一种跨视野颞骨CT影像自动校准方法
本发明属于医学影像处理领域,特别涉及一种为融合不同视野特征对抗学习的视野鉴别器,对大视野和局部视野的颞骨ct影像进行通用的自动几何校准的方法。
背景技术:
1、数据采集过程中存在姿势不对齐,使得原始图像的几何校正成为提取可靠信息的必要预处理步骤。几何误差会导致重建图像产生位置偏移和形态旋转等错位现象。为了消除这些图像偏移,需要对颞骨ct影像进行刚性几何校正,包括确定旋转点和旋转角度。因此,校正后的图像中物体的几何形状与预期更匹配,结构一致性更佳。建立校正后影像与地面空间的几何关系,不需要复杂的、局部的数学变换。数学变换建立了三维图像空间和对应的三维地面空间之间的几何关系。
2、依据解剖结构的特点,在颞骨ct中外半规管的位置形态与标准坐标系中水平面最为相近,因此,我们建立一种以外半规管为基准的空间几何校正方法。颞骨影像依据设备分为hrct图像和uhrct图像,hrct图像采集范围更广,可以涵盖双侧颞骨区域范围,其间隔为0.625mm;uhrct分辨率更高,显示更清晰,相邻扫描切片层间距为0.1mm,不过采集视野更小,只能显示单侧的颞骨结构。在已有的工作中,我们分别建立了一套完整的针对uhrct和hrct的几何校准方法。但是目前尚未有一种模型方法能够满足对两种不同视野颞骨ct影像进行同时校正的需求。因此,本发明提出了一种针对不同视野分辨率的数据进行共同特征提取,并结合对抗迁移的思想,设计一种视野鉴别器,用以区分不同视野的数据特征,以促进模型提取器更好的融合uhrct和hrct视野特征。
技术实现思路
1、本发明的目的在于克服现有颞骨几何校准方法难以同时处理跨视野ct影像的几何校正问题。对于两个不同视野的数据集,现有方法通常需要针对不同的视野图像进行分别独立建立模型来处理。在医学影像处理任务中,如果使用一个模型同时对两个数据进行训练,那么可以让模型同时学习到两个视野数据集的知识,对不同数据之间进行融合。如果将两个视野数据集同时送入分割网络中,网络会向促进二者融合的方向迁移,进一步提升促进特征融合的网络性能。但是,目前的训练方法将每个数据集视为独立的个体,尚未有一种模型表示方法对模型之间的相对关系进行区分表示,以对抗的方式促进二者的融合,并能随着训练轮次的增加同时形成“融合-区分”的协同训练对抗范式。此外,对于大量医学影像而言,数据分布的不同会降低算法模型的泛化能力。
2、针对以上问题,提出了一种基于对抗迁移的跨视野颞骨ct影像自动校准方法,用于双分辨率数据集自动分割及几何校准的标准坐标系建立。基于该模型,在训练阶段依据网络解码端设计一个视野鉴别器用以区分两视野特征与主干网络融合两视野特征形成对抗,同时结合半监督学习范式降低标注数据影像,增强模型泛化能力,实现颞骨ct影像自动分割校准。
3、本发明是采用以下技术手段实现的:
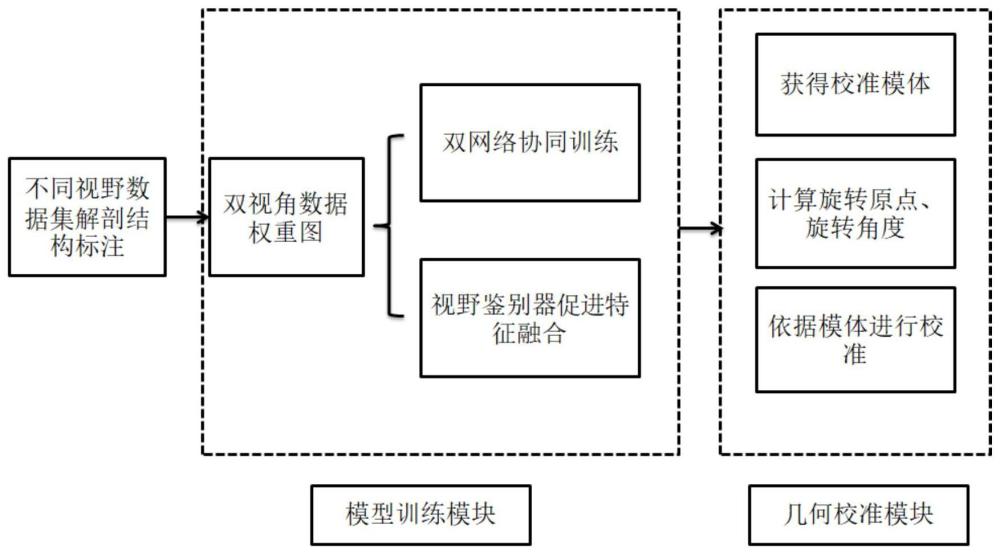
4、一种基于空间外半规管关键结构的颞骨ct影像自动校准方法。该方法整体分为五个主要部分:基于骨干编解码网络提取特征、双视角切片权重图、基于半监督范式的数据协同训练策略、视野鉴别器促进特征融合的对抗迁移思想、几何形态学校准。如图1所示。
5、该方法具体包括以下步骤:
6、1基于编解码网络提取特征
7、首先,在数据预处理上,uhrct原始数据大小为650×650×370大小的立方体,间隔单位为0.1mm。hrct原始数据大小为512×512×200,由于三维体数据占用资源巨大,需要对数据进行预处理操作,在uhrct上首先对原始图像下采样处理,缩放到尺寸为224×224×160大小,对于hrct图像,由于hrct包含颞骨双侧数据,因此将数据以中心裁减为成对的200×200×80大小。
8、其次,在主干分割网络结构选取上,采用三维骨干网络vnet为主要特征提取器,vnet网络架构是一种基于体积的全卷积神经网络,主要用于完成图像分割任务。通过卷积从数据中提取特征,并在每个阶段的最后通过使用适当的步幅降低其分辨率。网络的前半阶段由编码路径组成,而后半部分对信号进行解码,直到还原到其原始大小为止。编码阶段被不同分辨率下的操作分为不同的阶段,每个阶段由卷积层、正则化层以及激活层组成,第一阶段执行1次卷积操作,第二阶段执行2次卷积操作,第三阶段执行3次卷积操作,第四次、第五次均执行3次卷积操作。借鉴resnet的残差连接,每个阶段的卷积过程都会去学习残差,输入的特征图在每次卷积和非线性激活后会和原先输入地逐点相加,然后进行下采样操作。每次卷积的卷积核尺寸都是5×5×5。下采样过程是通过2×2×2的卷积核,步长为2,做卷积运算。由于第二个操作仅通过考虑不重叠的卷积块提取特征,因此所得特征图的大小减半。此外,由于特征通道的数量在v-net压缩路径的每个阶段都加倍,并且由于模型被表示为残差网络,因此我们借助这些卷积运算将特征图的数量加倍,降低分辨率。同时将非线性激活函数应用于整个网络。
9、最后,在送入网络时,将预处理后的三维ct影像进行随机裁减,获得112×112×64大小的数据立方体,并且采用随机翻转操作进行数据增强,防止网络模型过拟合同时增强模型的鲁棒性和泛化能力。vnet网络结构示意图如图3所示。
10、2基于权重图的双视角注意力计算
11、本发明一个主要特点在于给定标注数据每个体素一个额外权重为了更好的利用标注数据的半监督范式,传统的网络通常基于整体标注数据进行学习,这样往往难以充分利用有标注数据,而且模型稳定性不强。由于外半规管在空间中所占体积小,而大部分体素处于无目标区域,模型往往容易在无目标区域学不到特定特征,采用每个体素给定权重值的方法,会对网络模型产生一种特定的引导机制,在权重高的地方着重学习模型特征,在一次训练区域中模型着重向权重高的地方学习,采用一种区域协调训练方法。
12、通过在两个方向上为三维立方体数据设置一个最大切面层,对于标注数据中的不同切片,考虑每个切片在可信度上的重要性。对于横断面上的视角权重,假设标签传播的衰减率为一定值,则切片i的可信度可以表示为wi=αd,其中d为切片i到选取最大截面切片的距离,α=0.95为衰减率。在此基础上,为标注数据中的每个体素设置了权重:
13、
14、同理,在矢状面上的权重图记为wb,从两个视角分别设置切片权重图,之后分别送入分割网络na和nb中,其中na和nb具有相同的网络结构,网络可以对同样的数据从两个视角进行互补学习,会学习到更加全面的特征,提高模型性能。
15、3基于半监督范式的数据协同训练
16、为了解决标注数据难以获取的问题,方案整体采用半监督学习框架。首先,将训练数据分为标注数据和未标注数据,标注数据存在真实标签可以进行特定的约束,未标注数据不存在标签,需要通过网络从标签数据中学习,对未标注数据给定伪标注作为虚拟标签以实现监督损失训练,随着模型不断优化,网络对数据学习能力越来越强,性能更稳定,生成的伪标签也越来越好。因此在训练初期阶段,需要对伪标注指导的监督训练设置较低的权重,随着模型性能提升,逐渐提高伪标签的监督权重,以着重利用未标注数据继续优化模型性能。网络权重具体设置见公式(6)。
17、模型训练的监督损失包括加权交叉熵损失和dice损失,分别表示为:
18、
19、
20、其中h、w、d分别为三维影像数据的高度、宽度和深度,wi为权重图w的第i个体素,pi,yi分别表示体素i的前景概率和伪标签概率。
21、监督损失是交叉熵损失和dice损失的加权和:
22、
23、对于那些没有标注的序列数据,两个分割模型相互教导他们的预测。在一次训练迭代中,na将权重图wa作为输入,生成其独热编码预测,并作为nb的伪标签生成掩膜,以便更好地进行交叉监督。使模型能够同时学习到两个视角的互补特征。类似地,nb将na的掩蔽独热预测作为伪标签。损失的表达式为:
24、
25、其中mi表示掩码中的值,pi和yi分别表示两个模型预测的前景和独热伪标签的概率。
26、对于训练的后期阶段,监督损失主要来自于已标记的切片,而这些信息已经被分割模型学习到,因此保持监督损失权重过高是无济于事的。相反,应该增加交叉监督权重,因为两个网络可以通过交叉监督来纠正噪声伪标签带来的错误并达成共识。因此,分割总体目标是lsup和lcross的加权和:
27、lseg=(1-λ)lsup+λlcross (6)
28、其中λ是一个从0逐渐增加到最优交叉监督权重0.8的动态参数,每迭代500次时动态变化函数为其中为上一次迭代数值,λ为变化后的赋值,直至变化到大于或等于0.8时刻,λ不再变化,恒定为0.8。依据公式(1)对三维立方体数据中每个体素点进行权重分配
29、4基于视野鉴别器的特征融合
30、本发明特点是结合网络特点设计一个视野鉴别器,记为d,以主干网络形成对抗的方式促进跨视野特征融合。视野鉴别器的提出解决了传统方案中模型能力单一化,迁移学习中没有促进特征融合的有力模型的问题。为了使视野鉴别器获得更多有用的信息,提高对抗学习的准确性,在视野鉴别器中,本方案考虑了四层表示的使用。每个分割网络na和nb在上采样路径中提取的特征表示,共4种不同尺度的特征表示,作为视野判别器d的输入。输出中的每个空间单元表示对应图像像素属于目标域的概率。在视野判别器中,通过使用4个步长为3的卷积模块(包括一个3×3×3卷积操作和relu非线性激活层),三个反卷积层(卷积核大小为3,步长为1,边缘填充为1)和一个正则化率为0.5的正则化层来判别hrct和uhrct两个不同视野数据集。具体见图3所示。视野鉴别器网络损失为交叉熵损失:
31、lda=-∑xp(x)log q(x) (7)
32、其中p(x)为真实的概率分布为,q(x)为预测的概率分布。
33、分割网络整体损失为公式(8)
34、l=lseg-λdalda (8)
35、其中λda是一个固定的静态参数,依据经验设置为0.1。
36、5几何形态学校准
37、第一步,对分割后的半规管进行二值图像细化,获得半规管的骨架。这种算法能将一个连通区域细化成一个像素的宽度,用于特征提取和目标拓扑表示。
38、具体过程为:
39、1.将输入的3d图像转换为二值图像,即只包含目标和背景的图像。
40、2.使用形态学膨胀操作将图像中的所有连通区域向外扩张,直到它们相互接触为止。
41、3.使用形态学腐蚀操作将上一步膨胀后的图像中的所有边缘向内收缩,直到它们与骨架相连为止。
42、4.将腐蚀后的图像再次转换为二值图像,并使用形态学膨胀操作将骨架以外的所有区域向外扩张。
43、5.重复步骤3和步骤4,直到骨架不再发生变化为止。
44、
45、
46、式中其中i代表目标图像,s代表一种运算法则,u代表结构元素,u对i的腐蚀记为iθu,θ代表腐蚀操作,操作代表查找图像中的结构元素,k代表进行的运算次数,k代表总的运算次数。
47、在每次进行形态学操作时,均需对图像中的像素进行更新。通过膨胀操作将与目标像素相连的所有像素的值设置为目标像素的值;通过腐蚀操作将与骨架像素相连的所有像素的值设置为骨架像素的值。所有形态学操作均采用3×3×3大小的立方体的结构元素进行。通过反复进行形态学膨胀和腐蚀操作,最终得到半规管的三维提取骨架,用于表示3d图像中的目标对象,便于理解和分析内部结构特征。
48、所得到的半规管数据是以一系列二值数据形式存储在计算机中的,是由一个一个体素点堆积而成。假如在满足半规管位置上记为1,其余位置记为0,则体积可记为其中n为半规管在空间中位置。
49、第二步,半规管拟合在原有空间坐标系中拟合,该坐标系采用医学通用坐标系方法,矢状面为沿身体前后径所作的与地面垂直的切面,冠状面为沿身体左右径所作的与地面垂直的切面;水平面为垂直人体纵轴,与地面平行的切面。在坐标系中,由骨架算法得到的外半规管点云数据,通过最小二乘法对外半规管数据拟合平面。算法希望通过求解最小化误差平方和的方法来拟合一个平面方程。
50、拟定最小二乘法的矩阵形式为:
51、az=b (11)
52、其中a为t×r的矩阵,z为r×1的列向量,b为t×1的列向量。当找到向量z使得||az-b||最小,则z为该方程的最小二乘解。
53、在得到拟合的平面方程后,即可确定该拟合平面法向量,通过法向量之间的夹角,可以分别计算半规管之间的相互夹角以及半规管与坐标系平面之间的夹角。
54、第三步,基于现有拟合平面和骨架提取点云数据,以拟合平面为基准将三维影像数据校准到空间标准坐标系上。拟定旋转坐标原点为x0、y0、z0,所确定的与标准坐标系角度分别为θx、θy、θz,则依次以绕x、y、z轴的顺序旋转校准,绕x轴校准时以(y0,z0)为旋转原点,影像整体沿x轴旋转θx度,同理可得,绕y轴校准时以(x0,z0)为旋转原点,影像整体沿y轴旋转θy度,绕z轴校准时以(y0,z0)为旋转原点,影像整体沿z轴旋转θz度。
55、本发明与现有技术相比,具有以下明显的优势和有益效果:
56、本发明提出了一种跨视野颞骨ct影像自动校准方法,作为医学影像依据相应结构关系指导建立标定坐标系。通过统计已有体素级标注的颞骨ct影像,建立单侧uhrct和双侧hrct跨视野外半规管结构分割模型,以特征对抗的方式促进不同视野特征的相互融合,提高模型表征能力,基于医学影像中人体结构的位置及各个结构之间的相对位置固定的特点,在影像学校准依据外半规管空间结构位置满足条件的基础上,以该分割结构结果作为校准基准,结合其自身形态特点,依据半圆形结构进一步设计相应的旋转矩阵参数以确定旋转原点和旋转角度。所述方法通过建立相对位置坐标系,微小结构分割模型,采用对抗网络促进两不同视野特征融合的思想,缓解不同医学影像数据整体分布差异造成对算法模型泛化性的影响,同时进一步提升较难解剖结构的分割准确率,降低了时间复杂度。
57、本发明的特点:
58、1.提出了一种基于特征对抗一致性学习的网络架构——分割网络作为特征生成器,视野鉴别器学习区分不同数据上的图像级一致性。旨在提高分割网络从uhrct数据到hrct数据的知识迁移能力。
59、2.设计了一种半监督双视角协同训练范式,同时利用已标记的序列和未标记的序列通过交叉监督达成共识来减少噪声,该组件能够充分挖掘样本的先验知识。
60、3.提出的网络是一个轻量级网络,具有更快的推理速度。有效提高标签标注的效率,增加校准结果的精度和鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!