一种基于知识图谱的大模型prompt生成方法与流程
本发明涉及计算机,更具体地说,本发明涉及一种基于知识图谱的大模型prompt生成方法。
背景技术:
1、随着人工智能和自然语言处理技术的快速发展,大语言模型在各领域的应用日益广泛;大语言模型通过对海量文本数据的学习,能够生成准确、流畅的自然语言文本,广泛用于对话系统、智能客服、文本摘要等领域;然而,传统的大语言模型在生成提示时仅局限于语言模式匹配,缺乏对语义和逻辑的深层理解,在生成提示时缺乏对常识的推理能力,并且难以做出符合实际逻辑和常识的提示,同时容易陷入信息孤岛,无法利用跨领域的知识进行提示生成;
2、当然也存在将知识图谱与大语言模型结合的智能方法,例如公开号为cn117056493a的专利公开了基于病历知识图谱的大语言模型医疗问答系统,包括网站爬取电子病历数据;从初始病历数据中提取出关键实体及其之间的关系;构建病历知识图谱;对用户的提问进行意图识别;在获取查询的实体信息后,将查询获得的实体与病历知识图谱中的结点信息进行匹配;通过意图识别确定决策方式;将得到的关键信息和用户的提问作为输入,共同提供给大语言模型,再利用prompt工程生成具有个性化风格的答复;通过集成大语言模型和知识图谱的方式,全面提升医疗问答系统的准确性和流畅性;
3、但上述技术意图识别能力较弱,仅能识别初诊、复诊、建议、查询这类意图,存在一定的限制性;并且在生成答复时,仅根据用户意图与知识图谱中的匹配节点的相关信息,导致答复的完整性不足以及知识的深度不足,无法根据用户意图作出详细和全面的答复;
4、鉴于此,本发明提出一种基于知识图谱的大模型prompt生成方法以解决上述问题。
技术实现思路
1、为了克服现有技术的上述缺陷,为实现上述目的,本发明提供如下技术方案:一种基于知识图谱的大模型prompt生成方法,包括:
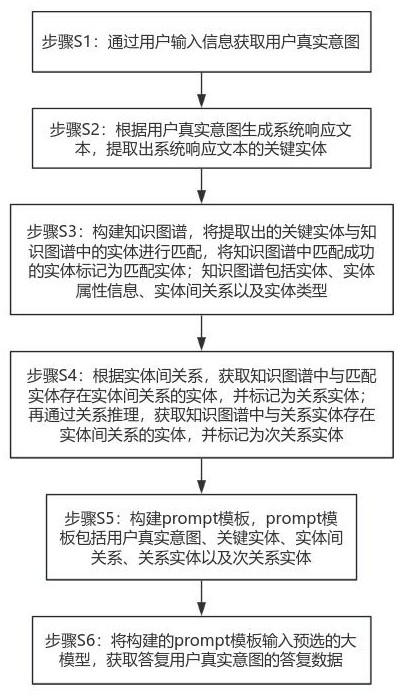
2、步骤s1:通过用户输入信息获取用户真实意图;
3、步骤s2:根据用户真实意图生成系统响应文本,提取出用户输入信息的关键实体;
4、步骤s3:将提取出的关键实体与知识图谱中的实体进行匹配,将知识图谱中匹配成功的实体标记为匹配实体;知识图谱包括实体、实体属性信息、实体间关系以及实体类型;
5、步骤s4:根据实体间关系,获取知识图谱中与匹配实体存在实体间关系的实体,并标记为关系实体;再通过关系推理,获取知识图谱中与关系实体存在实体间关系的实体,并标记为次关系实体;
6、步骤s5:构建prompt模板,prompt模板包括用户真实意图、关键实体、实体间关系、关系实体以及次关系实体;
7、步骤s6:将构建的prompt模板输入预选的大模型,获取答复用户真实意图的答复数据。
8、进一步地,所述获取用户真实意图的方法包括:
9、步骤s101:对用户输入信息进行处理;
10、步骤s102:将用户输入信息进行多模态融合,将多模态融合后的用户输入信息标记为融合信息;
11、步骤s103:根据融合信息获取用户真实意图。
12、进一步地,所述用户输入信息包括文本数据、图像数据以及音频数据;
13、对文本数据进行处理的方法包括:
14、将文本数据进行分词操作;对词语进行停用词去除操作;对完成停用词去除操作后的词语进行词形还原,将不同形态的词汇还原为原始基本形式;
15、对图像数据进行处理的方法包括:
16、使用训练好的图像处理模型对图像数据进行分类和检测,获取有关图像内容的高级语义信息;高级语义信息包括物体识别、场景理解、物体之间的关系以及存在的情感;其中图像处理模型为卷积神经网络模型;通过卷积神经网络模型中的卷积和激活函数操作,将图像数据转换为中间层激活,将中间层激活作为特征向量;
17、对音频数据进行处理的方法包括:
18、使用训练好的音频处理模型将音频数据转换为文本数据,音频处理模型为循环神经网络模型;通过信号处理技术和音频分析算法提取音频数据中特征数据。
19、进一步地,所述多模态融合的方法包括:
20、步骤1:将文本数据、图像数据与音频数据进行对齐;
21、步骤2:将处理后的文本数据、图像数据对应的特征向量以及音频数据对应的特征数据进行特征融合,创建一个包含文本数据、图像数据以及音频数据的统一表示,即将文本数据、图像数据对应的特征向量以及音频数据对应的特征数据转换为一个统一的表示形式;
22、步骤3:分析文本数据、图像数据与音频数据之间的关联性。
23、进一步地,所述根据融合信息获取用户真实意图的方法包括:
24、将融合信息输入训练好的意图分析模型,获取用户真实意图;其中意图分析模型为支持向量机模型;用户真实意图为用户与系统交互时真正所要表达的意思或目的。
25、进一步地,所述系统响应文本包括系统对于用户真实意图的回答、建议和解决方案;
26、所述系统响应文本包括系统对于用户真实意图的回答、建议和解决方案;系统为与用户进行交互的系统;
27、使用自然语言生成技术根据用户真实意图生成系统响应文本;
28、自然语言生成技术由模版驱动或基于预训练的语言模型驱动,自然语言生成技术为nlg,nlg的原理包括:
29、模版驱动的nlg:
30、选择模版,,其中t为选择的模版,表示要选择的是使得概率最大的模版,i为用户真实意图,t为提供的t个模版;
31、填充模版,将用户真实意图通过填充函数填充进上述选择的模版,生成对应的系统响应文本,为,其中为系统响应文本,filltemplate为填充函数,填充函数根据所使用的nlg工具和开发环境确定;
32、基于预训练语言模型驱动的nlg:
33、生成序列,,其中为用户真实意图下,生成文本序列的概率,xl为文本序列,为生成的文本序列中的第i个词,为生成的文本序列中第1个词到第i-1个词的子序列,为在用户真实意图和已生成子序列的条件下,预测下一个词出现的概率,n为文本序列中词的数量;
34、top-k采样或束搜索,,其中表示要选择的是使得概率最大的文本序列作为系统响应文本。
35、进一步地,所述提取出用户输入信息的关键实体的方法包括:
36、步骤s201:将用户输入信息进行预处理;
37、步骤s202:将预处理后的用户输入信息输入训练好的实体提取模型,提取出用户输入信息的关键实体;
38、实体提取模型为bert模型,bert模型的原理为:
39、对于一个输入文本,首先将其分解为词语,然后将每个词语转化为其对应的嵌入向量;嵌入向量包括嵌入单词和嵌入句子位置;
40、嵌入单词et为;其中为单词的嵌入矩阵,为原始单词的词向量;
41、嵌入句子位置es为;其中为位置的嵌入矩阵,为原始单词在句子中的位置编码;
42、最终的输入表示为;
43、bert的核心是transformer encoder,由多个注意力头组成;输入表示einput被输入到transformer encoder中,经过多层的自注意力机制和前馈网络,得到上下文丰富的输出表示;
44、为了适应特定任务,在bert的输出上添加一个任务特定层;对于实体提取任务,可以使用一个全连接层wner来预测每个单词是否是命名实体:并且根据任务要求,定义规则来标记和提取关键实体;
45、用户输入信息输入实体提取模型后,获取每个词语的标签,从标签中提取出带有实体标签的词语,标记为关键实体。
46、进一步地,知识图谱包括实体、实体属性信息、实体间关系以及实体类型;实体属性信息为描述实体属性的标签;实体间关系表示不同实体之间的语义联系,描述知识图谱中实体间的各种关联和相互作用;实体类型定义了实体所属的类别,并定义实体间的通用属性和关系;
47、将提取出的关键实体与知识图谱中的实体进行匹配的方法包括字符串匹配和语义匹配;字符串匹配包括精确匹配和近似匹配,精确匹配为将提取出的关键实体对应的字符串与知识图谱中实体对应的字符串进行对比,若完全相同,则进行匹配;近似匹配为使用字符串相似度算法,计算关键实体对应的字符串与知识图谱中实体对应的字符串之间的相似度,将相似度最高对应知识图谱中的实体与关键实体进行匹配;语义匹配为使用词嵌入方式;词嵌入方式通过词嵌入模型,将关键实体和知识图谱中的实体转换为向量形式,通过计算向量之间的相似性进行匹配;
48、匹配成功后,将两种方法获取到的匹配实体进行合并,并从知识图谱中获取匹配实体对应的实体属性信息。
49、进一步地,关系推理的方法包括规则推理、图算法推理以及模型推理;
50、规则推理为利用预先定义好的规则,通过逻辑推理发现新的关系;
51、图算法推理为使用图算法发现实体之间的潜在关系;
52、模型推理为使用图神经网络模型,从知识图谱中学习并推理出新的实体间关系;图神经网络模型的原理包括:
53、图结构表示:
54、对于一个图,其中v为节点集合,e为边集合,对于每一个节点都存在一个特征向量表示节点的特征信息;
55、消息传递:
56、图神经网络模型的核心是通过消息传递机制,使节点能够聚合相邻节点的信息,对于节点,接收到相邻节点的消息,更新节点对应的特征向量;
57、消息传递的过程包括两部分:以及,其中为节点在图神经网络中第个卷积层的特征向量,为节点的相邻节点集合,为连接节点和的边的特征向量,包括边的权重与类型信息;为聚合函数,将节点相邻节点的信息进行聚合,包括求和与平均,具体选择取决于任务和网络设计,为激活函数,为连接节点和的边在图神经网络中第个卷积层的特征向量;
58、节点的特征向量在图神经网络中每一个卷积层都进行更新,经过多个卷积层的消息传递获得包含多个节点对应的信息和上下文联系的特征向量;
59、关系推理:
60、通过学习到节点的特征向量和连接节点对应边的特征向量,进行关系推理。
61、进一步地,所述构建prompt模板的方法包括:
62、通过用户真实意图,以确定用户的主要意图或查询主题,并根据用户真实意图定制prompt模板;将用户输入信息中的关键实体整合到prompt模板中;在prompt模板中为实体间关系、关系实体和次关系实体引入占位符,占位符用于表示实体间关系、关系实体和次关系实体。
63、进一步地,大模型为大语言模型,支持与用户通过自然语言对话进行交互,处理多种自然语言任务;
64、将实体间关系、关系实体和次关系实体替换prompt模板中对应的占位符;在将构建的prompt模板输入预选的大模型前,保留与上下文相关的信息,包括在本次用户输入之前的用户输入信息以及对应的系统响应文本;在将构建的prompt模板输入预选的大模型后,根据用户真实意图调整temperature参数、top-k参数以及top-p参数;
65、对大模型生成的答复数据进行解码,包括处理答复数据的格式和去除不必要的词汇;将解码后的答复数据反馈给用户。
66、一种电子设备,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现所述的一种基于知识图谱的大模型prompt生成方法。
67、一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被执行时实现所述的一种基于知识图谱的大模型prompt生成方法。
68、本发明一种基于知识图谱的大模型prompt生成方法的技术效果和优点:
69、通过知识图谱的支持,大模型能够更深入地理解用户提出的问题或需求,从而提供更准确、有针对性的答案或建议;利用知识图谱中的丰富信息,使得生成的prompt更具专业性和权威性,满足用户对高质量信息的需求;通过与知识图谱的紧密结合,大模型的提示生成不仅局限于语言模式匹配,还能基于知识图谱的推理能力提供更有深度的提示,使得模型在处理复杂问题时能够更全面地考虑多个方面的知识;为了提高用户体验,生成的提示模板可以根据用户的反馈进行动态调整,以更好地满足用户的期望和需求;该方法不仅提高了大模型的性能,还使得其在不同领域和场景中具有更广泛的适用性,为用户提供更全面、个性化的服务;综合考虑用户的输入、知识图谱的丰富信息以及上下文的变化,使得生成的提示更具智能性和灵活性,能够更好地应对复杂多变的用户需求。
- 还没有人留言评论。精彩留言会获得点赞!