这种情况下,医疗自动问答系统迫切需要一种能将冗长的患者医疗问题摘要为简洁精炼且易于检索匹配的常见问题的技术,即医疗问题摘要生成技术。
2、近年来,许多序列到序列的预训练语言模型和方法被应用于医疗问题摘要生成技术。常见的用于医疗问题摘要生成的序列到序列模型包括t5、pegasus、prophetnet和bart,其中以bart模型为基础的方法表现最优。目前,医疗问题摘要生成技术发展的一个趋势是用各类特定方法去加强序列到序列模型,常见的方法包括基于外部知识增强的方法、基于迁移学习的方法、基于多任务学习的方法、基于强化学习的方法以及基于对比学习的方法。这些方法在医疗问题摘要生成任务上取得了不错的表现,但是都忽略了序列到序列模型的目标函数和评估指标之间的不一致性,这意味着这些方法所生成的唯一摘要不一定是解码搜索空间中的最佳摘要。为了弥补这一差距,需要扩大序列到序列模型的解码搜索空间,获得更多的候选摘要,然后用合理的方法评估这些候选摘要的质量,对候选摘要进行重排序以选择最佳的摘要。
技术实现思路
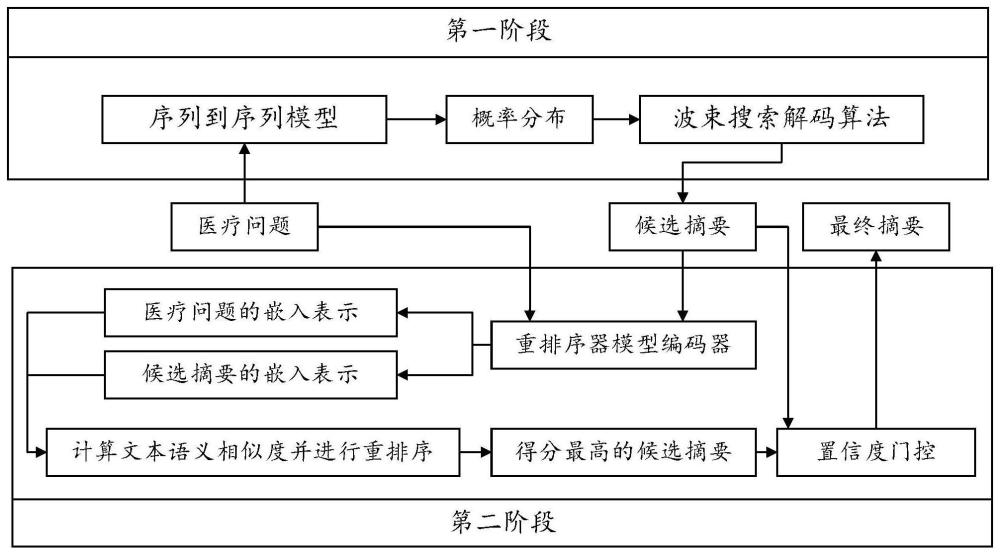
1、针对现在医疗问题摘要生成方法存在的不足,本发明的技术任务是提供基于重排序器的医疗问题摘要生成方法和装置;解决如何使用自然语言处理技术,将冗长的患者医疗问题提炼为简洁明了的问题摘要,以方便医疗问答系统进行检索和匹配;弥补现有医疗问答系统不能回答冗长问题的缺陷,提高医疗问答系统的处理能力。该方法和装置提出了一种基于重排序器的医疗问题摘要生成模型架构,该架构主要由序列到序列模型、候选摘要生成模块和重排序器组成。其中,序列到序列模型负责对输入的医疗问题进行编码和解码;候选摘要生成模块负责为医疗问题生成候选摘要;重排序器负责对候选摘要进行质量评估并进行重排序。
2、本发明的技术任务是按以下方式实现的,一种基于重排序器的医疗问题摘要生成方法,该方法包括如下步骤:
3、步骤s1,构建医疗问题摘要生成数据集:首先需要获得由用户在医疗问答社区提出的医疗问题和专家撰写的参考摘要以构成医疗问题摘要生成数据集,然后将其切分成训练数据集、验证数据集和测试数据集;
4、步骤s2,构建并训练医疗问题摘要生成模型,主要操作包括:构建序列到序列模型、构建交叉熵损失函数、优化序列到序列模型训练、为医疗问题生成候选摘要;
5、步骤s3,构建并训练重排序器模型,主要操作包括:构建重排序器模型、构建排序损失函数、优化重排序器模型训练;
6、步骤s4,使用医疗问题摘要生成模型和重排序器模型进行推理,主要操作包括:为医疗问题生成候选摘要、对医疗问题及其候选摘要进行编码、计算文本语义相似度并进行重排序、通过置信度门控机制选择最终摘要。
7、作为优选,所述构建并训练医疗问题摘要生成模型具体如下:
8、构建并训练医疗问题摘要生成模型,主要操作包括:构建序列到序列模型、构建交叉熵损失函数、优化序列到序列模型训练、为医疗问题生成候选摘要。
9、所述构建序列到序列模型,具体为:首先构建序列到序列模型的结构,随后加载预训练好的序列到序列模型权重及其参数配置文件。
10、所述构建交叉熵损失函数,具体为:对于构建的序列到序列模型,其标准训练框架是极大似然估计;对于加载的训练数据集中的一个具体训练样本{chq,faq},其中chq代表医疗问题,记为q,faq代表参考摘要,记为s;极大似然估计等效于最小化参考摘要s中的l个词元(token){s1,···,sj,...,sl}的负对数似然加和,即优化以下的交叉熵损失函数:
11、
12、其中,s*指的是模型当前生成的词元(token);s<j指的是由一个提前定义好的起始词元s0以及当前词元sj之前的词元构成的词元表,即{s0,s1,…,sj-1};
13、ptrue代表标准的极大似然估计框架中的一个独热编码(one-hot)分布;θ指的是f的参数,是由f的参数引起的概率分布;f是一个模型函数,给定一个医疗问题q,医疗问题摘要任务的目标就是学习一个函数f去生成医疗问题q的摘要s*,具体公式如下:
14、s*←f(q)
15、所述优化序列到序列模型训练,具体为:使用adam作为优化算法,adam优化器的学习率设置为1e-5,在加载的训练数据集上使用构建的交叉熵损失函数对构建的序列到序列模型进行优化训练。
16、所述为医疗问题生成候选摘要,具体为:将训练好的序列到序列模型记为g(·);对于加载的训练数据集中的一个特定的样本{chq,faq},其中chq代表医疗问题,记为q,faq代表参考摘要,记为s;使用g(·)可以为q生成一个概率分布d,具体公式如下:
17、d=g(q)
18、用波束搜索解码算法来生成给定医疗问题q的一组候选摘要
19、
20、其中beamsearch(·)指的是波束搜索算法,n代表候选摘要的数量;使用rouge评分中的rouge-l f1指标计算候选摘要集合中的候选摘要ci和参考摘要s之间的评分,评分后的候选摘要集合表示为:
21、
22、其中,是根据它们的得分按降序排序的;带有得分的样本被用作构建的重排序器模型优化的监督信号;需要注意的是,这些得分只用于训练过程,而不用于推理过程,因为推理时不能使用标签,即参考摘要s。
23、更优地,所述构建并训练重排序器模型具体如下:构建并训练重排序器模型,主要操作包括:构建重排序器模型、构建排序损失函数、优化重排序器模型训练。
24、所述构建重排序器模型,具体为:对于加载的训练数据集中的一个具体训练样本{chq,faq},其中chq代表医疗问题,记为q,faq代表参考摘要,记为s;使用训练好的序列到序列模型为医疗问题q生成候选摘要集合并对每个候选摘要进行评分,得到评分后的候选摘要集合基于文本语义相似度的重排序器模型的核心思想是计算q和之间的余弦相似度,然后用相似度去衡量的质量;使用预训练语言模型roberta作为重排序器模型的编码器对q、s及进行编码,以得到它们的嵌入表示eq、es及
25、eq=embedding(q)
26、es=embedding(s)
27、
28、其中,i=1,2,…,n,n是生成的候选摘要的数量;embedding(·)是使用编码器得到文本嵌入表示的函数。
29、所述构建排序损失函数,具体为:对于构建的重排序器模型,构建一个排序损失函数加强其评估候选摘要质量的效果;对于加载的训练数据集中的一个具体训练样本{chq,faq},其中chq代表医疗问题,记为q,faq代表参考摘要,记为s;使用训练好的序列到序列模型为医疗问题q生成候选摘要集合并对每个候选摘要进行评分,得到评分后的候选摘要集合使用重排序器模型的编码器得到q、s和的嵌入表示eq、es和所构建的排序损失函数的公式具体如下:
30、
31、其中,i=1,2,…,n,n是候选摘要的数目;λij=(j-i)*λ是排序相应间隔,λ是一个控制相应间隔大小的超参数;max(x,y)表示返回x和y中的最大值;sim(·)是指余弦相似度的计算,以sim(eq,es)为例,其计算公式具体如下:
32、
33、的计算方式类似,不再赘述。
34、所述优化重排序器模型训练,具体为:使用adam作为优化算法,adam优化器的初始学习率设置为2e-7,最大学习率设置为2e-3,在加载的训练数据集上使用构建的排序损失函数对构建的重排序器模型进行优化训练。
35、更优地,所述使用医疗问题摘要生成模型和重排序器模型进行推理具体如下:
36、使用医疗问题摘要生成模型和重排序器模型进行推理,主要操作包括:为医疗问题生成候选摘要、对医疗问题及其候选摘要进行编码、计算文本语义相似度并进行重排序、通过置信度门控机制选择最终摘要。
37、所述为医疗问题生成候选摘要,具体为:将训练好的序列到序列模型记为g(·);对于加载的验证或测试数据集中的一个特定的样本{chq,faq},其中chq代表医疗问题,记为q,faq代表参考摘要,记为s;使用g(·)可以为q生成一个概率分布d,具体公式如下:
38、d=g(q)
39、用波束搜索解码算法来生成给定医疗问题q的一组候选摘要
40、
41、其中beamsearch(·)指的是波束搜索算法,n代表候选摘要的数量,设置为16。
42、所述对医疗问题及其候选摘要进行编码,具体为:对于加载的验证或测试数据集中的一个特定的样本{chq,faq},其中chq代表医疗问题,记为q;对于q的候选摘要,记为使用训练完毕的重排序器模型的编码器对q和中的候选摘要进行编码,以得到医疗问题和其候选摘要的嵌入表示eq和
43、eq=embedding(q)
44、
45、其中,i=1,2,…,n,n是生成的候选摘要的数量;embedding(·)是使用编码器得到文本嵌入表示的函数。
46、所述计算文本语义相似度并进行重排序,具体为:使用得到的医疗问题和其候选摘要的嵌入表示eq和计算出每个候选摘要与其医疗问题之间的文本语义相似度,然后根据文本语义相似度选择出得分最高的候选摘要cmax,具体公式如下:
47、
48、其中,是计算和eq之间的余弦相似度,具体公式如下:
49、
50、argmax(·)是选择出文本语义相似度得分最高的候选摘要的函数。
51、所述通过置信度门控机制选择最终摘要,具体为:将得到的得分最高的候选摘要cmax以及生成的候选摘要集合中的c1送到置信度门控中,得到最终摘要cfinal,置信度门控的具体公式如下:
52、
53、其中,是计算cmax的嵌入表示和q的嵌入表示eq之间的余弦相似度,具体公式如下:
54、
55、与的计算方式类似,不再赘述;η是置信度阈值,是一个超参数,具体取值公式如下:
56、η=[λ×10/2,λ×10]
57、其中,λ是排序损失函数中的一个超参数。
58、更优地,所述构建医疗问题摘要生成数据集具体如下:
59、首先需要获得由用户在医疗问答社区提出的医疗问题和专家撰写的参考摘要以构成医疗问题摘要生成数据集,然后将其切分成训练数据集、验证数据集和测试数据集。
60、一种基于重排序器的医疗问题摘要生成装置,该装置包括:
61、医疗问题摘要生成数据集构建单元,负责对原始数据集进行预处理并将原始数据集切分为训练数据集、验证数据集和测试数据集。
62、医疗问题摘要生成模型构建和训练单元,负责构建序列到序列模型,用交叉熵损失函数训练模型的摘要生成能力,并为重排序器模型生成候选摘要。
63、重排序器模型构建和训练单元,负责构建重排序器模型,并用排序损失训练模型评估候选摘要质量的能力。
64、医疗问题摘要生成模型和重排序器模型推理单元,用于将训练完毕的医疗问题摘要生成模型和重排序器模型结合在一起,构建医疗问题摘要生成的完整推理流程。
65、一种电子设备,电子设备包括存储介质以及处理器;存储介质存储有多条指令,所述指令由处理器加载,执行上述基于重排序器的医疗问题摘要生成方法的步骤;处理器,用于执行存储介质中的指令。
66、本发明的基于重排序器的医疗问题摘要生成方法和装置具有以下优点:
67、(一)本发明将高性能的序列到序列模型作为基础模型并应用到医疗问题摘要生成中,为生成医疗问题摘要提供了基础保障;
68、(二)本发明扩大了序列到序列模型的解码搜索空间,为医疗问题生成更多的候选摘要,增加高质量摘要出现的概率;
69、(三)本发明设计并训练了一个重排序器模型,该模型能够根据文本语义相似度去衡量候选摘要的质量,从而选择出质量更高的候选摘要;
70、(四)本发明在推理阶段为重排序器模型引入了一种置信度门控机制,该门控机制能够在模型置信度不足时保证输出的原始水平,使模型获得更优的性能表现;
71、(五)本发明将序列到序列模型和重排序器模型整合到医疗问题摘要生成中,整合后的模型分两个阶段,第一阶段用序列到序列模型为医疗问题生成候选摘要,第二阶段用重排序器模型对候选摘要进行质量评估和重排序。整合后的模型能够有效地提高医疗问题摘要生成模型的性能表现。
- 还没有人留言评论。精彩留言会获得点赞!