一种面向大规模人工智能服务容器化的镜像部署方法
本发明属于容器化服务的,尤其涉及一种面向大规模人工智能服务容器化的镜像快速部署方法。
背景技术:
1、近年来,大模型技术使aigc得到深度发展与进步,被广泛应用于自动文本摘要、机器翻译、对话系统、创作助手等各种应用场景。而容器服务为大模型的训练与部署提供了更加灵活、可移植的方式。它对大模型的部署过程进行了简化,并提供了基于k8s等编排工具的弹性扩展和依赖管理的能力,使得大模型的应用更加高效和可靠。因此,对容器镜像的部署过程进行加速具有重要意义。
2、本发明所涉及的背景技术包括以下几方面:
3、对于containerd而言,原生的镜像提取方案是将镜像的所有层下载到本地后,再对每一层进行串行加载,因此加载过程通常需要消耗大量时间。本发明能够实现加速容器部署和启动过程,从而提高应用开发和部署的效率,改善应用程序的响应、部署的性能和资源利用。
4、containerd是一个开源的容器运行时,它可以管理容器的生命周期,包括容器的创建、启动、停止、删除等操作。containerd提供了一组api,用于创建、启动、停止和删除容器,同时还提供了镜像管理功能。容器是一种轻量级的虚拟化技术,它可以将应用程序及其依赖项打包到一个可移植的容器中,从而实现跨平台的部署。
5、容器是由镜像实例化而来。简单来说,镜像是文件,容器是进程。容器是基于镜像创建的,即容器中的进程依赖于镜像中的文件。containerd的镜像是一个只读的模板、一个独立的文件系统,包括运行容器所需的数据,可以用来创建新的容器。
6、containerd利用容器来运行应用,即容器是使用镜像创建的运行实例。它类似虚拟机,可以执行包含启动,停止,删除等操作。每个容器间是相互隔离的。容器中会运行特定的运用,包含特定应用的代码及所需的依赖文件。
7、镜像是容器的基础,它是一个只读的文件系统,包含了应用程序及其依赖项的所有内容。当容器启动时,它会使用镜像作为文件系统,从而实现应用程序的运行。容器镜像由一系列只读的文件系统层(layer,简称层或分层)组成,每个层都包含了文件系统的增量变化。每个层都可以看作是一个文件系统的快照,包含了新增、修改或删除的文件。
8、1.镜像及其加载(imageextraction)
9、容器镜像是一种轻量级、可移植和自包含的软件打包方式,用于将应用程序及其运行时环境、依赖项和配置文件等打包为一个可执行的单元,通常用于在容器化平台(如containerd、k8s等)上部署和运行应用程序。容器镜像由一系列只读的文件系统层(layer)组成,每个层都包含了文件系统的增量变化。每个层都可以看作是一个文件系统的快照,包含了新增、修改或删除的文件。
10、镜像加载即从容器镜像里(包括从官方库中下载、由导出的镜像压缩包解压等方式)提取出所需的文件和组件,以便在主机或容器运行时环境中启动容器。在容器化环境中,镜像是应用程序和其依赖项的打包和分发方式,包含了应用程序运行所需的文件系统、库、配置文件等。容器镜像加载过程在容器化应用程序的部署、扩展、管理和交付中发挥着关键的作用,具有广泛的应用价值。
11、2.镜像元数据库(metadata)
12、镜像元数据库是使用golang编写的、基于boltdb的嵌入式的key/value数据库,存储containerd镜像元数据信息的数据库,以文件形式存储,包括meta.db和metadata.db两个文件。
13、(1)meta.db用于存储containerd整体的元数据。例如,对images和bundles的持久化引用,包括imagename、createdat、updatedat、target、digest、mediatype、size、labels等信息。
14、(2)metadata.db主要用于存储容器和镜像的元数据信息,主要包括各个镜像层之间的父子关系。此外,该文件也存储它们各自的createdat、updatedat等基本信息。
15、3.goroutines
16、goroutine是go语言中的并发执行单位,可以将其视为轻量级线程。与线程相比,创建goroutines的成本非常小。它的实现是基于协程的,是一种用户态的调度技术,由go运行时(runtime)管理,有自己的栈、instruction pointer和其他信息,用于调度。这一技术可以很好地提高算法的并行效率,且造成的额外开销很小。
17、现有技术存在的问题:
18、这样的机制带来的问题在于,每一个镜像分层在下载完成后,不能立即开始解压,要阻塞等待直到全部n个分层下载完毕。实际上,镜像的各个分层大小往往是不均匀的,因此下载完成的时间也不尽相同,由此造成了大量阻塞时间消耗。
19、这是由以下几个原因导致的:
20、1.层间依赖关系
21、(1)diffid是容器镜像中每个层的唯一标识符,用于表示每个层之间的差异,每个文件系统层都是容器镜像中的一个只读文件系统快照;chainid是由容器镜像中所有层的diffid组成的标识符。对于每一层(非首层)而言,其chainid需要根据自身的diffid和其父层的chainid组合计算sha256哈希值得出。即:
22、·若该镜像层是最底层,那么其chainid和diffid相同
23、·否则,chainid=sha256(父层chainid+""+本层chainid)
24、上述过程限制了原生的系统必须使用串行的加载策略。
25、(2)containerd的元数据信息均存储于meta.db和metadata.db当中,这就意味着当每一层加载完后,才能将它和其他层的父子依赖关系进一步更新到元数据库当中。
26、2.计算资源
27、由于并行加载多个层级可能会对存储设备造成过大的负载。当多个进程或线程同时读取和写入数据时,可能会导致存储设备的性能瓶颈,从而影响加载速度。对于原生containerd而言,设计者更倾向于软件体积和资源消耗的轻量化,因此在时间性能上就造成了一些损失。
技术实现思路
0、
技术实现要素:
1、针对现有技术存在技术问题,本发明提供一种面向大规模人工智能服务容器化的镜像快速部署方法,该方法在人工智能服务容器对镜像的提取过程实现异步、并行地进行加载,从而提高了镜像提取的效率和性能。
2、为了解决现有技术问题,本发明采用如下技术方案:
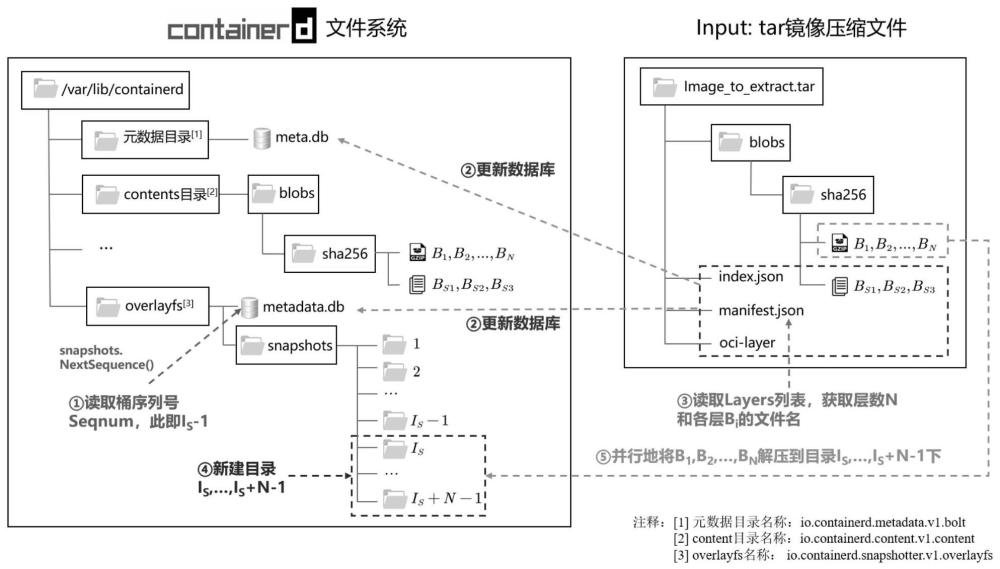
3、一种面向大规模人工智能服务容器化的镜像部署方法,所述镜像部署方法基于智能服务容器系统,所述智能服务容器系统包括镜像文件单元、第一元数据库meta.db、第二元数据库metadata.db和镜像快照文件层,其中:
4、所述镜像文件单元用于读入.tar格式的镜像压缩文件夹;所述tar格式的镜像压缩文件夹由镜像文件配置层和未解压的.tar.gz格式的镜像分层blobs;其中:所述镜像文件配置层由第一镜像配置文件index.json、第二镜像配置文件config.json和第三配置文件manifest.json构成;包括如下步骤:
5、所述智能服务容器系统建立加载镜像为i{l1,l2,...,ln};
6、将overlayfs目录下metadata.db的v1/snapshots子桶的序列号seqnum,令is←seqnum+1;
7、从镜像配置文件中读取镜像的相关信息更新到第一元数据库meta.db和第二元数据metadata.db的对应位置;
8、所述镜像快照文件层读取第三配置文件的layers列表获得i的分层总数n;即:layers列表里按序存储了b1,...,bn的文件名;即:
9、layers[i]=sha256(bi),i∈[1…n]
10、所述镜像快照文件层新建n个目录d1,d2,...,dn;其中:di以is+i-1命名;
11、所述镜像快照文件层通过n个go-routine,让第i个go-routine负责将bi解压到di/fs目录下。
12、进一步地,从镜像配置文件中读取镜像的相关信息更新到第一元数据库meta.db对应位置过程;包括:
13、所述第一元数据库根据第一镜像配置文件、第二镜像配置文件和第三配置文件的镜像信息在v1/default/content/blob子桶位置更新bi的标签元数据;
14、所述第一元数据库根据第一镜像配置文件的镜像信息在v1/default/images子桶位置更新镜像i的元数据;
15、所述第一元数据库根据各层chainid的元数据在v1/default/snapshots/overlayfs位置更新本层chainid、父层chainid、子层chainid、时间戳。
16、进一步地,从镜像配置文件中读取镜像的相关信息更新到第二元数据metadata.db的对应位置过程;包括:
17、所述第二元数据库根据各层chainid的元数据在v1/parents位置更新全部li的父子关系序列;
18、所述第二元数据库根据各层chainid和3个特殊层,即:bs1,bs2,bs3;在v1/snapshots位置更新大小、id、inode数量、类别、父层chainid、子层chainid、时间戳。
19、有益效果
20、本发明通过镜像层异步并行提取,相比于原生containerd而言可以同时对多个镜像分层进行加载,减少了传统原生方法串行提取镜像层的时间消耗,从而加快了容器的部署速度,如图2所示。经过初步实验,对于docker.io/library/python:3.9.3镜像而言,加载部分的用时减少近50%,效果较好。
21、此外,使用goroutine方法实现的并行化方法也防止了解压过程中计算资源的大规模消耗,提高了资源利用率。
22、本发明通过镜像层异步并行提取,摆脱了原生containerd的镜像加载过程因对层序的依赖而造成的无法并行加载的性能问题。相比于原生containerd而言可以同时对多个镜像分层进行加载,减少了原方法串行提取镜像层的时间消耗,从而加快了容器的部署速度,如图2所示。经过初步实验,对于python:3.9.3镜像而言,加载部分的用时减少近50%,效果较好。
23、此外,使用goroutine方法实现的并行化方法也防止了解压过程中计算资源的大规模消耗,提高了资源利用率。
- 还没有人留言评论。精彩留言会获得点赞!