基于用户特征的云数据统筹管理系统及方法与流程
本发明涉及云数据统筹,尤其涉及基于用户特征的云数据统筹管理系统及方法。
背景技术:
1、目前,云数据管理系统主要采用云存储、云计算、大数据分析等技术,为用户提供数据存储、处理、分析和推荐的服务。这些系统通常具有以下特点:
2、云存储服务:提供用户数据的远程存储和备份,包括对象存储、文件存储等,用户可以根据需求灵活选择存储容量和存储类型。云计算服务:提供弹性计算能力,用户可以根据需要动态获取计算资源,进行数据处理、应用部署等操作。大数据分析:通过大数据技术对海量数据进行存储、处理和分析,为用户提供数据挖掘、业务智能等服务。数据安全与隐私保护:提供数据加密、访问控制、安全审计等功能,保障用户数据的安全和隐私。智能推荐系统:通过分析用户的历史数据和行为,为用户推荐数据管理方案、工具或服务,提高用户体验和数据管理效率。
3、然而,现有技术还存在一些不足之处:
4、缺乏个性化服务:目前大多数云数据管理系统还是采用统一的管理方式,无法根据用户的特征和需求提供个性化的数据管理服务。这导致用户体验和满意度无法得到有效提升。智能推荐精度有限:现有的智能推荐系统在推荐精度方面还有待提高,无法充分准确地理解用户的需求和偏好,导致推荐的数据管理方案或工具与用户实际需求不完全匹配。
5、综上所述,尽管云计算和大数据技术已经为数据管理带来了革命性的变化,但在个性化服务、智能推荐精度方面仍存在诸多挑战和不足之处。
6、中国申请号为201910161585.8的发明专利公开了信息推荐方法和装置,其公开了对项目所在的项目集合进行聚类,生成多个包含项目的类簇;计算用户对该项目在每个类簇中的短期兴趣权重和长期兴趣权重;根据短期兴趣权重和长期兴趣权重计算用户对该项目在每个类簇中的预测评分;获取该项目与各个类簇的相似度;根据该项目在每个类簇中的预测评分和所述项目与各个类簇的相似度计算得到最终预测评分;根据该最终预测评分生成推荐列表。该现有技术是根据两种权重计算方式以及相似度来预测用户对项目的兴趣程度,并未考虑其他影响推荐结果的因素,其推荐精度有限,且无法满足用户的个性化需求。
技术实现思路
1、有鉴于此,本发明提供基于用户特征的云数据统筹管理系统及方法,通过考虑用户的个性化需求、时间标签,来进行智能匹配和精确推荐,提高了推荐的准确性和用户满意度,并保证了推荐结果的实时性和时效性。
2、本发明的技术目的是这样实现的:
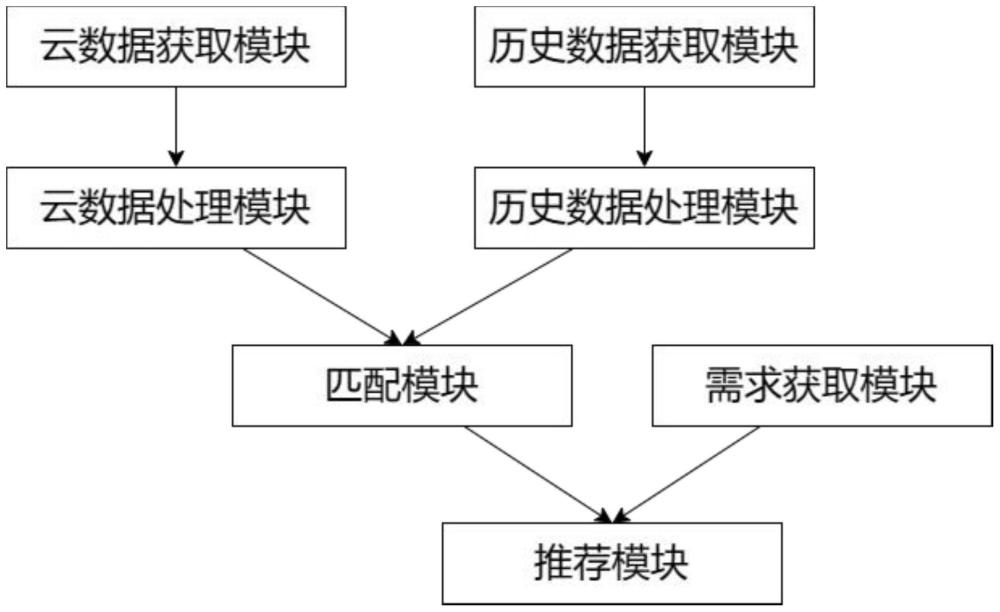
3、一方面,本发明提供基于用户特征的云数据统筹管理系统,包括:
4、云数据获取模块,其配置为从公有云中获取云数据,云数据包含时间标签;
5、云数据处理模块,其配置为采用聚类算法对云数据进行聚类,形成k个云数据组和k个聚类中心,并对k个云数据组和k个聚类中心进行第一特征向量的提取,将k个聚类中心提取得到的第一特征向量作为k个第一特征中心,得到k个第一特征向量组;
6、历史数据获取模块,其配置为获取用户历史数据,包括用户历史推荐数据和用户历史需求数据;
7、历史数据处理模块,其配置为对用户历史推荐数据进行特征提取,得到第二特征向量,并对用户历史需求数据进行关键词提取,得到历史关键词;
8、匹配模块,其配置为计算第二特征向量分别与k个第一特征中心的特征相似度,根据特征相似度为第二特征向量匹配对应的第一特征向量组,将第二特征向量、第一特征向量组及对应的云数据形成匹配组,并基于历史关键词对匹配组创建索引,得到匹配库;
9、需求获取模块,其配置为获取用户当前需求数据,并对当前需求数据提取当前关键词;
10、推荐模块,其配置为根据当前关键词在匹配库中搜索,得到第一推荐列表,根据第一推荐列表中对应的时间标签,计算第一推荐列表中各个匹配组的推荐价值,按照推荐价值将第一推荐列表重排,得到最终推荐列表。
11、在上述技术方案的基础上,优选的,云数据处理模块包括:
12、数据预处理单元,其配置为对云数据进行预处理,包括数据清洗、去噪和异常值处理;
13、初步聚类单元,其配置为将预处理后的云数据划分为n个数据子集,利用聚类算法对每个数据子集分别进行聚类,每个数据子集均聚类得到k个聚类簇和k个初始聚类中心;
14、聚类合并单元,其配置为将k个聚类簇和k个初始聚类中心作为初始聚类结果,利用聚类算法对初始聚类结果进行二次聚类,得到k个云数据组和k个聚类中心;
15、特征提取单元,其配置为利用第一特征提取网络依次对k个云数据组和k个聚类中心进行特征提取,每个云数据组提取得到一组第一特征向量,将k个聚类中心提取的第一特征向量作为k个第一特征中心,将k个第一特征中心分别归至对应的一组第一特征向量,形成k个第一特征向量组。
16、在上述技术方案的基础上,优选的,聚类算法包括:
17、第一步、设置初始化次数ninit和k值;
18、第二步、令n=1,进行第1次初始化,选择k个云数据作为当前聚类中心;
19、第三步、对单个云数据,计算其到各个当前聚类中心的距离d(k),选择最短的距离d(s),将对应云数据的标签赋为s;
20、第四步、重复第三步,为每个云数据均赋予标签,根据标签形成k个簇;
21、第五步、计算每个簇内的云数据的模拟值,将模拟值作为新的当前聚类中心,并转至第三步,其中,模拟值的计算公式为:
22、
23、式中,x为模拟值,n为该簇内云数据的数量,表示第a个云数据的映射矩阵的转置,da表示第a个云数据与当前聚类中心的距离,θ表示距离分布矩阵;
24、第六步、直至达到迭代停止条件,得到k个聚类簇和k个聚类中心,作为聚类结果;
25、第七步、令n=n+1,重新初始化,选择新的k个云数据作为当前聚类中心,并转至第三步;
26、第八步、直至n=ninit,则聚类结束,得到ninit组的聚类结果;
27、第九步、计算每组聚类结果的聚类质量指标,将最优聚类质量指标的聚类结果作为最终的聚类结果,聚类质量指标的计算公式为:
28、am=∑d(point,centroid)2,m=[1,ninit]
29、式中,am表示第m组聚类结果的聚类质量指标值,d(point,centroid)表示该组聚类结果中单个云数据与对应聚类中心的距离。
30、在上述技术方案的基础上,优选的,匹配模块包括:
31、相似计算单元,其配置为采用相似度公式计算第二特征向量分别与k个第一特征中心的特征相似度,根据特征相似度的值判定每个第二特征向量分别与k个第一特征中心的相似性,以k个第一特征中心为起始建立匹配集合,将第一特征中心对应的第一特征向量组归入相应的匹配集合,并依次比对每个第二特征向量分别与k个第一特征中心的相似性,将每个第二特征向量分配至相似性最大的第一特征中心所在的匹配集合内,之后将第一特征向量组对应的云数据相应归至匹配集合,形成匹配组;
32、索引创建单元,其配置为基于历史关键词对匹配组创建多维混合索引,得到索引表,索引表中每条索引链接至对应的匹配组,将索引表和匹配组结合得到匹配库。
33、在上述技术方案的基础上,优选的,相似度公式表示如下:
34、
35、式中,s(u,v)表示第二特征向量u与第一特征中心v之间的特征相似度的值,ju,v表示u和v之间的jaccard系数,y表示v对应的第一特征向量组中的第一特征向量集合,|y|表示y的基数,uu表示u中的第u个特征值,vv表示v中的第v个特征值,为uu和vv的联合权重参数,β为衰减系数,du,v为u和v之间的距离。
36、在上述技术方案的基础上,优选的,匹配库的形成过程为:
37、确定索引表的字段结构,包括匹配组标识符和关键词列表,其中,匹配组标识符为匹配组的唯一id,关键词列表为历史关键词及其近义词和扩展词;
38、根据匹配组中包含的时间标签建立带有时间标签的匹配组标识符,同时根据历史关键词搜寻对应的近义词和扩展词,将历史关键词及其近义词和扩展词混合进行编码,建立关键词列表的编码索引;
39、将带有时间标签的匹配组标识符和关键词列表的编码索引导入至索引表中,完成索引表的构建;
40、将索引表中的匹配组标识符与对应的匹配组进行关联,得到匹配库。
41、在上述技术方案的基础上,优选的,推荐模块包括:
42、模糊推荐单元,其配置为使用当前关键词,通过查询语言在匹配库中进行查询,获取与当前关键词相关的第一推荐列表;
43、价值计算单元,其配置为根据每个匹配组中包含的时间标签和对应的云数据的数量计算每个匹配组的第一推荐价值和第二推荐价值;
44、精确推荐单元,其配置为根据第一推荐价值将匹配组按从高到低的顺序排列,再根据第二推荐价值将每个匹配组中的云数据按从高到低的顺序排列,形成最终推荐列表。
45、在上述技术方案的基础上,优选的,第一推荐价值的计算公式为:
46、
47、式中,f1(b)是第b个匹配组的第一推荐价值,m为第b个匹配组中云数据的数量,ti表示第b个匹配组中第i个云数据的时间标签,表示ti的影响项,r为影响因子,λb为第b个匹配组的可调参数,ωi指的第b个匹配组中第i个云数据的权重,为第b个匹配组中云数据与时间标签的映射矩阵,表示映射矩阵的秩。
48、在上述技术方案的基础上,优选的,第二推荐价值的计算公式为:
49、
50、式中,f2(i)是单个匹配组中第i个云数据的第二推荐价值,kwc表示当前关键词,kwh表示历史关键词,s(kwc,kwh)为当前关键词和历史关键词的相似度,ti表示第i个云数据的时间标签,为ti数值化后的调节数值,t为调节因子。
51、另一方面,本发明还提供基于用户特征的云数据统筹管理方法,所述方法执行于上述任一项所述的系统中,所述方法包括以下步骤:
52、s1从公有云中获取云数据,云数据包含时间标签;
53、s2采用聚类算法对云数据进行聚类,形成k个云数据组和k个聚类中心,并对k个云数据组和k个聚类中心进行第一特征向量的提取,将k个聚类中心提取得到的第一特征向量作为k个第一特征中心,得到k个第一特征向量组;
54、s3获取用户历史数据,包括用户历史推荐数据和用户历史需求数据;
55、s4对用户历史推荐数据进行特征提取,得到第二特征向量,并对用户历史需求数据进行关键词提取,得到历史关键词;
56、s5计算第二特征向量分别与k个第一特征中心的特征相似度,根据特征相似度为第二特征向量匹配对应的第一特征向量组,将第二特征向量、第一特征向量组及对应的云数据形成匹配组,并基于历史关键词对匹配组创建索引,得到匹配库;
57、s6获取用户当前需求数据,并对当前需求数据提取当前关键词;
58、s7根据当前关键词在匹配库中搜索,得到第一推荐列表,根据第一推荐列表中对应的时间标签,计算第一推荐列表中各个匹配组的推荐价值,按照推荐价值将第一推荐列表重排,得到最终推荐列表。
59、本发明的方法相对于现有技术具有以下有益效果:
60、(1)本发明通过对用户历史数据和当前需求的分析,系统能够根据用户的个性化需求进行匹配和推荐,提高了推荐的准确性和用户满意度,利用聚类算法对云数据进行聚类,结合特征向量的提取和匹配模块,能够实现对用户需求和历史数据的智能匹配,提高了推荐的精准度和实用性,系统根据云数据的时间标签和用户当前需求,能够计算推荐价值并实现最终推荐列表的重排,从而保证了推荐结果的实时性和准确性;
61、(2)本发明的云数据处理模块中的聚类算法是基于层次聚类的改进算法,其通过多次初始化和迭代更新聚类中心,使得聚类结果更加准确,能够更好地代表不同的数据簇,采用模拟值替代计算均值的方法,能够减少计算的复杂度,提高了聚类算法的效率,通过多次初始化和选择最优的聚类质量指标,能够降低对初始值的敏感度,使得聚类结果具有较好的鲁棒性;
62、(3)本发明的聚类算法考虑到云数据可能数量庞大,该聚类算法采用了迭代更新和模拟值替代的方法,使得其适用于处理大规模数据,具有较好的可扩展性,且算法中采用了距离分布矩阵的方式来表示数据点与聚类中心的距离,因此能够较好地处理复杂的数据分布情况,包括非凸形状的簇和不同密度的数据点;
63、(4)本发明提出的相似度公式,在其中引入了联合权重参数和衰减系数,以及距离度量,对jaccard系数进行了扩展和修正,使其适用于特征向量之间的相似度计算,以得到更准确和全面的特征相似度值;
64、(5)本发明提出的第一推荐价值是根据每个匹配组中云数据的数量、时间标签、影响因子和映射矩阵等因素计算得出的。它反映了在模糊推荐单元中得到的第一推荐列表中,每个匹配组中的数据的重要性和价值,从而生成更精准的推荐列表。第二推荐价值是单个匹配组中每个云数据的价值,通过综合考虑了当前关键词、历史关键词、相似度和时间标签的调节因子,来评估每个匹配组中每个云数据的价值。由于第一推荐价值和第二推荐价值考虑了更多因素,系统生成的推荐列表更符合用户的兴趣和需求,因此可以提高用户对推荐结果的满意度。
- 还没有人留言评论。精彩留言会获得点赞!