一种信息搜索方法、装置、计算设备及计算机程序产品与流程
本技术涉及自然语言处理,尤其涉及一种信息搜索方法、装置、计算设备及计算机程序产品。
背景技术:
1、随着互联网的日益普及,搜索已经成为日常生活中必不可少的应用。那么,如何快速准确地从互联网海量的数据中获取正确的信息,就成为现在搜索引擎技术的核心问题。在实际应用中,由于不同用户的年龄差异、文化差异,以及教育程度等不同,导致不同用户对同一问题的表述差异很大。这种文本不匹配导致的漏召回问题,严重影响用户的搜索体验。
2、在现有技术中,通常采用查询改写(query rewriting)的方式来解决漏召回问题,即对原始查询词拓展出改写词,这些改写词与原始查询词具有一定的相关关系。多个改写词与用户查询词一起做检索,从而确定出更符合用户搜索意图的结果。常见的一种生成改写词的方法为基于图方法进行语料挖掘。图方法如经典的协同过滤以及图嵌入(graphembedding)等,在搜索场景下,通过利用用户的查询词和对应文档(例如,对应被点击的文档)的关系构建图结构,来检索到与查询词相似的多个文档。然而,大多数真实网络都很大,包含大量节点和边。图方法应具有可扩展性,能够处理大型图。但定义一个可扩展的模型具有挑战性,尤其是当该模型旨在保持网络的全局属性时。
3、因此,需要一种新的信息搜索方案,来解决漏召回问题。
技术实现思路
1、本技术提供了一种信息搜索方法、装置、计算设备及计算机程序产品,以力图解决或者至少缓解上面存在的至少一个问题。
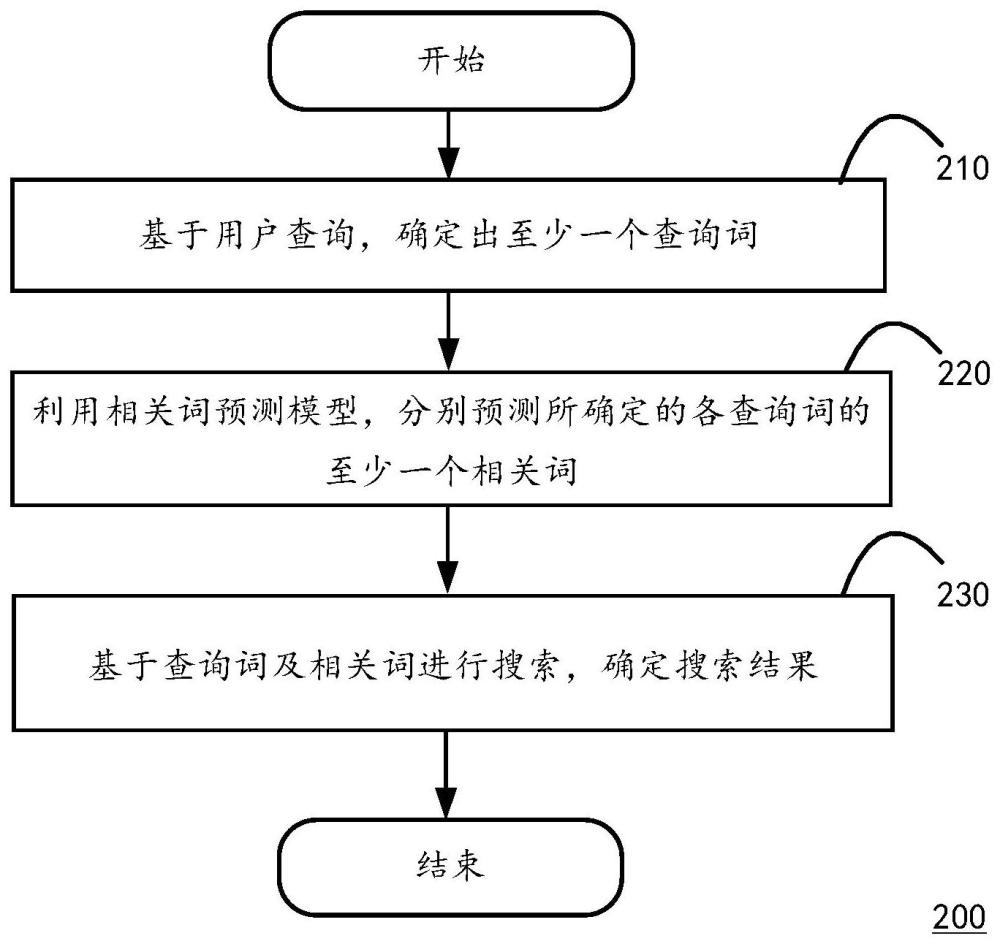
2、根据本技术的一个方面,提供了一种信息搜索方法,包括:基于用户查询,确定出至少一个查询词;利用相关词预测模型,分别预测所确定的各查询词的至少一个相关词;基于所述查询词及所述相关词进行搜索,确定搜索结果,其中,通过对翻译模型进行模型压缩得到所述相关词预测模型,且至少通过判别模型的输出数据,得到训练所述翻译模型的第一训练数据,以及至少通过所述翻译模型的输出数据,得到训练所述判别模型的第二训练数据。
3、可选地,在根据本技术的方法中,翻译模型适于对输入的查询词进行处理,来预测所述查询词对应的多个相关词;所述判别模型基于预训练语言模型,适于对输入的两个查询词进行处理,以输出指示所述两个查询词间相关性的相关值,其中,若所述相关值大于预设值,则确定两个查询词相关,若所述相关值不大于预设值,则确定两个查询词不相关。
4、可选地,根据本技术的方法还包括训练生成所述判别模型和所述翻译模型,包括:利用判别模型对查询词对进行处理,并至少通过所述判别模型处理后的输出数据,得到所述第一训练数据,其中所述查询词对包括两个具有相关关系的查询词;利用第一训练数据对翻译模型进行训练,以得到新的翻译模型,作为翻译模型;利用翻译模型对随机获取的多个查询词分别进行处理,并至少通过所述翻译模型处理后的输出数据,得到第二训练数据;利用第二训练数据对判别模型进行训练,得到新的判别模型,作为判别模型;重复迭代构造第一训练数据、对翻译模型进行训练、构造第二训练数据和对判别模型进行训练的步骤,直到满足条件时训练结束,生成训练好的判别模型和训练好的翻译模型。
5、可选地,根据本技术的方法还包括生成查询词对,包括:基于搜索点击日志,生成具有第一相关关系的第一相关样本,所述第一相关关系为两个查询词对应的点击文档相同;基于搜索交互过程,生成具有第二相关关系的第二相关样本,所述第二相关关系为多个查询词来自同一搜索交互过程;基于所述第一相关样本和所述第二相关样本,生成多个查询词对。
6、可选地,在根据本技术的方法中,至少通过判别模型处理后的输出数据,得到第一训练数据,包括:将所述查询词对分别输入所述判别模型进行处理,以输出对应两个查询词的相关值;选取相关值高的查询词对,并为所选取的至少一个查询词标注至少一个相关词样本;利用所选取的各查询词及相关词样本,构造第一训练数据。
7、可选地,在根据本技术的方法中,利用第一训练数据对翻译模型进行训练,得到新的翻译模型,包括:将所述第一训练数据中的各查询词分别输入翻译模型进行处理,以对应输出集束搜索约束下预测的多个相关词;基于预测的多个相关词及标注的相关词样本,对所述翻译模型进行训练,直到满足训练条件时训练结束,得到新的翻译模型。
8、可选地,在根据本技术的方法中,利用翻译模型对随机获取的多个查询词分别进行处理,并至少通过所述翻译模型处理后的输出数据,得到第二训练数据,包括:从搜索点击日志中随机抽取多个查询词,并将所述查询词分别输入翻译模型进行处理,对应输出预测的多个相关词;从预测的多个相关词中,选取第一部分相关词作为正样本,以及,选取第二部分相关词,作为负样本;利用各查询词与其对应的正样本或负样本,组成查询词对,作为第二训练数据。
9、可选地,在根据本技术的方法中,利用第二训练数据对判别模型进行训练,得到新的判别模型,包括:将所述第二训练数据中的各查询词对分别输入判别模型进行处理,以输出对应的相关值;至少基于所述相关值对判别模型进行训练,直到满足训练条件时训练结束,得到新的判别模型。
10、可选地,在根据本技术的方法中,相关词样本包括相关词和不相关词。
11、根据本技术的再一方面,提供了一种信息搜索装置,包括:预处理单元,适于基于用户查询,确定出至少一个查询词;相关词预测单元,适于利用相关词预测模型,分别预测所确定的各查询词的至少一个相关词;检索单元,适于基于所预测的相关词进行搜索,确定搜索结果;模型训练单元,适于至少通过判别模型的输出数据,得到训练翻译模型的第一训练数据,至少通过所述翻译模型的输出数据,得到训练所述判别模型的第二训练数据,并利用所述第一训练数据和所述第二训练数据协同训练生成翻译模型和判别模型;所述模型训练单元还适于通过对所述翻译模型进行模型压缩得到所述相关词预测模型。
12、可选地,在根据本技术的装置中,翻译模型适于对输入的查询词进行处理,来预测所述查询词对应的多个相关词;所述判别模型基于预训练语言模型,适于对输入的两个查询词进行处理,以输出指示所述两个查询词间相关性的相关值,其中,若所述相关值大于预设值,则确定两个查询词相关;若所述相关值不大于预设值,则确定两个查询词不相关。
13、根据本技术的再一方面,提供了一种计算设备,包括:一个或多个处理器存储器;一个或多个程序,其中所述一个或多个程序存储在存储器中并被配置为由一个或多个处理器执行,一个或多个程序包括用于执行如上任一方法的指令。
14、根据本技术的再一方面,提供了一种存储一个或多个程序的计算机可读存储介质,一个或多个程序包括指令,指令在被计算设备执行时,使得计算设备执行如上所述的任一方法。
15、根据本技术的再一方面,提供了一种计算机程序产品,包括计算机程序/指令,其中,该计算机程序/指令被处理器执行时实现上述所述方法的步骤。
16、综上所述,根据本技术的方案,使用用户共点击与同搜索交互下的改写词,在垂直网站领域进行训练语料的自动挖掘,来生成查询词对;之后在此基础上,利用判别模型和翻译模型的协同处理,并融入人工标注的部分训练数据,通过循环迭代的过程,过滤掉挖掘到的查询词对中的噪声数据,同时又优化了翻译模型和判别模型,能够很好地解决语义漂移问题,提升了预测相关词的准确性。
17、此外,采用模型压缩的方式对翻译模型进行处理,得到的相关词预测模型能够更好地用于在线实时预测,在尽量提升准确率的前提下,再次优化了模型结构。
18、此外,从垂直领域网站的搜索点击日志中挖掘生成查询词对,也就是说,整个处理过程均围绕特定领域的专业语料展开,能够更好地适用该垂直领域网站的信息搜索。
19、上述说明仅是本技术技术方案的概述,为了能够更清楚了解本技术的技术手段,而可依照说明书的内容予以实施,并且为了让本技术的上述和其它目的、特征和优点能够更明显易懂,以下特举本技术的具体实施方式。
- 还没有人留言评论。精彩留言会获得点赞!