基于主题聚类全局特征的长文档稠密检索方法及系统
本发明涉及自然语言处理技术中的信息检索领域,特别涉及一种基于主题聚类全局特征的长文档稠密检索方法及系统。
背景技术:
1、文档检索旨在搜索最相关的文档,以响应查询,广泛地应用于自然语言处理的诸多领域,例如问答、对话,推荐系统等。在过去的几十年里,稀疏检索模型(如bm25)一直主导着信息检索领域,主要依赖于查询与文档中重叠的关键词的表示和离散特征来获取相关文档,难以充分捕捉文本之间的复杂上下文关系,在理解查询与文档中的近义词及一词多义问题上能力受限。随着深度学习技术的发展,研究者们尝试使用深度神经网络来获取文本连续的稠密表示向量,从而引入了稠密检索模型的概念。
2、随着深度学习技术的发展,尤其是预训练的语言模型(如bert、gpt等),使得对文档和查询进行更深层次的语义建模成为可能,通过将文档和查询表示为密集的嵌入向量,深度学习模型可以更好地理解语义关系,从而提高检索的准确性。与传统的稀疏检索相比,稠密检索不再将文本表示为离散的单词或特征,而是将查询与文档映射在一个低维空间,表示为连续的、稠密的向量,从而能够更好地捕捉查询与文档之间的语义信息,提高文档检索的效果。然而,由于绝大多数预训练模型对文本输入序列长度的限制,使得稠密检索主要集中在片段检索任务上。
3、以bert为代表的预训练模型(plms)以及以chatgpt为代表的大型语言模型(llms)都通过大规模的语料库进行预训练,这使它们能够获得强大的语义理解能力,从而学习到更加丰富的语义信息。这一能力对于提升信息检索任务的性能至关重要。特别值得一提的是,与传统的稠密检索模型相比,大型模型在输入序列长度方面取得了显著的改进。但大型模型在处理长文档检索任务时仍然存在一些潜在难题。一方面,长文档通常包含了大量信息,其中某些信息对于特定信息检索任务可能并不重要。这可能导致模型在文档中受到不必要的信息干扰,从而降低性能。另一方面,由于长文本通常具有复杂的层次结构,包括主题特征、片段之间的关系和篇章结构,文档复杂的层次结构影响捕捉文档信息的全面性,存在信息丢失的风险。因此,亟需一种能够兼顾文档复杂层次结构与全面性信息的方案来优化文档信息检索效果。
技术实现思路
1、为此,本发明提供一种基于主题聚类全局特征的长文档稠密检索方法及系统,通过兼顾长文档中局部特征与文档主题全局特征,在文档检索过程中更好地捕获长文档复杂层次结构和主题特征,以提升文本信息检索效率和性能。
2、按照本发明所提供的设计方案,一方面,提供一种基于主题聚类全局特征的长文档稠密检索方法,包含:
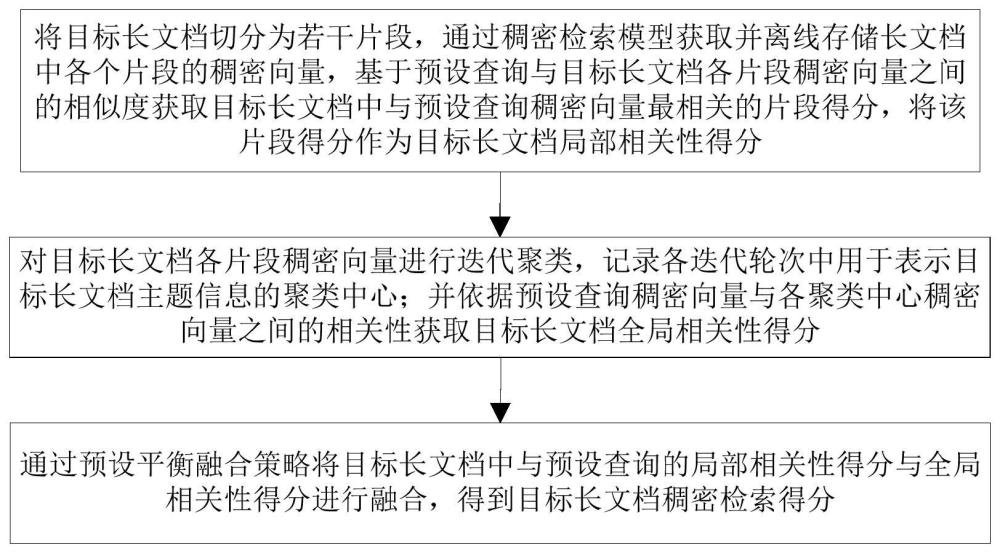
3、将目标长文档切分为若干片段,通过稠密检索模型获取并离线存储长文档中各个片段的稠密向量,基于预设查询与目标长文档各片段稠密向量之间的相似度获取目标长文档中与预设查询稠密向量最相关的片段得分,将该片段得分作为目标长文档局部相关性得分;
4、对目标长文档各片段稠密向量进行迭代聚类,记录各迭代轮次中用于表示目标长文档主题信息的聚类中心,直至长文档中的聚类中心均未更新;并依据预设查询稠密向量与各聚类中心稠密向量之间的相关性获取目标长文档全局相关性得分;
5、通过预设平衡融合策略将目标长文档中与预设查询的局部相关性得分与全局相关性得分进行融合,得到目标长文档稠密检索得分。
6、作为本发明基于主题聚类全局特征的长文档稠密检索方法,进一步地,将目标长文档切分为若干片段,包含:
7、首先,利用bm25算法获取预设查询与长文档集合中每个文档的匹配得分,根据匹配得分对长文档集合中文档进行排序,并依据阈值选取与预设查询相关的目标长文档,其中,长文档集合由信息检索知识库中若干文档组成;
8、然后,依据预设片段长度,将目标长文档切分为预设长度的若干片段,且相邻片段之间存在指定长度的重叠部分。
9、作为本发明基于主题聚类全局特征的长文档稠密检索方法,进一步地,基于预设查询稠密向量与目标长文档各片段稠密向量之间的相关性获取目标长文档中与预设查询最相关的片段得分,包含:
10、首先,基于查询编码器和文档编码器分别获取预设查询稠密向量和目标长文档各片段稠密向量;
11、然后,基于余弦相似度计算预设查询稠密向量与目标长文档中各片段稠密向量之间的相似度得分,以依据最相关的片段来获取目标长文档局部相关性得分。
12、作为本发明基于主题聚类全局特征的长文档稠密检索方法,进一步地,对目标长文档各片段稠密向量进行迭代聚类,迭代聚类过程包括:
13、从各片段稠密向量中随机选择一个片段稠密向量作为初始聚类中心,分别计算聚类中心余其他片段稠密向量之间的距离,并依据距离对聚类结果进行分裂合并,以选取下一轮迭代的聚类中心,直至聚类中心均未更新。
14、作为本发明基于主题聚类全局特征的长文档稠密检索方法,进一步地,依据预设查询稠密向量与各聚类中心稠密向量之间的相关性获取目标长文档全局相关性得分,包含:
15、首先,基于余弦相似度计算预设查询稠密向量与各聚类中心稠密向量之间的相关性得分;
16、然后,对预设查询稠密向量与各聚类中心稠密向量之间的相关性得分进行聚合,以获取目标长文档全局相关性得分。
17、作为本发明基于主题聚类全局特征的长文档稠密检索方法,进一步地,通过预设平衡融合策略将目标长文档中与预设查询的局部相关性得分与全局相关性得分进行融合的过程表示为:其中,sd为目标长文档d稠密检索得分,smax为局部相关性得分,为全局相关性得分,α为影响因子。
18、作为本发明基于主题聚类全局特征的长文档稠密检索方法,进一步地,还包含:
19、利用bm25算法获取与预设查询相关的目标长文档匹配得分,将该匹配得分作为目标长文档稀疏检索得分;
20、依据目标长文档稠密检索得分和稀疏检索得分并通过预设调节因子获取目标长文档检索重排序的最终得分。
21、再一方面,本发明还提供一种基于主题聚类全局特征的长文档稠密检索系统,包含:局部特征获取模块、全局特征获取模块和特征融合计算模块,其中,
22、局部特征获取模块,用于将目标长文档切分为若干片段,通过稠密检索模型获取并离线存储长文档中各个片段的稠密向量,基于预设查询与目标长文档各片段稠密向量之间的相似度获取目标长文档中与预设查询稠密向量最相关的片段得分,将该片段得分作为目标长文档局部相关性得分;
23、全局特征获取模块,用于对目标长文档各片段稠密向量进行迭代聚类,记录各迭代轮次中用于表示目标长文档主题信息的聚类中心;并依据预设查询稠密向量与各聚类中心稠密向量之间的相关性获取目标长文档全局相关性得分;
24、特征融合模块,用于通过预设平衡融合策略将目标长文档中与预设查询的局部相关性得分与全局相关性得分进行融合,得到目标长文档稠密检索得分。
25、本发明的有益效果:
26、本发明通过将长文档表示成重叠片段集合,并计算查询与片段集合中每个片段片段的语义相似度,基于语义相似度获取长文档局部信息;通对片段集合进行聚类分析获取长文档主题聚类向量,并计算每个主题向量与查询词组相似度,聚合所有主题向量相似度获取长文档全局信息,通过一种平衡长文档中局部特征和全局主题特征的融合策略平衡长文档局部信息和全局信息来计算长文档稠密检索得分,使长文档检索能够更加全面考虑到文档主题,在保证文档检索效率的前提下,能够同时提升长文本检索性能,便于在问答、计算机视觉、机器翻译等nlp具体应用领域中部署实施,具有较好的应用前景。
- 还没有人留言评论。精彩留言会获得点赞!