一种基于自蒸馏的用于资源受限情况下文档级关系抽取的方法及系统
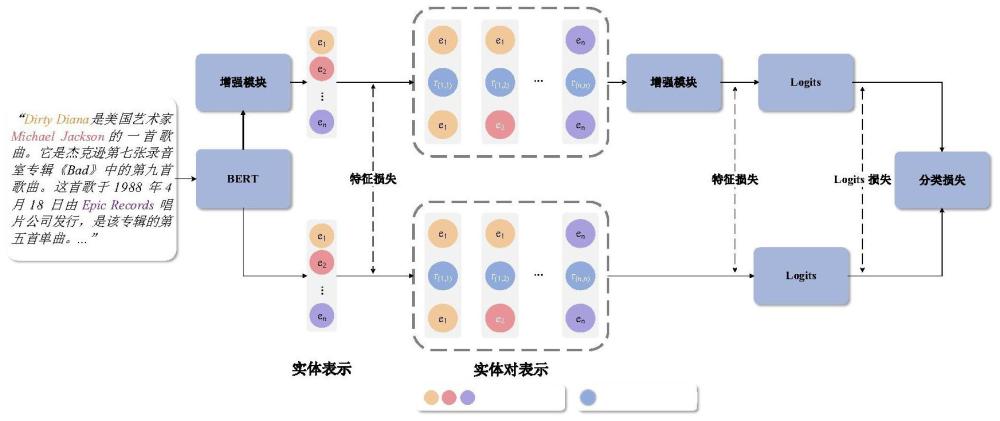
本发明涉及自然语言处理,尤其涉及一种基于自蒸馏的用于资源受限情况下文档级关系抽取的方法及系统,通过自蒸馏框架,在缩小模型规模的同时获取高质量的实体嵌入与实体对嵌入,并以此为基础进行文档级的关系抽取。
背景技术:
1、关系提取(relation extraction,re)旨在识别给定文本中两个实体之间的关系,在许多的信息提取任务中处于至关重要的位置。举例而言,在现当下围绕着大语言模型(large language model,llm)展开的各种研究中,研究人员使用大量的数据对模型进行训练。然而这样的训练会将自由文本中的歧视思想、错误信息甚至是一些危险设想一并传入大语言模型,导致大语言模型存在着一些常识性错误甚至是幻觉问题。2023年6月以来,微软发布了“phi”系列模型的三个版本,其中“phi-2”模型参数只有27亿,却可以在所有参数规模小于130亿的模型中拥有最为先进的性能。究其原因,是因为微软意识到数据的质量对模型性能的绝度影响,因此构建包含多领域常识的“教科书式”的数据用来训练,这也是“phi”系列模型能力出众的原因。同样的想法也由吴恩达等人提出过,他们认为现阶段的深度学习应该由“以模型为中心”转向“以数据为中心”,在模型发展相对停滞阶段应该更多地关注训练数据的质量。在高质量的训练数据集构造过程中,关系提取的相关方法被用于捕获文本中两个实体之间的关系,对数据集的质量好坏起到决定作用。
2、目前,关系提取的主要目标是通过句子级分析来预测单句中实体之间的关系。然而,以往的研究大多集中在寻找单句之间的联系,而忽略了检测多个句子之间的联系。在现实生活中,许多合作关系经常在多个句子中陈述。根据之前的研究,超过40.7%的关联是在多个句子中单独识别出来的。因此,必须在文档层面上通过模型提取关系。基于transformer的预训练模型能够通过底层注意力机制捕捉众多句子中不同实体之间的关系信息,因此最近在文档级关系提取领域引起了极大的关注。然而,与句子级关系提取相比,文档级关系提取的实现更具挑战性。特别是,仅从一个句子中无法推断出关联的主语和宾语,因为它们可能存在于不同的句子中。其次,模型需要能够跨句子表示实体,因为同一实体可能在文本中的多个地方出现。最后,为了便于推理,某些实体对之间的联系经常是通过使用其他实体来发现的。要确定这些多跳关系,就必须对各种实体之间的互动进行逻辑推理。
3、综上,在现当下的关系抽取研究中,大部分方法都针对着句子级的关系抽取展开,即仅仅对单句话中的实体对展开分析,依据少量的上下文信息对其关系进行抽取。而在常见的中英文文本中,一个关系所对应的主语实体和宾语实体可能位于不同的句子中,这就要求关系抽取模型能够拥有联合多句甚至多段文本进行关系抽取的能力。目前的几种文档级关系抽取方法通过简单地在已有模型上叠加表示增强模块来提高模型性能。虽然加速性能有了一定的提高,但由于这些新模块会增加资源消耗,因此这些模型并不适合在资源匮乏的情况下部署。
技术实现思路
1、本发明针对上述问题,提出一种基于自蒸馏的用于资源受限情况下文档级关系抽取的方法及系统,创建了一个自蒸馏框架,它可以提高文档级关系抽取模型的性能,同时只需要一次训练,不需要增加额外的参数,从而可以在资源匮乏的情况下部署。
2、为了实现上述目的,本发明采用以下技术方案:
3、本发明一方面提出一种基于自蒸馏的用于资源受限情况下文档级关系抽取的方法,本发明中文档级关系抽取任务可以形式化的定义为:一个文档中包含了一组实体关系抽取的任务是识别集合中实体对(es,eo)之间的关系,其中代表预先定义的关系集,es和eo分别指主语实体和宾语实体。在一篇文档之中,任何实体ei都可能以提及的形式出现多次,表示与实体ei相关的提及数目。其中提及指的是同一实体在不同上下文中可能出现的多样化表示。若存在一段表示包含了两个实体的提及,则视为这两个实体(es,eo)之间存在关系。标签na用于标记两个实体之间没有任何的特殊关系。在测试过程中,框架会对文档中所有实体对(es,eo)s,o=1...n;s≠o的关系标签进行预测。
4、该方法包括:
5、步骤1:使用符号“*”对文档中的所有实体提及进行标注;
6、步骤2:使用预先训练好的bert模型作为编码器,对文档进行编码;
7、步骤3:联合第一骨干模型和第一教师模型构建实体表示增强模块,通过实体表示增强模块,根据步骤1中的标注和步骤2中编码后的文档,获取实体嵌入;
8、步骤4:联合第二骨干模型和第二教师模型构建实体对表示增强模块,通过实体对表示增强模块,根据步骤3得到的实体嵌入获取实体对嵌入;
9、步骤5:依据自适应阈值损失函数对模型进行训练和优化,得到训练好的文档级关系抽取模型;
10、步骤6:基于文档级关系抽取模型对文档级关系进行抽取。
11、进一步地,所述步骤1中,将符号“*”放在每个实体提及处的开头和结尾处,以此来定位每一个实体提及。
12、进一步地,所述步骤2中,使用预先训练好的bert模型作为编码器,对文档进行一次编码;对于超过512个词组的文档,采用动态窗口法对整个文档进行编码,随后计算不同窗口中重叠嵌入的平均值,得到最终的单词嵌入。
13、进一步地,所述第一骨干模型利用实体提及开始和结束时的"*"嵌入来表示与提及嵌入相关的实体,采用log-sum-exp池化方法得到所有与实体相关的提及的实体嵌入。
14、进一步地,所述第一教师模型中,使用rsman对实体表示进行增强。
15、进一步地,所述第二骨干模型中,利用线性和非线性激活层将实体嵌入映射到隐藏状态z,将嵌入维度分为k个等大的组,在每个组内应用双线性函数和sigmoid激活函数,并通过以下公式对关系r的概率进行计算:
16、
17、
18、
19、
20、
21、
22、其中表示可学习的权值矩阵,tanh()表示双线性函数,es和eo分别指主语实体和宾语实体,zs和zo分别表示es和eo对应的隐藏状态,表示可学习参数,br表示神经网络中的偏置单元,g(s,o)表示了关系r适配于实体对(es,eo)的概率。
23、进一步地,所述第二教师模型中,在将特定关系对应的实体表示按关系类型的顺序排列后,使用线性层和激活函数将排序后的实体映射到隐藏状态,从而分别获得主语实体和宾语实体的表示。
24、进一步地,所述第二教师模型中,采用轴向注意力机制增强每一个实体对(es,eo)在轴向上的邻域信息,利用轴向注意力来捕获以邻接矩阵表示的两跳内的信息,所述轴向注意力通过沿水平轴和垂直轴的外部注意力来计算。
25、进一步地,所述自适应阈值损失函数为:
26、
27、
28、其中,th表示自适应阈值类,r表示实际关系,pt、nt分别表示正例、负例,正例表示超过自适应阈值的关系,负例表示低于自适应阈值的关系,l1中r′表示正例和自定义的阈值关系,exp()为指数函数,logit为logit模型,用来作为网络结构中的分类层,l2中r′表示负例和自定义的阈值关系;通过自适应阈值损失函数得到第一教师模型/第二教师模型的损失lteacher,以及第一骨干模型/第二骨干模型的损失lbackbone;
29、模型整体损失函数为:
30、l(s,o)=lteacher+αlbackbone+(1-α)llogits+βlfeature,
31、其中,α和β表示超参数,llogits为第一骨干模型/第二骨干模型和第一教师模型/第二教师模型的最终对数之间的均方损失,lfeature表示根据第一骨干模型/第二骨干模型和第一教师模型/第二教师模型的实体特征和实体对特征计算出的余弦相似度。
32、本发明还提出一种基于自蒸馏的用于资源受限情况下文档级关系抽取的系统,包括:
33、数据预处理单元,用于使用符号“*”对文档中的所有实体提及进行标注;
34、文本表示单元,用于使用预先训练好的bert模型作为编码器,对文档进行编码;
35、实体嵌入获取单元,用于联合第一骨干模型和第一教师模型构建实体表示增强模块,通过实体表示增强模块,根据数据预处理单元中的标注和文本表示单元中编码后的文档,获取实体嵌入;
36、实体对嵌入获取单元,用于联合第二骨干模型和第二教师模型构建实体对表示增强模块,通过实体对表示增强模块,根据实体嵌入获取单元得到的实体嵌入获取实体对嵌入;
37、自适应训练单元,用于依据自适应阈值损失函数对模型进行训练和优化,得到训练好的文档级关系抽取模型;
38、文档级关系抽取单元,用于基于文档级关系抽取模型对文档级关系进行抽取。
39、与现有技术相比,本发明具有的有益效果:
40、本发明通过使用符号“*”对文档中的所有实体提及进行标注,从特征工程出发将数据转换为更好的表示潜在问题的特征,以此为bert模型提供更加鲜明的特征,使其在不改动自身模型结构的前提下获得更好的性能。
41、本发明将自蒸馏概念应用于目前正在进行的文档级关系提取工作,在不引入任何额外参数的情况下有效提高骨干模型在预测阶段的性能。与其他自蒸馏技术不同,本发明根据文档级关系提取任务的特点,构建实体表示增强模块和实体对表示增强模块,然后,上述模块同时独立地进行自我蒸馏。
42、本发明所提的综合损失函数包括教师模型与骨干模型的实体和实体对表示之间的对比损失,以及教师模型与分类层的实体对嵌入之间的对比损失。同时训练教师模型和骨干模型能使前者在一次训练中几乎达到后者的性能水平。
43、本发明可以同时训练骨干模型和教师模型,通过自蒸馏思想的引入,使得在不增加骨干模型规模的情况下成功地学习了教师模型的知识,可适用于在资源匮乏的情况下部署。
- 还没有人留言评论。精彩留言会获得点赞!