一种基于多元模型自适应与改进粒子群的气动优化方法与流程
本发明涉及气动优化,尤其涉及一种基于多元模型自适应与改进粒子群的气动优化方法。
背景技术:
1、气动优化设计是指通过对汽车、飞行器、建筑物等物体的气动特性进行优化,以提高其性能、降低阻力、提高稳定性等方面的技术。
2、目前在气动优化领域使用比较广泛的优化算法主要分为进化算法和群体智能算法,这些算法在优化过程中采用不同的机制和策略,以实现搜索最优解的目标。往往根据不同实际应用问题的性质、约束条件、求解目标和计算资源等因素对这些算法进行选择。
3、虽然这些算法具有全局搜索的能力,但它们同时也存在收敛速度慢、某些算法需要调整的超参数众多以及当出现数据量较小时优化效果不佳的情况,因此能够高效且适应小样本气动数据优化的气动优化算法的开发具有十分重要的意义。
技术实现思路
1、本发明要解决的技术问题是提供一种基于多元模型自适应与改进粒子群的气动优化方法,提高传统优化方法的优化效果提供更优的设计参数组合,在改善气动性能方面取得进展,建立气动优化模型的整体结构,实现同样对于小样本气动数据优化的高效和稳定性,为提升气动性能和提高工程效率提供重要的基础数据。
2、本发明提供一种一种基于多元模型自适应与改进粒子群的气动优化方法,包括以下步骤:
3、步骤s1:采集气动数据和影响因素的数据,将气动数据作为待优化的目标值,对目标值和影响因素的数据做预处理,所述预处理包括剔除异常值:采用统计法,若某数据点明显偏离标准差或均值则剔除;从而减少干扰数据。其次,对数据进行归一化处理,消除尺度差异,有助于提高模型的稳定性和准确性;
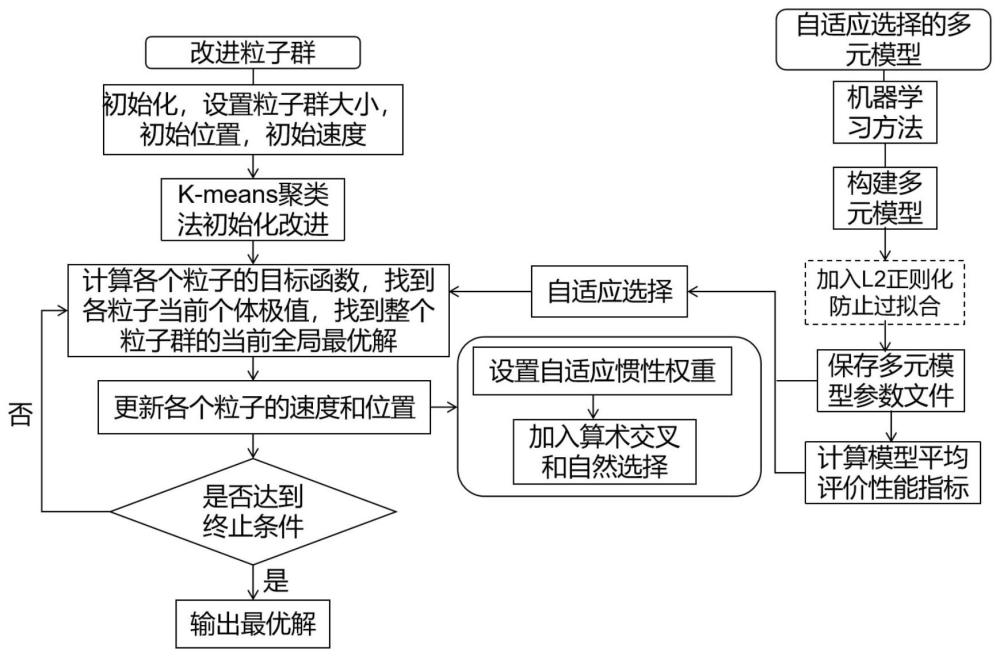
4、步骤s2:采用预处理后的数据对多个利用机器学习方法建立的预测模型作为优化过程的元模型进行训练,保存每个训练好的元模型参数文件和各个元模型的平均评价指标;所述参数为超参数,包括:权重、迭代次数、核函数;
5、步骤s3:元模型输出优化结果,根据优化结果和平均评价指标,自适应选择最优的元模型;所述优化结果为元模型训练后输出的优化后的气动数据值;
6、步骤s4:将所述元模型的参数文件加载后封装为粒子群算法的适应度计算函数,从而优化适应度,输出优化后的输出结果,然后将输出结果反归一化后,得到最优的气动数据值。
7、进一步地,所述采用可视化分析方法绘制数据的散点矩阵图包括:使用python的seaborn库中的pairplot函数对数据集xn={(x1,y1),(x2,y1),…,(xn,y1)}绘制散点矩阵图,xn表示第n个影响因素数据,y1表示气动数据;
8、所述对数据进行归一化处理是使用sklearn库中preprocessing的minmaxscaler()函数将不同尺度和范围的数据映射到统一的[0,1]范围内。
9、所述预处理还包括:
10、采用可视化分析方法绘制数据的散点矩阵图,分析不同影响因素与目标值之间是否呈显著的线性相关性以及数据的分布情况,发现变量间的线性趋势、和聚类特征,通过对线性趋势和聚类特征的分析,完成模型的初步选择;
11、所述分析不同影响因素与目标值之间是否呈显著的线性相关性以及数据的分布情况包括:
12、根据散点矩阵图中的各自变量与因变量的线性趋势(在图中呈现出一条直线或近似直线的趋势),分析数据之间存在线性关系,从而进行第一次初步筛选:如果数据呈现出明显的线性趋势,则选择线性回归模型,所述线性回归模型包括梯度下降的线性回归模型、岭回归模型;它可以很好地拟合线性关系。对于非线性趋势,考虑使用更复杂的模型,选用多层感知机模型、随机森林模型、决策树模型、极端梯度提升模型、bp神经网络模型;从而完成第一次初步筛选;
13、判断散点矩阵图的聚类特征,聚类特征表示数据点在散点矩阵图中呈现出聚集或分组的趋势,该趋势表示数据点间存在某种相似性或群体结构。当数据出现明显的聚类特征,即各散点分布的间距小于设定的距离阈值时,模型的初步选择为在第一次初步筛选得到的预测模型基础上还包括聚类算法(例如,层次聚类或k均值聚类等);当各散点间距较大分散较稀疏时则聚类特征不明显时,第一次初步筛选得到的预测模型则为模型的初步选择。
14、进一步地,所述采用可视化分析方法绘制数据的散点矩阵图包括:使用python的seaborn库中的pairplot函数对数据集xn={(x1,y1),(x2,y1),…,(xn,y1)}绘制散点矩阵图,xn表示第n个影响因素数据,y1表示气动数据。
15、进一步地,所述预测模型包括:多层感知机模型(mlp)、梯度下降的线性回归模型、随机森林模型、决策树模型、极端梯度提升模型(xgboost)、bp神经网络模型和岭回归模型;
16、其中多层感知机的公式为:
17、
18、其中xi表示训练集数据;
19、wi表示训练过程中的权重;
20、f表示基于神经网络的机器学习模型输出;
21、为激活函数;
22、所述采用预处理后的数据对多个利用机器学习方法建立的预测模型作为优化过程的元模型进行训练,保存每个训练好的元模型参数文件和各个元模型的平均评价指标;其中模型训练过程中使用线性整流函数(relu)作为模型训练过程中的正则化项,避免出现过拟合的情况;同时模型用mse计算真实值与预测值的欧氏距离并作为模型训练的损失函数,计算公式为:
23、
24、
25、其中x为上一层神经元的输出值;
26、e为自然底数;
27、yi表示真实值;
28、表示预测值;
29、nsamples为训练集的样本大小;
30、然后使用多个评价指标:均方根误差(rmse)、平均绝对百分比误差(mape)和确定系数r2(r-squared)对每个模型性能做出评价;
31、其公式为:
32、
33、其中,ε代表一个小的正数,通常用来避免分母为零的情况,|yi|是真实值的绝对值;
34、元模型为多层感知机模型时,其评价指标为rmse、r2,
35、元模型为线性回归模型时,其评价指标为mape、r2,
36、元模型为随机森林模型时,其评价指标为mape、r2,
37、元模型为决策树模型时,其评价指标为mape、r2,
38、元模型为xgboost模型时,其评价指标为mape、r2,
39、元模型为bp神经网络模型时,其评价指标为mape、r2,
40、元模型为岭回归模型时,其评价指标为r2;
41、将数据输入模型,训练至少三次以上,保证训练结果的可靠性;每训练一次得到一个评价指标值,取若干次性能评价指标的平均值,得到平均评价指标,
42、保存训练好的元模型参数文件和平均评价指标,建立自适应选择模型。
43、进一步地,当存在模型的初步选择,则预测模型为初步选择后的模型。
44、进一步地,自适应选择最优的元模型包括:
45、基于数据的规模即样本量在预测和优化上的表现来动态选择不同的模型,取优化结果与指标权重之积的最小值对应选择出的最优模型:
46、
47、其中,j为第j个元模型,yj是优化结果值;aj表示每个元模型的性能指标,aj在本文中为r2,还可以扩展为取呈现正相关的评价指标,ρ为元模型的个数。
48、进一步地,所述粒子群算法为改进的粒子群优化算法,所述改进的粒子群算法是一种采用k-means聚类改进初始化、引入遗传算法的算术交叉和自然选择、加入自适应惯性权重的粒子群算法,通过不断迭代更新粒子的速度和位置,粒子群逐渐搜索到最优解。包括:初始化、加入算术交叉和自然选择中之一或者两种的改进:
49、所述初始化改进利用k-means聚类方法,让数据以原始初始化方式随机产生粒子位置,而后将生成的样本划分为不同的簇,每个簇则代表一个特定的区域或解空间,将簇中心作为初始位置;
50、随机生成的粒子位置:
51、[|p1|,|p2|,…,|pn|] (6)
52、其中,pn是第n个粒子的位置,n表示总粒子数;
53、取聚类中心的位置点,方法为:
54、[|p1|,|p2|,…,|pn|],[|p1|,|p2|,…,|pn|],…,[|p1|,|p2|,…,|pn|] (7)
55、
56、取k个聚类中心点,当k=j从n个随机生成的粒子位置p中得到j个聚类中心的位置点;
57、公式(7)表示多次迭代生成的多个粒子的位置;公式(8)表示在每次迭代时,将新生成的粒子位置按k个聚类中心点进行划分,直到所有的粒子被划分完。公式(8)的粒子划分只是一个示例。
58、所述算术交叉和自然选择改进为:当更新了个体和全局历史最优位置与适应值后,以当前粒子群循环的最优解为中心构造采样区间,并将新采样的位置随机选择两个粒子进行算术交叉,而后以遍历更新所有粒子后,加入自然选择,根据优胜劣汰选择出最优的粒子位置、速度、个体最优位置和个体最优适应值,在增加粒子群多样性分布的同时还能获得高质量的粒子;速度和位置更新,公式为:
59、
60、公式中:i和j表示第i个粒子和第j维,其中i=1,2,…,n;j=1,2,…,n;v表示粒子速度;
61、表示第it次迭代第i个粒子第j维的粒子速度;
62、ω为惯性权重,设置其在[0.1,0.65]之间动态变化的参数,它决定了粒子在搜索空间中移动的速度和方向;
63、c1,c2是该算法的学习因子分别是个体学习因子和群体学习因子,它们决定了粒子在个体最优解和全局最优解之间权衡的程度,同时主要用其来调节粒子群步长的参数;
64、r1,r2为(0,1)之间的随机数,it是粒子群迭代次数;
65、表示在迭代第it次第i个粒子第j维的个体最优解;
66、表示在迭代第it次第i个粒子第j维的速度更新后的值;
67、表示在迭代第it次第i个粒子第j维的粒子全局最优解;
68、c1up表示个体学习因子最大值约束;
69、c2up表示群体学习因子最大值约束;
70、c1low表示个体学习因子最小值约束;
71、c2low表示群体学习因子最小值约束;
72、rd表示随机数;
73、exp()表示指数函数。
74、进一步地,改进的粒子群优化算法还包括自适应惯性权重的改进:采用线性变化策略,能减少参数的调整次数,自适应惯性权重的公式为:
75、
76、其中ω表示惯性权重,it表示当前迭代次数,maxit为最大迭代次数。ωmax和ωmin分别表示惯性权重的上限和下限。
77、与现有方案相比,本发明能够高效处理小样本气动数据,快速得到优化的气动数据值。具体收敛速度快、需要调整的超参数较少,具体有如下有益效果:
78、①本发明设计了一种基于多元模型自适应与改进粒子群的气动优化方法,该方法通过将多元模型自适应选择,改进粒子群算法(在粒子群算法中,每个解被称为一个粒子,所有的粒子都有一个位置和一个速度。每个粒子都会根据自己的经验和群体的经验来调整自己的位置和速度,从而逐渐接近最优解)和数据预处理技术相结合,使该组合模型具有更好且更高效的优化效果,在气动数据规模较小的优化设计中也能够获得更好的优化值,同时为提升气动性能和提高工程效率提供重要的基础数据。
79、②采用了数据预处理技术,对获得的输入数据在模型训练前进行全面分析。采用可视化分析方法绘制数据的散点矩阵图,分析不同影响因素与目标值之间是否呈显著的线性相关性以及数据的分布情况,帮助发现变量间的线性趋势、异常值和聚类特征,为后续多元模型选择提供依据;其次,对数据进行归一化处理消除尺度差异,提高模型的稳定性和准确性;
80、③提出自适应模型选择方法,以各个模型的平均评价指标在总评价指标所占的系数为适应值的权重,输出权重系数下适应值最小的模型,为各种规模的数据集提供灵活性地优化选择。
81、④采用改进的粒子群算法与多元模型作为其代理。在传统的粒子群算法的基础上利用k-means聚类算法重新初始化粒子,引入了遗传算法的算术交叉和自然选择,加入自适应惯性权重,减少了超参数调整次数、增加了粒子群的多样性且提高了粒子群算法的优化收敛速度与全局搜索能力。将自适应选择的多元模型与其结合,改善了优化目标结果,同时能灵活的适应不同规模的数据。
- 还没有人留言评论。精彩留言会获得点赞!