基于解耦自增强的细节可控个性化图像生成方法及系统
本发明涉及数字图像生成领域,并特别涉及一种基于解耦自增强的细节可控个性化图像生成方法及系统。
背景技术:
1、在今天,仅仅需要用户给出自然语言描述,大规模图像生成模型就能够合成以假乱真或者异想天开的图像。数字内容合成领域的个性化生成任务旨在满足用户的定制化生成需求,通过学习用户指定的参考概念(例如个人自拍、宠物狗的照片等)生成包含这个概念的新图片。个性化技术可以为广告设计、艺术创作、社交媒体等广泛的应用场景提供支持。
2、现有的个性化生成方法大多关注高质量高效率的概念重建或多个概念的提取与组合。然而这些通常为概念级方法,仅仅关注对参考图片中整体概念的学习。在缺少额外训练数据或监督信息的情况下,这些方法无法解耦概念的不同视觉信息。另一些方法探索了如何拆解单个概念,独立学习构成原概念的视觉属性或细分概念,满足了用户提取细分属性和分析概念组成的需求。然而,这类方法往往依赖于对视觉属性的先验知识或基于无监督训练流程,因此无法根据用户要求可控地解耦指定属性并进行个性化生成。
技术实现思路
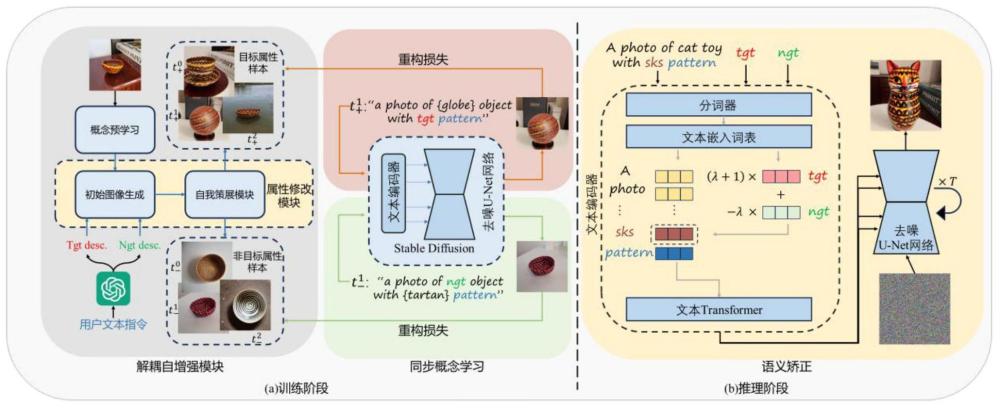
1、本发明的目的是解决数字图像个性化任务中学习用户指定的视觉属性的问题,提出了一个基于解耦自增强策略的属性个性化框架。
2、具体来说,本发明提出了一种基于解耦自增强的细节可控个性化图像生成方法,其中包括:
3、步骤1、获取参考概念图像和其对应的文本指令,通过大语言模型提取该文本指令的属性描述,该属性描述包括目标属性和非目标属性,基于该概念图像的概念特征和该属性描述,生成多个初始图像并筛选,将筛选后的每张初始图像与其对应的属性描述作为训练样本;
4、步骤2、为该训练样本中初始图像添加噪声得到噪声图像,将该噪声图像和其对应的属性描述送入包括文本编码器的扩散网络,该扩散网络根据该属性描述,预测该噪声图像中所添加的噪声,根据该预测结果和真实添加噪声构建损失函数训练该扩散网络,得到图像生成模型;
5、步骤3、调整该图像生成模型中的文本编码器文本嵌入空间,获取具有该目标属性的图像生成文本指令,该文本编码器对该图像生成文本指令对应的文本嵌入进行语义矫正,得到文本条件向量,将噪声图像和该文本条件向量输入该图像生成模型中的扩散网络,根据该图像生成文本指令为噪声图像去噪,得到该图像生成文本指令对应的图像生成结果。
6、所述的基于解耦自增强的细节可控个性化图像生成方法,其中该步骤1包括通过概念预学习模型得到该概念图像的概念特征,包括:
7、采用基于扩散模型的概念预学习模型,输入具有特定概念图像和类先验图像至该概念预学习模型,该概念预学习模型的优化目标为:
8、
9、式中z表示对具有特定概念图像进行编码得到的潜在代码,zt和z't分别是具有特定概念图像和类先验图像的潜在代码在时间步t时刻对z添加噪声ε~n(0,1)得到的加噪后潜在代码;y是构造的文本提示,y'是用于类特定先前保存的类名,c(y)表示对输入文本通过编码器c得到的条件向量;
10、给定加噪后的潜在zt、时间步长t和文本条件c(y),训练该概念预学习模型的去噪u-net网络参数θ,使其预测的噪声εθ接近实际添加的噪声ε;α表示优化过程中特定类别的先前保存损失的权重。
11、所述的基于解耦自增强的细节可控个性化图像生成方法,其中该步骤1包括:
12、将包括目标属性atgt和非目标属性angt的该文本指令输入该大语言模型,生成目标描述和非目标描述的集合t+和t-;其中,该目标描述修改了该文本指令中的非目标属性,该非目标描述修改了该文本指令中的目标属性;将这对描述集合输入到图像生成模型g0,得到目标样本集和非目标样本集i+=g0(t+)及i-=g0(t-),通过基于clip模型图文相似度或人工筛选的方式得到初始图像;
13、本发明得到一对目标属性和非目标属性的增强样本集合d={d+,d-},其中d+={t+,i+},d-={t-,i-}。
14、所述的基于解耦自增强的细节可控个性化图像生成方法,其中该步骤2包括:
15、对该增强样本集合中每对样本,本发明分别使用目标标识符tgt和非标识符ngt两个标识符表示目标属性和非目标属性的信息;使用每张图片对应的描述作为条件输入,同时训练两个标识符以分别绑定目标和非目标属性,基于重构损失构建如下优化目标:
16、
17、其中,和分别为i+和i-中样本的编码,t+和t-分别为该大语言模型构造的i+和i-中样本的属性描述,描述中分别包含了tgt和ngt标识符;
18、该步骤2中调整该图像生成模型中的文本编码器文本嵌入空间包括:
19、在该图像生成模型中文本编码器的文本嵌入空间中,将该目标属性标识符tgt向远离非目标属性标识符ngt的语义方向进行偏离。
20、本发明还提出了一种基于解耦自增强的细节可控个性化图像生成系统,其中包括:
21、初始模块,用于获取参考概念图像和其对应的文本指令,通过大语言模型提取该文本指令的属性描述,该属性描述包括目标属性和非目标属性,基于该概念图像的概念特征和该属性描述,生成多个初始图像并筛选,将筛选后的每张初始图像与其对应的属性描述作为训练样本;
22、训练模块,用于为该训练样本中初始图像添加噪声得到噪声图像,将该噪声图像和其对应的属性描述送入包括文本编码器的扩散网络,该扩散网络根据该属性描述,预测该噪声图像中所添加的噪声,根据该预测结果和真实添加噪声构建损失函数训练该扩散网络,得到图像生成模型;
23、图像生成模块,用于调整该图像生成模型中的文本编码器文本嵌入空间,获取具有该目标属性的图像生成文本指令,该文本编码器对该图像生成文本指令对应的文本嵌入进行语义矫正,得到文本条件向量,将噪声图像和该文本条件向量输入该图像生成模型中的扩散网络,根据该图像生成文本指令为噪声图像去噪,得到该图像生成文本指令对应的图像生成结果。
24、所述的基于解耦自增强的细节可控个性化图像生成系统,其中该初始模块包括通过概念预学习模型得到该概念图像的概念特征,包括:
25、采用基于扩散模型的概念预学习模型,输入具有特定概念图像和类先验图像至该概念预学习模型,该概念预学习模型的优化目标为:
26、
27、式中z表示对具有特定概念图像进行编码得到的潜在代码,zt和z't分别是具有特定概念图像和类先验图像的潜在代码在时间步t时刻对z添加噪声ε~n(0,1)得到的加噪后潜在代码;y是构造的文本提示,y'是用于类特定先前保存的类名,c(y)表示对输入文本通过编码器c得到的条件向量;
28、给定加噪后的潜在zt、时间步长t和文本条件c(y),训练该概念预学习模型的去噪u-net网络参数θ,使其预测的噪声εθ接近实际添加的噪声ε;α表示优化过程中特定类别的先前保存损失的权重。
29、所述的基于解耦自增强的细节可控个性化图像生成系统,其中该初始模块包括:
30、将包括目标属性atgt和非目标属性angt的该文本指令输入该大语言模型,生成目标描述和非目标描述的集合t+和t-;其中,该目标描述修改了该文本指令中的非目标属性,该非目标描述修改了该文本指令中的目标属性;将这对描述集合输入到图像生成模型g0,得到目标样本集和非目标样本集i+=g0(t+)及i-=g0(t-),通过基于clip模型图文相似度或人工筛选的方式得到初始图像;
31、本发明得到一对目标属性和非目标属性的增强样本集合d={d+,d-},其中d+={t+,i+},d-={t-,i-}。
32、所述的基于解耦自增强的细节可控个性化图像生成系统,其中该训练模块包括:
33、对该增强样本集合中每对样本,本发明分别使用目标标识符tgt和非标识符ngt两个标识符表示目标属性和非目标属性的信息;使用每张图片对应的描述作为条件输入,同时训练两个标识符以分别绑定目标和非目标属性,基于重构损失构建如下优化目标:
34、
35、其中,和分别为i+和i-中样本的编码,t+和t-分别为该大语言模型构造的i+和i-中样本的属性描述,描述中分别包含了tgt和ngt标识符;
36、该初始模块中调整该图像生成模型中的文本编码器文本嵌入空间包括:
37、在该图像生成模型中文本编码器的文本嵌入空间中,将该目标属性标识符tgt向远离非目标属性标识符ngt的语义方向进行偏离。
38、本发明还提出了一种服务器,其中包括所述的一种基于解耦自增强的细节可控个性化图像生成装置。
39、本发明还提出了一种存储介质,用于存储一种执行所述基于解耦自增强的细节可控个性化图像生成方法的计算机程序。
40、由以上方案可知,本发明的优点在于:
41、本发明基于解耦自增强的属性感知样本构造方法能够得到一对目标属性和非目标属性上增强的样本,以促进模型学习解耦的属性;通过在生产过程中文本嵌入上的矫正进一步分离指定目标属性和非目标属性的语义;对上述两阶段操作整合以得到整体框架,灵活地允许各类基础方案的部署与属性个性化生成。
- 还没有人留言评论。精彩留言会获得点赞!