一种司机手势识别方法、装置、计算机设备和储存介质
本发明涉及深度学习,特别涉及一种司机手势识别方法、装置、计算机设备和储存介质。
背景技术:
1、司机手势识别可以用于交通信号的交互,例如司机通过手势表示停车、左转、右转等动作,系统能够识别并作出相应的交通信号,这有助于减少驾驶员在操作车辆时的分心,提高交通安全。司机手势识别是智能交通系统发展的一部分,可以促进车辆与交通基础设施之间的互联互通,通过手势交互,车辆可以与周围车辆、交通灯、道路设施等进行更智能的沟通。在目标识别任务中,模型需要大量的图片来进行训练,学习目标特征。样本要有足够的复杂性与多样性,才能使网络有很强的泛化能力。因此,数据集的数量和质量在目标检测任务中,有着重要的作用。在实际采集数据过程中通常很难覆盖全部的场景,并且数据获取需要大量成本。所以针对小样本数据集而言,数据增强是不可或缺的一部分。
2、现有技术中,有使用传统数据增强的方法来进行数据增强,也有使用生成对抗网络的方法进行数据增强。
3、但是传统数据增强的方法并未对原图中的信息进行打乱重组,导致增强后的数据仍旧含有大量的重复信息,在使用该增强数据进行训练时,模型学习到的仍旧是与原始数据场景。而采用深度卷积生成对抗网络生成的图片生成的图像的类型和样子不是非常可控的,会生成脱离出现于手势无关的图片。
技术实现思路
1、本发明提供一种司机手势识别方法、装置、计算机设备和储存介质,可以解决现有技术中,用于训练司机手势识别模型的数据集质量差的技术问题。
2、本发明提供一种司机手势识别方法,包括:
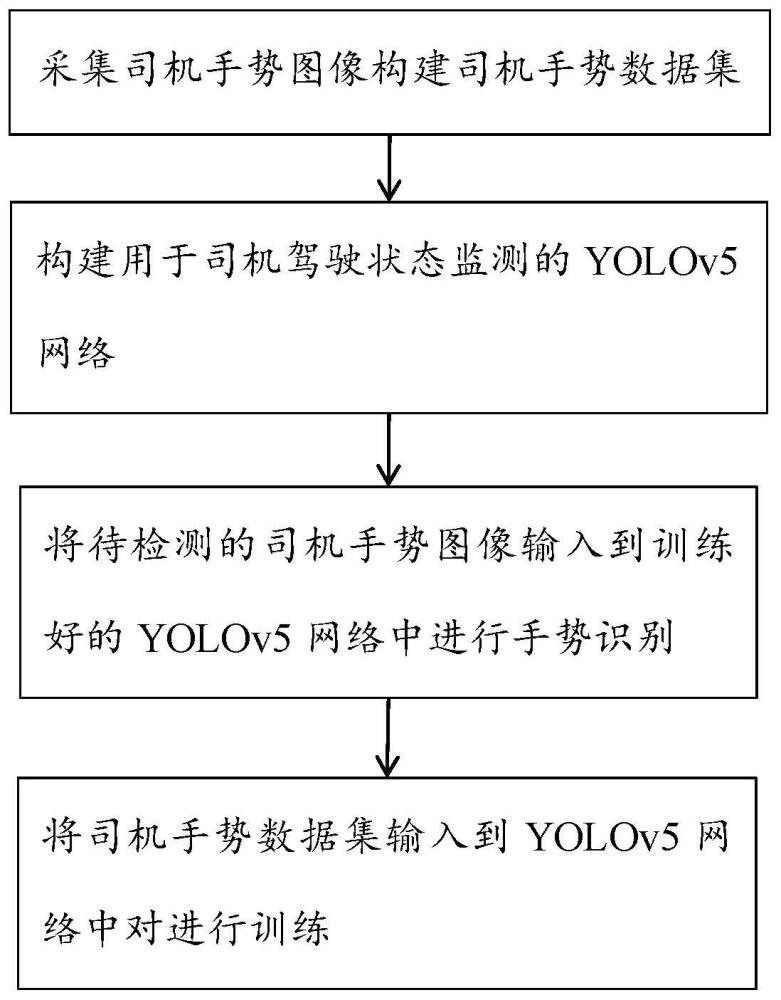
3、采集司机手势图像构建司机手势数据集,构建用于司机驾驶状态监测的yolov5网络,将司机手势数据集输入到yolov5网络中对进行训练;将待检测的司机手势图像输入到训练好的yolov5网络中进行手势识别;
4、其中,构建司机手势数据集包括:
5、通过对司机手势图像进行随机缩放、随机旋转、随机裁剪、明亮度变换对司机手势图像场景进行扩增,得到第一数据集;
6、提取司机手势图像中手势关键部分的roi图像,将所述roi图像输入到深度卷积生成对抗网络dcgan中,通过深度卷积生成对抗网络dcgan生成的图像对司机手势图像类别进行扩增,得到第二数据集;
7、将采集的司机手势图像、所述第一数据集、所述第二数据集结合,获得司机手势数据集。
8、进一步的,所述通过深度卷积生成对抗网络dcgan生成的图像对司机手势图像进行扩增,包括:
9、构建包含有生成器和判别器的深度卷积生成对抗网络dcgan,其中,所述生成器用于将输入的随机噪声转化为生成手势样本,所述判别器用于判别输入到判别器中的样本是真实手势样本还是生成手势样本;
10、将司机手势图像输入到构建的深度卷积生成对抗网络dcgan中对其进行训练,使用训练好的深度卷积生成对抗网络dcgan中的生成器生成司机手势图像。
11、进一步的,所述深度卷积生成对抗网络dcgan,包括:
12、生成器,所述生成器包括生成器输入层,所述生成器输入层的输入是随机噪声;与生成器输入层的输出端连接的第一全连接层,所述第一全连接层用于将输入的随机噪声转化成特征向量;与第一全连接层输出端连接的4个转置卷积层,所述转置卷积层用于对特征向量进行上采样操作;与最后一个转置卷积层连接的输出层,所述输出层用于输出生成手势样本;
13、判别器,所述判别器包括判别器输入层,所述判别器输入层的输入是真实手势样本或生成手势样本;与判别器输入层的输出端连接的4个卷积+bn+leakyrelu层,所述卷积+bn+leakyrelu层用于对输入的图像进行下采样操作;与最后一个卷积+bn+leakyrelu层输出端连接的flatten层,所述flatten层用于将多维矩阵拉伸成一维向量;与flatten层输出端连接的第二全连接层,所述第二全连接层用于输出判断结果。
14、进一步的,所述将司机手势图像输入到构建的深度卷积生成对抗网络dcgan中对其进行训练的过程使用的损失函数为:
15、mingmaxg v(d,g)=ex~pdata[log(d(x))]+ex~pz[log(1-d(g(z)))]
16、其中,pdata是真实数据样本,pz是噪声分布,g是生成器,d是判别器,d(x)是判别器对于输入的真实数据样本的判别结果,g(z)是生成器根据噪声输出的生成手势样本。
17、进一步的,所述随机缩放,包括:
18、对每张司机手势图像,随机生成一个缩放因子;
19、将每张司机手势图像的宽度和高度分别乘以对应的缩放因子,获得随机缩放后的司机手势图像;
20、将随机缩放后的司机手势图像进行裁剪或填充,获得与原司机手势图像大小相同的裁剪-缩放司机手势图像。
21、进一步的,所述随机旋转,包括:
22、对每张司机手势图像,随机生成一个旋转角度;
23、通过图像处理库中的旋转函数将每张司机手势图像旋转对应的旋转角度,获得随机旋转后的司机手势图像;
24、将随机旋转后的司机手势图像进行裁剪或填充,获得与原司机手势图像大小相同的裁剪-旋转的司机手势图像。
25、进一步的,所述明亮度变换,包括:
26、对每张司机手势图像,随机生成一个明亮度变换参数向量,所述明亮度变换参数向量中包括亮度扰动因子、对比度扰动因子、饱和度扰动因子;
27、将明亮度变换参数向量应用到对应的司机手势图像中,包括:
28、将每张司机手势图像的每个像素值乘以亮度扰动因子;
29、将每张司机手势图像的每个像素值减去对应图像的平均亮度后乘以对比度扰动因子,再加上平均亮度;
30、将每张司机手势图像转换为hsv颜色空间,将饱和度通道乘以饱和度扰动因子后转换回rgb颜色空间;
31、将应用明亮度变换参数向量的司机手势图像的像素值调整值0到255的范围内,获得明亮度变换后的司机手势图像。
32、一种计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述的司机手势识别方法。
33、一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述的司机手势识别方法。
34、本发明实施例提供一种司机手势识别方法、装置、计算机设备和储存介质,与现有技术相比,其有益效果如下:
35、本发明通过对司机手势图像进行随机缩放、随机旋转、随机裁剪、明亮度变换对司机手势图像场景进行扩增;通过提取司机手势图像中的roi图像使得深度卷积生成对抗网络dcgan集中关注手势的关键部分,将其输入到深度卷积生成对抗网络dcgan中有助于网络受到无关信息的干扰,生成与真实手势样本最接近的图像,对司机手势图像类别进行扩增,获得了类别均衡、场景多样化且数量充足的更优质量的司机手势数据集,使用该数据集对司机手势识别模型进行训练,可以提高手势识别模型的鲁棒性和泛化性能。
- 还没有人留言评论。精彩留言会获得点赞!