一种基于文档结构的素材推荐方法及装置
本发明涉及电子信息处理,尤其涉及一种基于文档结构的素材推荐方法及装置。
背景技术:
1、撰写各类文档时往往需要查找多种素材,素材是指文档、图片、视频、音频或其他类型的信息资源。特别是在公文报告领域,存在研究报告撰写过程中资料积累效率低的技术问题。因此,素材推荐技术得到广泛使用,素材推荐是指在信息检索领域中,根据用户的需求,从一个素材库中找到与需求相匹配或相关的素材。素材推荐通常涉及使用关键词、查询语句或其他信息表示形式来寻找最相关的内容。
2、素材推荐技术的现有技术如下。
3、1、文档检索
4、稀疏检索器是最传统的检索器。tf-idf和bm25基于问题与段落的词汇匹配程度检索候选段落,但其表示能力有限,无法捕获相关语义信息,检索精度不理想。许多研究人员尝试使用深度学习来改进传统的检索方法,dai等提出了deepct,将文本理解能力与搜索知识相结合,获得增强的bert模型。nogueira等人提出了doc2query和doctttttquery,它们分别使用sequence-to-sequence和t5模型来扩展可能针对给定文档发出的查询。mao等人提出了一种名为gar的模型,该模型通过生成启发式地发现相关上下文的文本来增强查询。然而,它们在处理长文本时面临信息丢失和计算复杂度高等问题,使得难以对长文档执行准确的检索。
5、与上述基于术语的方法不同,karpukhin等是第一个引入段落级对比学习框架(dpr)来训练密集段落表示的研究。在那之后,许多研究试图提高密集检索器的性能。lee等人提出了一种逆完形任务(ict)来预训练密集检索模型。zhou等提出了一种基于超链接拓扑结构(hlp)的预训练任务。由于建模粒度不当,dpr无法捕获内部表示冲突的段落,wu等引入了句子级对比学习框架(dcsr)来训练密集的段落表示。
6、尽管双编码器体系结构取得了令人印象深刻的结果,但使用这种体系结构很难有效地训练检索器。许多研究者致力于解决这一问题,huang等使用随机否定来近似回忆任务。qu等发现在小批量中增加随机负样本的数量是有益的。zhou等采用批内负采样,将同一批中其他问题的相关段落作为负样本训练密集检索器。zhan等研究发现,与随机负采样相比,硬负采样能更好地优化性能。因此,许多研究者将注意力集中在复杂样本采样上。gao等和karpukhin等采用bm25顶级文档作为复杂样本,karpukhin发现一个复杂样本比多个复杂样本好。xiong等和guu等使用预热dr模型在训练过程中预检索顶级段落作为复杂样本,它们还会定期重新构建索引并刷新复杂样本,这大大增加了计算成本。qu等人使用昂贵的交叉编码器从顶部检索中去除潜在的假阴性段落,并使用跨批复杂样本在多个gpu上训练双编码器模型,这需要一定程度的硬件支持。此外,也有许多研究通过从交叉编码器中提取知识和预训练语言模型来提高模型的性能。但是上述工作采用了昂贵的硬件设备,并且在全局中搜索复杂样本效率低下。
7、2、文档排序
8、文档排序多样性是信息检索领域中一个重要的研究方向,为了提供更加丰富、多样性和符合用户需求的搜索结果,许多工作致力于改进文档排序多样性。
9、yue和joachims首先进行了一些前期的探索。他们提出了svm-div模型,将机器学习的任务形式化为通过预测多样化子集来建立多样化排序,并引入了结构化的支持向量机模型(structural svm)。相对于之前基于mmr模型的启发式方法,此方法只专注于对多样性的捕捉,没有引入相关性考量。为了解决这个问题,jiang等提出了一中新的显示监督式学习框架。一方面这种模型显式地衡量子话题,可以通过优化提高用户意图的覆盖程度,另一方面可以自动地学习文档的多样化函数,并且可以捕获文档和子话题之间的复杂交互。
10、传统的相似性度量通常只关注文档之间的相似性或相关性,而无法捕捉文档之间的多样性特征。xie等引入多相似性学习,尝试解决信息检索中的文档多样性问题。通过学习多个相似性度量,以更全面的方式表示文档之间的相关性,实验结果表明提高了检索结果的多样性。
11、随着强化学习的广泛应用,许多工作试图以此提高文档排序多样性的表现。强化学习是一种用于决策的重要的机器学习方法,其过程可以简要叙述如下:每经过一个时间步,由代理对环境进行观察,做出决策动作,然后从环境获得回报作为下一步决策的依据。而搜索引擎对结果文档的排序过程,无论相关性排序还是多样性排序,都可以视作一个决策过程,即文档序列的连续选择过程。xia等提出了一个新的模型mdp-div,将马尔可夫决策过程引入搜索结果多样化过程,把结果文档的多样化排序过程视作一个连续的mdp,进而将多样化排序问题形式化为一个学习mdp模型的问题。
12、以前文档排序和文档检索的相关工作没有考虑到素材之间的专题多样性与相似性问题。对于专题多样性来说,一个素材回答的问题不是单个方面的,许多问题答案的素材可能是同一个,而使用一个统一的特征向量来表示会丢失素材的信息多样性,所以在素材检索返回的素材通常是一个专题的。对于专题的相似性来说,在训练编码器时需要质量高的负样本,而专题相似的素材具有相似的语义信息,它们是天然的复杂样本,本发明通过文档结构获得了素材的专题信息。考虑到这两方面的信息,本发明提出了一种基于文档结构增强的素材多样性推荐构建方法。总的来说,本发明利用文档结构获得了素材之间的专题关系,挖掘了质量更高的负样本,并提出了一个多视图素材表示学习方法,旨在生成多视图的素材向量表示训练编码器,提高素材搜索的多样性。
13、现有模型和发明在公文报告领域素材推荐召回素材的专题多样性差,并且使用质量参差不齐的样本训练模型。对于专题多样性,传统发明的推荐结果不能满足大模型写作生成公文报告的需求。在军民融合的语境下,传统发明可能只关注政治、经济、科技、教育或人才等的几个方面,不能返回给用户相关的全面信息。此外,这些发明通常返回整个文档作为推荐素材,而无法提供更细粒度的信息,如句子、段落或章节,这限制了用户对特定信息的获取和理解。
14、本发明的动机和机器学习的模型的制定都不同于现有技术。现有技术没有考虑素材推荐的多样性,本发明充分考虑素材的专题信息,将信息丰富的素材输入到模型中进行训练,使模型能够推荐多样化的素材。
技术实现思路
1、为解决上述技术问题,本发明提出了一种基于文档结构的素材推荐方法及装置,用以解决现有的技术问题。
2、本发明提出了一种基于文档结构的素材推荐方法,所述方法包括:
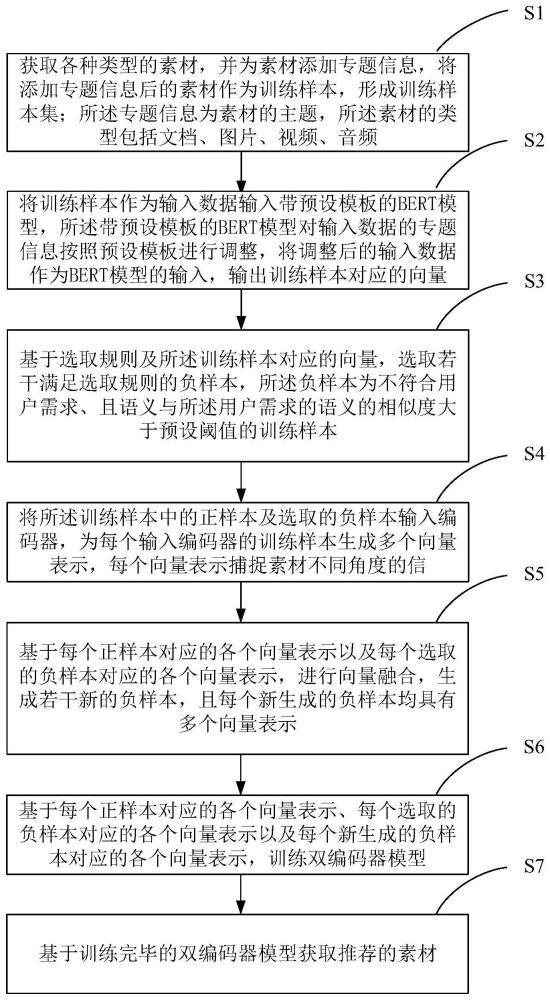
3、步骤s1:获取各种类型的素材,并为素材添加专题信息,将添加专题信息后的素材作为训练样本,形成训练样本集;所述专题信息为素材的主题,所述素材的类型包括文档、图片、视频、音频;
4、步骤s2:将训练样本作为输入数据输入带预设模板的bert模型,所述带预设模板的bert模型对输入数据的专题信息按照预设模板进行调整,将调整后的输入数据作为bert模型的输入,输出所述训练样本对应的向量;
5、步骤s3:基于选取规则及所述训练样本对应的向量,选取若干满足选取规则的负样本,所述负样本为不符合用户需求、且语义与所述用户需求的语义的相似度大于预设阈值的训练样本;
6、步骤s4:将所述训练样本中的正样本及选取的负样本输入编码器,为每个输入编码器的训练样本生成多个向量表示,每个向量表示捕捉素材不同角度的信息;
7、步骤s5:基于每个正样本对应的各个向量表示以及每个选取的负样本对应的各个向量表示,进行向量融合,生成若干新的负样本,且每个新生成的负样本均具有多个向量表示;
8、步骤s6:基于每个正样本对应的各个向量表示、每个选取的负样本对应的各个向量表示以及每个新生成的负样本对应的各个向量表示,训练双编码器模型;
9、步骤s7:基于训练完毕的双编码器模型获取推荐的素材。
10、优选地,所述双编码器模型包括两个彼此独立的编码器,一个作为查询编码器,一个作为素材编码器,所述查询编码器及所述素材编码器在训练过程中均用于接收正样本对应的各个向量表示、选取的负样本对应的各个向量表示以及新生成的负样本对应的各个向量表示;在训练完毕后,所述查询编码器用于接收用户输入的查询语句,将所述查询语句转化为查询语句对应的编码;所述素材编码器用于接收用户输入的查询语句,输出与所述查询语句对应的素材的向量表示。
11、优选地,所述步骤s7,包括:
12、步骤s71:接收用户输入的查询语句,将所述查询语句输入所述训练完毕的双编码器模型,得到查询语句对应的素材的编码,所述编码为向量形式,即得到查询语句对应的素材的向量表示;基于所述查询语句对应的素材的编码查询素材库,所述素材库为预先建立了索引的素材库;
13、步骤s72:所述素材库为将所述查询语句对应的素材的编码与所述素材库的索引进行相似性比对,将相似度排在前10位的素材提供给用户。
14、优选地,所述素材的索引通过词嵌入的方式进行编码。
15、优选地,所述步骤s5:所述生成若干新的负样本,包括:
16、基于每个正样本对应的各个向量表示以及每个选取的负样本对应的各个向量表示,以p,h分别表示正负样本的一个向量为例,p和h通过点积操作来确定正样本p和负样本h之间相似度最低的部分,所述相似度最低的部分记为[i1:i2],其中i1和i2分别是所述相似度最低的部分的开始和结束的水平坐标;
17、所述新的负样本坐标为0至坐标为i1的部分h′[0:i1]为:
18、h′[0:i1]=(1-λ)p[0:i1]+λh[0:i1]
19、其中,λ∈[0,1],λ为权重参数,p[0:i1]为正样本坐标为0至坐标为i1的向量表示,h[0:i1]为负样本坐标为0至坐标为i1的向量表示;
20、所述新的负样本坐标为i1+1至坐标为i2的部分h′[i1+1:i2]为:
21、h′[i1+1:i2]=λp[i1+1:i2]+(1-λ)h[i1+1:i2]
22、其中,p[i1+1:i2]为正样本坐标为i1+1至坐标为i2的向量表示,h[i1+1:i2]为负样本坐标为i1+1至坐标为i2的向量表示;
23、所述新的负样本坐标为i2+1至坐标为m的部分h′[i2+1:m]为:
24、h′[i2+1:h]=λp[i2+1:n]+(1-λ)h[i2+1:m]
25、其中,p[i2+1:n]为正样本坐标为i2+1至坐标为m的向量表示,h[i1+1:i2]为负样本坐标为i2+1至坐标为m的向量表示;
26、形成的新的负样本h′为:
27、h′=cat(h′[0:i1],h′[i1:i2],h′[i2:m])
28、cat为连接函数。
29、本发明提供一种基于文档结构的素材推荐装置,所述装置包括:
30、数据获取模块:配置为获取各种类型的素材,并为素材添加专题信息,将添加专题信息后的素材作为训练样本,形成训练样本集;所述专题信息为素材的主题,所述素材的类型包括文档、图片、视频、音频;
31、第一转换模块:配置为将训练样本作为输入数据输入带预设模板的bert模型,所述带预设模板的bert模型对输入数据的专题信息按照预设模板进行调整,将调整后的输入数据作为bert模型的输入,输出所述训练样本对应的向量;
32、第一选取模块:配置为基于选取规则及所述训练样本对应的向量,选取若干满足选取规则的负样本,所述负样本为不符合用户需求、且语义与所述用户需求的语义的相似度大于预设阈值的训练样本;
33、第二转换模块:配置为将所述训练样本中的正样本及选取的负样本输入编码器,为每个输入编码器的训练样本生成多个向量表示,每个向量表示捕捉素材不同角度的信息;
34、融合模块:配置为基于每个正样本对应的各个向量表示以及每个选取的负样本对应的各个向量表示,进行向量融合,生成若干新的负样本,且每个新生成的负样本均具有多个向量表示;
35、训练模块:配置为基于每个正样本对应的各个向量表示、每个选取的负样本对应的各个向量表示以及每个新生成的负样本对应的各个向量表示,训练双编码器模型;
36、素材获取模块:配置为基于训练完毕的双编码器模型获取推荐的素材。
37、本发明提供一种电子设备,所述设备包括:
38、至少一个处理器;以及
39、与所述至少一个处理器通信连接的存储器;其中,
40、所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行如前所述的方法。
41、本发明提供一种存储有计算机指令的非瞬时计算机可读存储介质,所述计算机指令用于使所述计算机执行如前所述的方法。
42、生成式大模型语言为自动写作公文报告提供了技术可行性。为了让生成式大模型文本生成输出质量更高,需要输入给大模型写作专题更相关,更多样化的素材,也为了准确高效的推荐素材,本发明通过挖掘文档结构信息,构造适合素材推荐场景的正负样本训练编码器。针对大模型写作专题需要更相关,更多样化的素材,最关键的问题就是训练的正负样本构造以及素材的多视图向量表示。具体来说本发明考虑了素材的专题多样性和相似性,利用素材的文档结构挖掘了信息丰富的训练样本。考虑到返回素材结果的多样性,本发明使用一个编码器生成多视图向量表示素材不同方面的信息。
43、本发明利用以预训练语言模型bert为骨架的双编码器模型,通过挖掘文档结构的专题信息构造适合素材推荐的数据集,训练了检索高效、返回结果专题多样性的素材推荐模型。素材推荐模型利用双编码器对用户提出的问题进行编码,然后从大规模素材库中查找与用户问题相关的多样性素材,经过素材排序之后作为资料返回给用户,以此来协助大模型生成公文报告。
44、应当理解,
技术实现要素:
部分中所描述的内容并非旨在限定本公开的实施例的关键或重要特征,亦非用于限制本公开的范围。本公开的其它特征将通过以下的描述变得容易理解。
- 还没有人留言评论。精彩留言会获得点赞!