一种基于策略因子和过载消解的硬实时准入控制方法
本发明涉及一种基于策略因子和过载消解的硬实时准入控制方法,属于计算机数据库系统和深度强化学习决策。
背景技术:
1、随着经济、社会和科学技术的蓬勃发展,计算机和电子技术所需处理的数据规模呈指数级增长,这对数据库技术提出了更为严格的要求。
2、实时数据库技术在众多领域有着广泛应用,如卫星定位等。这些应用的特性要求数据库能够在规定时间内高效完成数据的处理和存储。传统的数据库技术难以满足这些严格的实时性要求。特别是在硬实时系统中,其中,事务的截止期成为至关重要的考虑因素。任何一项任务若未能在规定的截止期内完成,都可能导致系统无法按照预定的时间限制响应事件。
3、硬截止期事务,或称硬实时事务,指具有严格截止期的事务。一旦错过截止期,可能会引发严重的后果。这些事务的执行必须具备高度可预测性,通常通过可调度性分析来实现。然而,在实际应用中,一个主要挑战在于:事务执行所需的资源通常是未知的。例如,事务的数据访问可能依赖于用户的输入或传感器输入,这增加了资源分配的不确定性。这种不确定性使得硬实时事务执行的效果变得复杂。如果通过准入控制与闭环反馈策略,拒绝一些事务进入系统,就能够避免有限的资源浪费在执行不可能及时完成的事务上。
4、现有技术中,bestavros等给出了一个实时数据库模型,并在此基础上研究了硬截止期事务的准入控制与过载管理问题,提出了一个事务模型,每个事务由两个部分组成:基本子事务与补偿子事务。其中,基本子事务的执行需求是事先未知的,而补偿子事务的执行需求是已知的。每当一个事务到达,实时数据库或者接纳这个事务,或者拒绝它。一旦这个事务被接纳,它必须被保证在截止期之前完成或者成功地提交基本子事务完成,或者安全地终止补偿子事务被完成。每个事务有一个截止期与一个价值,价值通常代表了这个事务的关键程度或者重要程度。准入控制器用于决定是否接纳新到达的事务。事务调度器管理两个事务队列:基本事务队列与补偿事务队列。每个被接纳的事务分成基本子事务与补偿子事务分别进入两个队列。但是,补偿子事务并不马上执行,它必须等待准入控制器的的指示。在这种模式下的缺点是:即使采用乐观的方法,补偿事务也不会被重启。因为补偿事务不会交迭执行,冲突时只需重启基本子事务。
5、hansson等给出了一个新的事务调度框架与过载管理算法,研究中考虑了硬截止期事务与固定截止期事务,并且每个硬截止期事务都有一个附带事务,这个附带事务具有较少的资源与处理器需求,万一系统出现过载,这个附带事务能够代替主事务,产生一个不太精确的结果。为了解决过载,有控制地放弃固实时事务,这个策略由过载消解器在准入控制层(拒绝新到的事务)与调度器层(抢占或者夭折当前正执行的事务)执行,调用硬实时事务的附带事务来代替其主事务。这个策略由消解器在并发控制与调度器两个层次上进行。前者为了得到较好的系统利用率,避免盲目放弃非关键事务导致系统利用率低下。给出的事务调度框架由动态准入控制器、事务调度器、过载消解器与事务分派器组成。它基于事务的最坏情况执行时间,一旦一个事务被接纳,则要求的处理器时间被预留。当一个关键事务不能被接纳,系统调用过载消解器。hansson等研究工作的优点之一在于:把过载管理、准入控制分开,进一步地,过载消解能够通过平衡多种策略并确定最优或者接近最优的方法。但是,其存在的问题在于:没有很好地讨论并解决控制与事务调度、系统过载之间的相互影响以及端到端的反馈控制。
技术实现思路
1、本发明的目的是针对现有技术存在的缺陷和不足,创造性地提出一种基于策略因子和过载消解的硬实时准入控制方法。本方法结合了深度强化学习模型,对硬实时事务准入控制与闭环反馈分开进行研究,并针对硬实时事务的硬性执行条件做确定性的控制并通过实时的闭环反馈,以保证进入系统执行的实时事务能达到近100%的执行准确率,避免了硬实时事务超过截止期的执行产生灾难性的结果,以及关键硬实时事务因过载问题得不到及时的准入响应。
2、本方法的创新点包括:提出了一种新的面向关键任务时间窗口的硬实时事务准入与闭环反馈过载消解方法。该方法使用深度强化学习模型dqn(deep q-leaning network)实现硬实时事务的准入控制,使用gru模型实现硬实时事务的闭环反馈控制,并通过价值成本执行过载消解机制。本方法特别关注数据库中硬实时事务在时间窗口内产生可预测的判断,以确保事务能够高准确率地在规定的时间限制内完成。通过这一创新性方法,提高了硬实时事务执行的准确率,使其更好地适应复杂的任务环境和时间要求。
3、本发明采取的技术方案如下。
4、一种基于策略因子和过载消解的硬实时准入控制方法,包括以下步骤:
5、步骤1:设计准入策略。
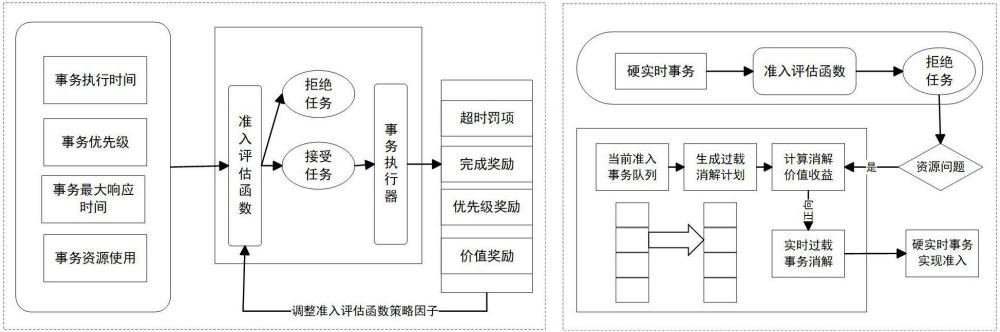
6、首先,定义事务各个层次的输入输出及状态变量,包括任务的执行时间、任务的优先级、任务的最大响应时间、任务资源需求。
7、定义动作空间,对所给事务有明确的动作标签。包括:接受、拒绝或推迟,同时定义触发各动作的条件。
8、设计奖罚机制,对满足条件的任务操作进行奖励,对未能满足设定条件的任务操作进行惩罚,以此提供强化学习控制的基础。
9、然后,构建深度强化学习模型,根据奖惩机制设计事务奖励函数。
10、最后,决策过程优化,根据上述模型与目标函数进行决策过程的优化,进而实现基于深度强化学习的准入策略控制。
11、步骤2:闭环反馈。
12、首先,获取准入控制动作决策,调整步骤1中得到的准入策略,并和当前环境状态一同作为反馈机制的输入。
13、然后,对输入的影响因素进行量化,实现数据特征升维。
14、最后,利用闭环反馈模型的输出进行反馈控制调整。
15、步骤3:基于价值驱动的过载消解。
16、首先,定义硬实时事务的收益函数,综合考虑实时事务的收益与紧急程度。定义系统资源利用率函数,定量不同系统资源对总体资源的利用程度。定义过载消解函数,衡量硬实时事务的收益和系统资源利用率之间的关系。
17、然后,执行过载消解决策,当系统资源利用率达到设定阈值时,通过执行过载消解函数来评估每个已接纳的硬实时事务的成本。
18、有益效果
19、本发明,与现有技术相比,具有以下优点:
20、1.本发明采用dqn的准入控制。使用深度强化学习的dqn模型能够适应复杂和非线性的系统动态,学习在不同情境下的最优准入策略。gru的闭环反馈控制中,gru网络可以根据dqn的决策和环境状态实现灵活的闭环反馈控制,允许系统根据实时情况进行调整。两个模型通过协同训练,可以端到端地学习系统的准入和闭环反馈控制策略,提高了系统整体性能。
21、2.本发明提出了一种过载消解机制,避免准入控制机制拒绝任务是因为资源的问题,通过执行基于价值驱动的过载消解机制,根据当前的准入事务队列,生成过载消解计划,计算消解的价值收益,若为正向,则实施过载事务消解,使得关键的硬实时事务实现准入。
- 还没有人留言评论。精彩留言会获得点赞!