配方分类方法、系统、电子设备及存储介质与流程
本技术涉及食品化工,具体涉及一种配方分类方法、系统、电子设备及存储介质。
背景技术:
1、在食品化工配方的制定过程中,高效而准确的配方归类对于提高生产效率、降低成本以及确保产品质量至关重要。然而,随着产品种类的增多,配方信息量呈爆炸式增长。现有技术主要采用人工经验方式进行配方分类,工作人员需要逐个检索不同配方并依据自己的知识水平判断其组成与性能特征,手动将配方划分到相应的类别中,这种人工分类方式降低了对食品化工配方的分类效率。
技术实现思路
1、本技术提供了一种配方分类方法、系统、电子设备及存储介质,可以提高对食品化工配方的分类效率。
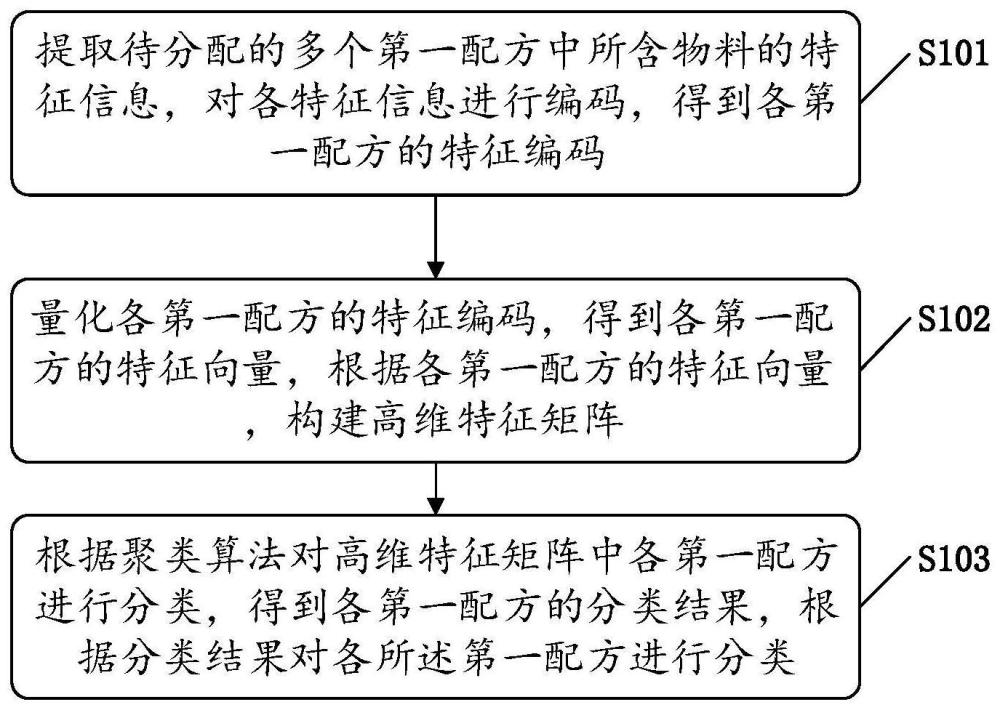
2、在本技术的第一方面,本技术提供了一种配方分类方法,包括:
3、提取待分类的多个第一配方中所含物料的特征信息,对各所述特征信息进行编码,得到各所述第一配方的特征编码;
4、量化各所述第一配方的特征编码,得到各所述第一配方的特征向量,根据各所述第一配方的特征向量,构建高维特征矩阵;
5、根据聚类算法对所述高维特征矩阵中各所述第一配方进行分类,得到各所述第一配方的分类结果,根据所述分类结果对各所述第一配方进行分类。
6、通过采用上述技术方案,对第一配方的特征信息进行提取、编码、向量化处理,构建了包含多条第一配方数字特征的高维特征矩阵。基于该高维特征矩阵,采用聚类算法根据配方特征的相似性对各第一配方进行自动分类,得到每条第一配方所属的类别。进而可以根据分类结果对数据库中的大量第一配方进行集中管理和处理。
7、相较于传统人工逐一判断归类的方式,该方法实现了配方信息的数字化表达和向量化处理。通过构建统一的高维特征矩阵数据格式,使配方的特征可以量化表示,并应用聚类算法进行批量自动分类。相比人工,该技术方案可以实现对大规模配方信息的快速高效处理。
8、同时,该方法可以根据分类结果,通过调节聚类模型的参数如最小半径,优化配方的分类效果,使聚类数量保持在合理范围内。保证了同类别配方的内部一致性,也有效区分了不同类别之间的差异。还可以基于类别特征中心,对新配方进行自动归类。
9、可选的,所述对各所述第一配方的特征编码进行标准化处理,得到各所述第一配方的特征向量之后,还包括:
10、若所述高维特征向量中第i个所述第一配方的特征向量名不存在,则对所述第一配方的特征向量名不存在的位置进行补0。
11、通过采用上述技术方案,在特征向量缺失维度上补0,可以将不同第一配方的特征向量扩展到相同维度,使它们都具有统一的向量长度。这为后续利用高维特征矩阵进行配方比较、区分和自动分类算法的应用提供了基础。
12、可选的,所述量化各所述第一配方的特征编码,得到各所述第一配方的特征向量,根据各所述第一配方的特征向量,构建高维特征矩阵,包括:
13、对各所述第一配方的特征编码进行标准化处理,得到各所述第一配方的特征向量;
14、根据各所述第一配方的特征向量,构建高维特征矩阵,其中,所述高维特征矩阵为:
15、xi=[mi1,mi2,…,mij,...,mim];
16、式中,xi表示第i个所述第一配方的特征向量名,mij表示第i个所述第一配方中第j个指标含量,m表示指标含量的数量。
17、通过采用上述技术方案,标准化处理将各第一配方的编码映射到了固定范围的数字序号中,实现了编码到标准化特征向量的转换。在后续构建特征矩阵时,不同配方矢量具有可比性。然后该方案根据标准化后的特征向量,构建了高维特征矩阵。矩阵以各配方的编码向量为行元素,列元素表示特征编码的不同维度。矩阵集中汇总了所有第一配方的编码信息。实现了将各第一配方的语义信息,统一转换为结构化的数字向量表示。
18、可选的,所述根据聚类算法对所述高维特征矩阵中各所述第一配方进行分类,得到各所述第一配方的分类结果,包括:
19、将所述高维特征矩阵代入聚类公式,得到各所述第一配方之间的欧式距离,并根据各所述第一配方之间的欧式距离,对各所述第一配方进行分类;
20、其中,所述聚类公式为:
21、
22、式中,dik表示第i个所述第一配方与第k个所述第一配方之间的欧式距离,n表示所有所述第一配方的数量,xij表示第i个所述第一配方中第j个分量,xkj表示第k个所述第一配方中第j个分量,sj表示所有所述第一配方中第j个分量的均值。
23、通过采用上述技术方案,将构建好的包含所有第一配方向量的高维特征矩阵输入预设的聚类公式。公式依据矩阵数据,计算得到任意两第一配方在各编码维度上的数值差异,表示为两配方之间的欧式距离。然后依据两两第一配方之间计算得到的欧式距离大小进行判断,距离越小表示两配方越相似。根据相似度对所有第一配方进行分类,距离较小者判定为属于同一类别。采用欧式距离度量第一配方间的差异,可以充分利用高维矩阵中各维度上的特征数据,量化判断两配方的相似性,进行合理划分。
24、可选的,所述根据聚类算法对所述高维特征矩阵中各所述第一配方进行分类,得到各所述第一配方的分类结果之后,还包括:
25、根据各所述第一配方的分类结果,计算所述聚类算法的聚类数量;
26、若所述聚类数量超出对应的标准范围,则调整所述聚类算法中的最小半径,并重新执行所述根据聚类算法对所述高维特征矩阵中各所述第一配方进行分类,得到各所述第一配方的分类结果的步骤,直至所述最小聚类数量处于所述标准范围内。
27、通过采用上述技术方案,计算得到当前分类产生的聚类数量,聚类数量能够直接反映分类的效果。然后根据聚类数量大小来判断分类是否进行了过度划分或过度混合。如果聚类数量不在合理范围内,则说明出现了上述问题。针对存在问题的分类结果,该方案通过调整聚类模型中的最小半径参数,改变聚类的敏感度,重新执行配方的分类处理。通过不断调整最小半径,重复分类试验,直到获得了合理的聚类数量。
28、可选的,所述根据各所述第一配方的分类结果,计算所述聚类算法的聚类数量,包括:
29、将各所述第一配方的分类结果代入第一预设公式,得到所述聚类算法的聚类数量;
30、其中,所述第一预设公式为:
31、nε(x)={y|dist(x,y)≦ε};
32、式中,x和y分别表示分类结果为同一类中两个第一配方的向量,ε表示所述聚类算法中的最小半径,nε(x)表示包含所有与x距离不超过ε的y的集合,dist(x,y)表示x和y之间的欧式距离。
33、通过采用上述技术方案,将第一配方的分类结果代入预先定义的聚类数量计算公式。然后,根据分类结果中同一类别内两两第一配方向量间的欧式距离,以及预设的聚类最小半径参数,判定这两向量是否属于同一聚类。通过统计该类别下所有与给定向量距离在阈值内的配方数量,即得到该类别的聚类数。汇总所有类别下的聚类数,即可得到整个分类方案最后的总聚类数量。
34、可选的,所述方法还包括:
35、当对新的第二配方进行分类时,提取所述第二配方中所含物料的特征信息,对所述第二配方中所含物料的特征信息进行编码,得到所述第二配方的特征编码,量化各所述第二配方的特征编码,得到所述第二配方的特征向量;
36、根据第二预设公式,计算所述第二配方的特征向量与各所述第一配方的特征向量的余弦相似度,得到所述第二配方与各所述第一配方的相似度;
37、将所述第二配方分类至最高的相似度对应的第一配方的分类结果中;
38、其中,所述第二预设公式为:
39、
40、式中,si表示所述第二配方和第i个所述第一配方的相似度,w表示所述第二配方的特征向量,zi表示第i个所述第一配方的特征向量。
41、通过采用上述技术方案,当需要对新的第二配方进行分类时,首先对第二配方进行特征提取和编码,得到其数字特征向量。然后基于余弦相似度算法,计算第二配方向量与第一配方分类结果中各类别中心向量的相似度。通过判断第二配方与哪个第一配方类别中心向量相似度最高,即可判定第二配方最匹配的分类类别。该方案利用了第一配方分类结果中提取的类别特征中心,实现了对新配方的自动归类。
42、在本技术的第二方面提供了一种配方分类系统,所述配方分类系统包括:
43、特征编码提取模块,用于提取待分类的多个第一配方中所含物料的特征信息,对各所述特征信息进行编码,得到各所述第一配方的特征编码;
44、高维特征矩阵构建模块,用于量化各所述第一配方的特征编码,得到各所述第一配方的特征向量,根据各所述第一配方的特征向量,构建高维特征矩阵;
45、第一配方分类模块,用于根据聚类算法对所述高维特征矩阵中各所述第一配方进行分类,得到各所述第一配方的分类结果,根据所述分类结果对各所述第一配方进行分类。
46、在本技术的第三方面提供了一种计算机存储介质,所述计算机存储介质存储有多条指令,所述指令适于由处理器加载并执行上述的方法步骤。
47、在本技术的第四方面提供了一种电子设备,包括:处理器、存储器;其中,所述存储器存储有计算机程序,所述计算机程序适于由所述处理器加载并执行上述的方法步骤。
48、综上所述,本技术实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:
49、通过采用本技术技术方案,对第一配方的特征信息进行提取、编码、向量化处理,构建了包含多条第一配方数字特征的高维特征矩阵。基于该高维特征矩阵,采用聚类算法根据配方特征的相似性对各第一配方进行自动分类,得到每条第一配方所属的类别。进而可以根据分类结果对数据库中的大量第一配方进行集中管理和处理。
50、相较于传统人工逐一判断归类的方式,该方法实现了配方信息的数字化表达和向量化处理。通过构建统一的高维特征矩阵数据格式,使配方的特征可以量化表示,并应用聚类算法进行批量自动分类。相比人工,该技术方案可以实现对大规模配方信息的快速高效处理。
51、同时,该方法可以根据分类结果,通过调节聚类模型的参数如最小半径,优化配方的分类效果,使聚类数量保持在合理范围内。保证了同类别配方的内部一致性,也有效区分了不同类别之间的差异。还可以基于类别特征中心,对新配方进行自动归类。
- 还没有人留言评论。精彩留言会获得点赞!