人脸视频的编辑方法、系统及电子设备与流程
本公开涉及计算机,尤其涉及一种人脸视频的编辑方法、系统及电子设备。
背景技术:
1、音频驱动的说话人脸生成技术是数字人领域的热门话题。其目标是合成唇形与给定音频同步的目标人物视频。
2、在现有技术中,主要有两类方法。一类方法旨在构建一个通用模型,该模型无需重新训练即可泛化到不包含在训练数据中的人物视频。然而,生成的人脸图像往往比较模糊,需要借助人脸增强后处理来提升清晰度。另一类方法则旨在构建个性化模型,仅适用于特定人物在特定环境下拍摄的视频。这类方法能生成照片级别的结果,但无法很好地泛化到其他人的视频上。
3、因此需要解决,如何提高人脸音频同步视频的生成效果及其生成模型的适配性的问题。
技术实现思路
1、有鉴于此,本公开的目的在于提出一种人脸视频的编辑方法、系统及电子设备,解决了提高人脸音频同步视频的生成效果及其生成模型的适配性的问题。
2、为了实现上述公开目的之一,本公开提供了一种人脸视频的编辑方法,所述方法包括:
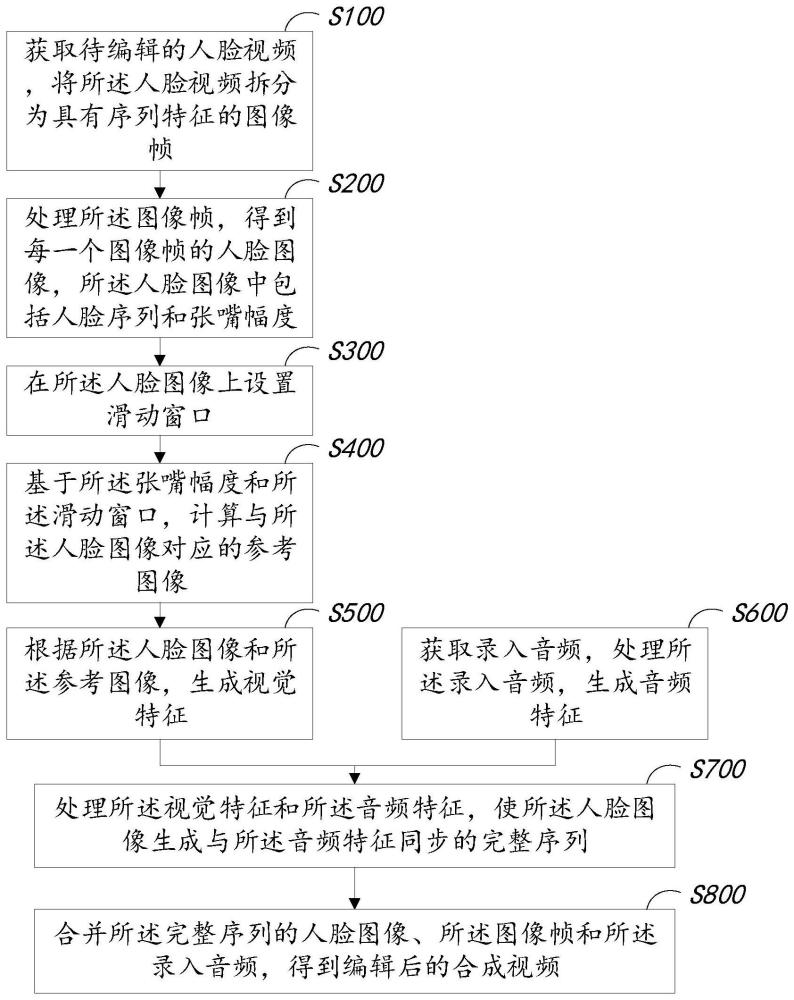
3、获取待编辑的人脸视频,将所述人脸视频拆分为具有序列特征的图像帧;
4、处理所述图像帧,得到每一个图像帧的人脸图像,所述人脸图像中包括人脸序列和张嘴幅度;
5、在所述人脸图像上设置滑动窗口;
6、基于所述张嘴幅度和所述滑动窗口,计算与所述人脸图像对应的参考图像;
7、根据所述人脸图像和所述参考图像,生成视觉特征;
8、获取录入音频,处理所述录入音频,生成音频特征;
9、处理所述视觉特征和所述音频特征,使所述人脸图像生成与所述音频特征同步的完整序列;
10、合并所述完整序列的人脸图像、所述图像帧和所述录入音频,得到编辑后的合成视频。
11、作为本公开一实施方式的进一步改进,,所述在所述人脸图像上设置滑动窗口,包括:
12、遮盖所述人脸图像的下半部分,得到遮盖图像;
13、在所述人脸图像上设置滑动窗口;
14、所述计算与所述人脸图像对应的参考图像,包括:
15、计算与所述遮盖图像对应的参考图像;
16、所述根据所述人脸图像和所述参考图像,生成视觉特征,包括:
17、根据所述遮盖图像和所述参考图像,生成视觉特征。
18、作为本公开一实施方式的进一步改进,所述处理所述图像帧,得到每一个图像帧的人脸图像,包括:
19、检测所述图像帧中的人脸,得到人脸框的坐标及面部关键点的坐标;
20、基于人脸框的坐标,裁剪所述图像帧,得到所述图像帧的所述人脸图像。
21、作为本公开一实施方式的进一步改进,所述得到每一个图像帧的人脸图像,所述人脸图像中包括人脸序列和张嘴幅度,包括:
22、对应所述图像帧的序列和所述人脸图像,得到所述人脸序列;
23、获取所述面部关键点的坐标和所述人脸框的坐标,所述面部关键点包括右眼坐标和左眼坐标;
24、其中,人脸框坐标为右眼坐标为左眼坐标为
25、计算所述张嘴幅度,其公式为:
26、
27、其中,所述张嘴幅度为di;所述人脸框坐标为所述右眼坐标为所述左眼坐标为
28、作为本公开一实施方式的进一步改进,所述在所述人脸图像上设置滑动窗口,包括:
29、选取与所述遮盖图像对应的人脸图像,以所述人脸图像为中心设置大小为l的所述滑动窗口;
30、基于所述张嘴幅度和所述滑动窗口,计算与所述遮盖图像对应的参考图像,包括:
31、计算所述参考图像的公式为:
32、
33、其中,所述人脸图像为fi;所述参考图像表示为在所述滑动窗口中的人脸图像序列为:fi-l/2,...,fi,...,fi+l/2-1;所述参考图像的张嘴幅度为dk。
34、作为本公开一实施方式的进一步改进,处理所述视觉特征和所述音频特征,使所述人脸图像生成与所述音频特征同步的完整序列,包括:
35、拼接所述视觉特征和所述音频特征,并输入至图像解码器中;
36、生成与所述音频特征同步的第i帧唇形及其对应的人脸图像;
37、根据所述音频特征的顺序排列唇形及其人脸图像的顺序;
38、生成所述完整序列。
39、作为本公开一实施方式的进一步改进,所述合并所述完整序列的人脸图像、所述图像帧和所述录入音频,得到编辑后的合成视频,包括:
40、所述完整序列的人脸图像替换所述图像帧中人脸框对应的区域,生成编辑后的图像序列;
41、利用视频编辑器,将编辑后的图像序列合成视频流;
42、在所述视频流中输入所述录入音频,得到编辑后的合成视频。
43、作为本公开一实施方式的进一步改进,所述根据所述遮盖图像和所述参考图像,生成视觉特征,包括:
44、将所述遮盖图像和所述参考图像按第三个维度拼接,得到三维数组;
45、将所述三维数组输入至图像编码器中,得到所述视觉特征;
46、所述处理所述录入音频,生成音频特征,包括:
47、将所述录入音频转化成频谱,并切分为具有序列特征的区块;
48、将额定长度的区块按照序列输入至音频编码器中,生成音频特征。
49、基于相同的发明构思,本公开还提供了一种人脸视频的编辑系统,包括:
50、第一获取模块,用于获取待编辑的人脸视频,用于将所述人脸视频拆分为具有序列特征的图像帧;
51、第一处理模块,用于处理所述图像帧,得到每一个图像帧的人脸图像,所述人脸图像中包括人脸序列和张嘴幅度;
52、第一设置模块,用于在所述人脸图像上设置滑动窗口;
53、第一计算模块,用于基于所述张嘴幅度和所述滑动窗口,计算与所述人脸图像对应的参考图像;
54、第一生成模块,用于根据所述人脸图像和所述参考图像,生成视觉特征;
55、第二获取模块,用于获取录入音频,处理所述录入音频,生成音频特征;
56、第二处理模块,用于处理所述视觉特征和所述音频特征,使所述人脸图像生成与所述音频特征同步的完整序列;
57、第一合成模块,用于合并所述完整序列的人脸图像、所述图像帧和所述录入音频,得到编辑后的合成视频。
58、基于同样的发明构思,本公开还提供了一种电子设备,包括:处理器和存储器;
59、所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行上述任一所述人脸视频的编辑方法的步骤。
60、相对于现有技术,本发明的技术效果在于:本公开通过将视频拆分为图像序列,单独的处理每一帧的内容,通过设置滑动窗口,在滑动窗口中选取参考图像,在一定程度上保证了人脸图像中人脸信息的完整性,从而提升了通用模型驱动说话人物视频的生成效果,本方法可以处理任一人脸视频,具有优良的泛化性。
- 还没有人留言评论。精彩留言会获得点赞!