视听场景下的听觉注意解码方法、装置和助听系统
本技术涉及数据处理领域,特别是涉及一种视听场景下的听觉注意解码方法、装置和助听系统。
背景技术:
1、对于多声源场景,听觉正常人士具有针对性地选择关注目标声音,提高信息感知效率的能力。听觉障碍人士在多声源场景中缺乏这种能力,由于听力损失,难以过滤背景杂音,影响对目标声音的准确感知。尽管如此,先进技术和辅助设备的不断进步,如助听器和听觉辅助技术,为改善听障人士的听觉体验提供了新的可能性。
2、为解决上述问题,听觉注意解码算法应运而生,听觉注意解码算法主要是便于助听设备锁定佩戴者关注的目标声源的空间方位,从而确定目标声源发出的目标声音。通过将听觉注意解码算法应用于助听器等设备中,有望智能地调整目标声音的放大,降低其余声音的影响,从而提高听障人士的目标感知能力。但是目前的听觉注意解码算法对目标声源的定位准确性较低,进而难以准确地锁定目标声音,从而对听障人士的目标感知能力提升有限。
3、针对目前的听觉注意解码算法对目标声源的定位准确性较低的问题,目前还没有提出有效的解决方案。
技术实现思路
1、在本发明中提供了视听场景下的听觉注意解码方法、装置和助听系统,以解决目前的听觉注意解码算法对目标声源的定位准确性较低的问题。
2、第一个方面,在本发明中提供了一种视听场景下的听觉注意解码方法,包括:
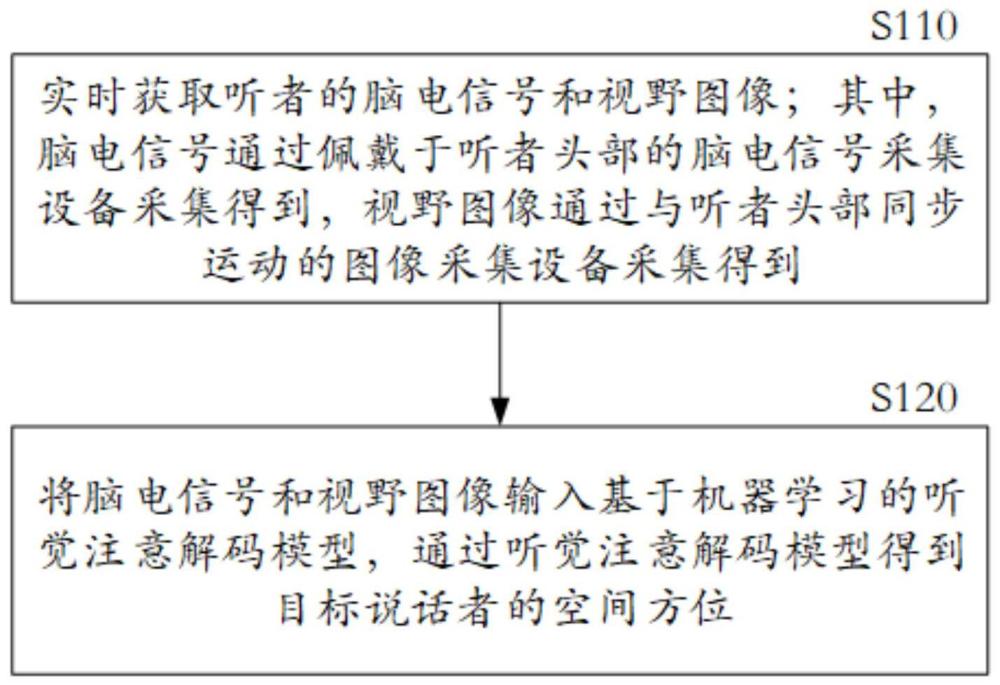
3、实时获取听者的脑电信号和视野图像;其中,所述脑电信号通过佩戴于听者头部的脑电信号采集设备采集得到,所述视野图像通过与听者头部同步运动的图像采集设备采集得到;
4、将所述脑电信号和所述视野图像输入基于机器学习的听觉注意解码模型,通过所述听觉注意解码模型得到目标说话者的空间方位,所述目标说话者为所述听者关注的说话者。
5、在其中的一些实施例中,所述听觉注意解码模型包括脑电模态流模块、视觉模态流模块、特征融合模块和带有激活函数的第一全连接层;
6、通过所述听觉注意解码模型得到目标说话者的空间方位,包括:
7、通过所述脑电模态流模块对所述脑电信号进行特征提取得到目标脑电特征;
8、通过所述视觉模态流模块对所述视野图像进行特征提取得到目标视觉特征;
9、通过特征融合模块对所述目标脑电特征和所述目标视觉特征进行融合得到多模态特征;
10、通过所述第一全连接层对所述多模态特征进行预测得到预测结果;
11、根据所述预测结果确定目标说话者的空间方位。
12、在其中的一些实施例中,根据所述预测结果确定目标说话者的空间方位,包括:
13、当所述目标说话者处于听者空间左侧的概率大于处于听者空间右侧的概率时,确定所述目标说话者处于听者空间左侧;
14、当所述目标说话者处于听者空间左侧的概率小于处于听者空间右侧的概率时,确定所述目标说话者处于听者空间右侧。
15、在其中的一些实施例中,所述脑电模态流模块包括卷积层、平均池化层、第一展平层和带有激活函数的第二全连接层;
16、通过所述脑电模态流模块对所述脑电信号进行特征提取得到目标脑电特征,包括:
17、依次通过所述卷积层和所述平均池化层对所述脑电信号进行处理得到中间脑电特征;
18、依次通过所述第一展平层和所述第二全连接层对所述中间脑电特征进行处理得到所述目标脑电特征。
19、在其中的一些实施例中,所述中间脑电特征的提取公式如下:
20、feeg=avgpool(conv(xeeg))
21、其中,xeeg表示脑电信号,feeg表示中间脑电特征,conv表示卷积操作,avgpool表示平均池化操作;
22、所述目标脑电特征的提取公式如下:
23、f′eeg=sigmoid(dense(flatten(feeg)))
24、其中,f′eeg表示目标脑电特征,flatten表示展平操作,dense表示全连接操作,sigmoid表示归一化激活操作。
25、在其中的一些实施例中,所述视觉模态流模块包括vgg16模型、第二展平层和带有激活函数的三个第三全连接层;
26、通过所述视觉模态流模块对所述视野图像进行特征提取得到目标视觉特征,包括:
27、通过预训练的所述vgg16模型对所述视野图像进行特征提取得到中间视觉特征;
28、依次通过所述第二展平层和三个所述第三全连接层对所述中间视觉特征进行处理得到所述目标视觉特征。
29、在其中的一些实施例中,所述中间视觉特征的提取公式如下:
30、fimg=vgg16(ximg)
31、其中,ximg表示视野图像,fimg表示中间视觉特征,vgg16表示vgg16模型的特征提取操作;
32、所述目标视觉特征的提取公式如下:
33、
34、
35、
36、其中,f′img表示目标视觉特征,flatten表示展平操作,dense表示全连接操作,relu表示线性整流操作,sigmoid表示归一化激活操作。
37、在其中的一些实施例中,所述多模态特征的融合公式如下:
38、f′=concat(f′eeg,f′img)
39、其中,f′表示多模态特征,f′img表示目标视觉特征,f′eeg表示目标脑电特征,concat表示连接操作;
40、所述预测结果的预测公式如下:
41、pi=softmax(dense(f′))
42、其中,pi表示预测结果,softmax表示软最大化激活操作,dense表示全连接操作。
43、第二个方面,在本发明中提供了一种视听场景下的听觉注意解码装置,包括:
44、数据获取模块,用于实时获取听者的脑电信号和视野图像;其中,所述脑电信号通过佩戴于听者头部的脑电信号采集设备采集得到,所述视野图像通过与听者头部同步运动的图像采集设备采集得到;
45、目标定位模块,用于将所述脑电信号和所述视野图像输入训练后的听觉注意解码模型,通过所述听觉注意解码模型得到目标说话者的空间方位,所述目标说话者为所述听者关注的说话者。
46、第三个方面,在本发明中提供了一种助听系统,包括:
47、脑电信号采集设备,可佩戴于听者脑部,用于采集听者的脑电信号;
48、图像采集设备,可与听者头部同步运动,用于采集听者的视野图像;
49、助听设备,可佩戴于听者耳部,其包括用于执行第一个方面所述的视听场景下的听觉注意解码方法的处理器。
50、第四个方面,在本发明中提供了一种存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述第一个方面所述的视听场景下的听觉注意解码方法。
51、与相关技术相比,在本发明中提供的视听场景下的听觉注意解码方法、装置和助听系统,充分考虑了实际场景中可用于定位目标说话者的信息,进而能够更加准确地锁定目标说话者的空间方位,改进了现有的听觉注意解码算法,可以更加充分地注意目标说话者的声音,解决了目前的听觉注意解码算法对目标声源的定位准确性较低的问题。
52、本技术的一个或多个实施例的细节在以下附图和描述中提出,以使本技术的其他特征、目的和优点更加简明易懂。
- 还没有人留言评论。精彩留言会获得点赞!