一种受果蝇轨迹分布及交互模式启发的飞行行为生成模型
本发明属于生物仿生计算领域,涉及一种受果蝇轨迹分布及交互模式启发的飞行行为生成模型。本发明实现了对果蝇群体的飞行行为仿真建模,能够在有限计算资源下根据配置生成包含多种行为模式的果蝇飞行行为,从而辅助生物行为学的实验研究,为飞行生物的感知、决策以及运动提供有效的模拟实验环境;同时应用于机器人的设计研究,提升受昆虫启发的微小型机器人集群在有限计算资源情况下的任务执行与环境探索效率。
背景技术:
1、通过理解自然生物的感知、决策与运动的内在机制,实现对生物复杂行为的仿真建模,从而构建并控制能够与外界环境交互的虚拟生物,是群体智能、计算机动画以及多智能体无人系统领域的研究热点。
2、果蝇作为相关研究中一种常用的模式生物,不仅拥有多样的飞行行为模式,并且能够在飞行过程中对环境进行高效的探索。果蝇在形成群体后,通过有限感知范围内的局部交互作用,能够表现出更加复杂优化的群体行为。同时,由于果蝇与蜜蜂、信天翁等生物的飞行现象存在相似性,对果蝇飞行行为的分析具有一定代表性,能够推广至其他自然飞行生物的研究中。
3、但直接对大规模果蝇飞行轨迹数据进行采集存在一定的困难。首先,在果蝇飞行轨迹数据采集平台的搭建过程中,由于果蝇具有个体小、飞行速度快的特点,摄影系统硬件需要达到一定的帧率、清晰度要求;其次,在对果蝇飞行轨迹数据进行轨迹识别、跟踪以及重建的过程中,算法会引入计算噪声,大规模的数据会加剧噪声的影响,使得获取到的果蝇飞行轨迹数据存在明显的误差,对下游的果蝇飞行行为分析任务产生影响。因此,对果蝇飞行行为进行仿真建模能够避免数据采集的困难。
4、对果蝇飞行行为的传统仿真建模方法包括了粒子群、vicsek、couzin以及boids等模型算法,不同方法分别设置不同的作用方式,能够模拟果蝇群体交互、刻画果蝇飞行行为。例如,vicsek模型设置了个体速度同步化的建模假设;couzin模型设置了领导者追随与角色分化的建模假设;而boids模型设置了个体之间局部的分离作用、聚集作用、对齐作用的建模假设。但是,这些传统方法较为依赖于特征与规则的手工设计,只能处理特定的飞行行为模式,对复杂环境的泛化能力较差。
5、果蝇的飞行行为符合马尔可夫模型,由此引入深度强化学习方法,在训练学习的过程中优化果蝇的飞行行为智能。作为一种通过智能体与环境的交互学习来优化决策策略的机器学习方法,深度强化学习结合深度神经网络的非线性拟合能力和强化学习的决策优化能力,能够自动从原始输入中提取特征,并通过反馈奖励信号逐步优化策略。深度强化学习可以处理复杂的决策问题,无需人为地设计特征与规则,产生的策略具备一定的泛化能力,能够有效地应用于果蝇飞行行为的建模过程中。
6、作为深度强化学习中的一种常用方法,ddpg模型基于actor-critic的算法框架,采用深度神经网络作为actor函数和critic函数的近似,其中actor网络输出每个状态对应的动作、critic网络评估当前状态与动作的价值。由此,深度强化学习为果蝇飞行行为生成任务提供了一种实用的手段。
技术实现思路
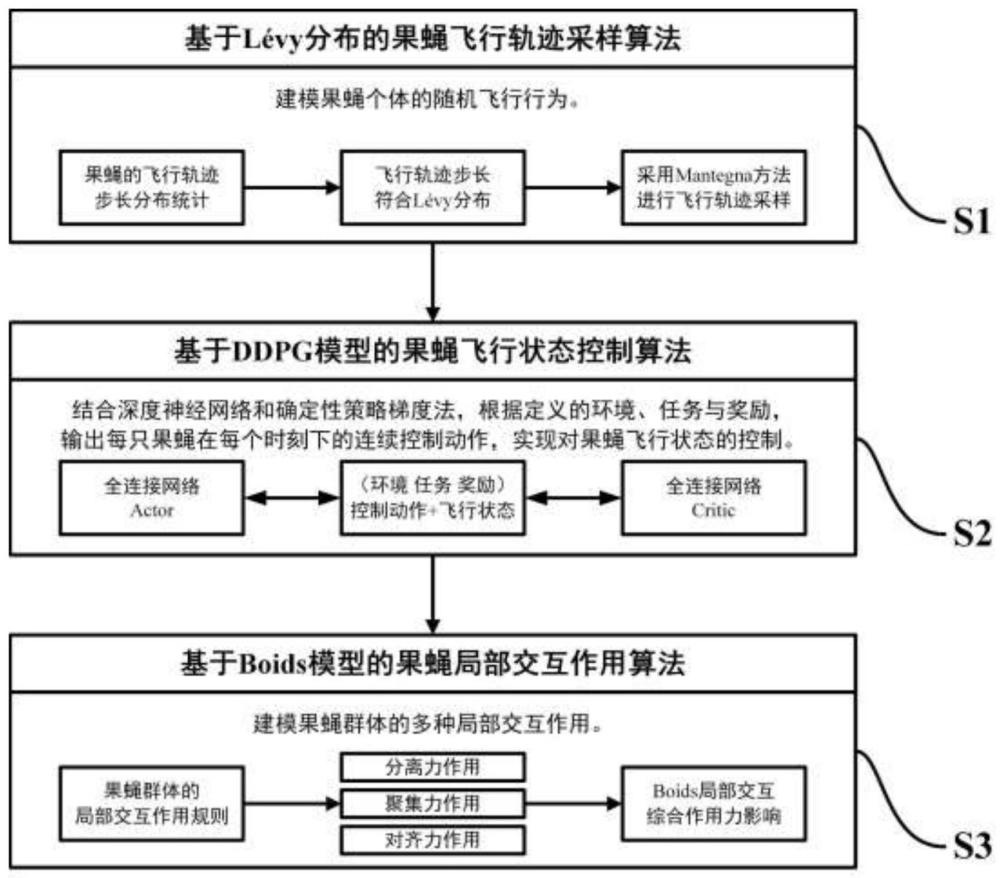
1、针对上述果蝇飞行轨迹数据采集困难以及传统仿真建模方法依赖于手工设计特征与规则且泛化能力差的问题,本发明的目的是提供一种受果蝇轨迹分布及交互模式启发的飞行行为生成模型,是一种结合果蝇飞行轨迹分布、局部交互模式以及深度强化学习的飞行行为生成模型,该模型包含了三个模块:第一模块为基于lévy分布的果蝇飞行轨迹采样算法模块,对果蝇个体的飞行行为进行随机建模;第二模块为基于ddpg模型的果蝇飞行状态控制算法模块,通过深度强化学习实现对果蝇飞行状态的控制;第三模块为基于boids模型的果蝇局部交互作用算法模块,考虑果蝇群体的多种局部交互作用及其对飞行状态的影响效果。通过三个模块的串联,实现对果蝇的飞行行为进行可泛化的仿真建模,生成包含多种行为模式的飞行行为。
2、本发明模型具体如下:
3、(s1)基于lévy分布的果蝇飞行轨迹采样算法模块:根据果蝇飞行轨迹数据中的分布统计分析,能够启发飞行行为生成过程中的轨迹步长采样方法,为所有果蝇生成大小各异、方向各异的飞行轨迹步长,进一步实现对果蝇个体飞行行为的随机建模,符合果蝇高效探索环境的特征;
4、(s2)基于ddpg模型的果蝇飞行状态控制算法模块:果蝇的飞行行为符合马尔可夫模型,可以被建模为飞行状态在环境空间中受到连续控制动作影响的结果,因此基于深度强化学习中的ddpg模型对果蝇的飞行状态进行控制更新。根据环境空间中的基本飞行任务定义了包含群体距离惩罚项的奖励值函数,结合噪声探索与经验利用,通过深度神经网络输出每只果蝇在每个时刻的连续动作,利用控制动作对采样获得的飞行速度向量进行调整,从而实现飞行状态的控制更新;
5、(s3)基于boids模型的果蝇局部交互作用算法模块:利用boids模型建模果蝇群体的多种局部交互作用关系及其对飞行状态的影响效果,对果蝇群体中每个个体根据周围个体的位置与速度进行移动的方式进行了描述,包括分离、聚集以及对齐的三种基本作用规则,通过局部交互过程中基本作用规则的叠加模拟果蝇群体的交互模式特征。在此基础上,添加了果蝇受三维环境空间的反馈限制,进一步提升了建模效果。
6、优选的,所述(s1)构建的基于lévy分布的果蝇飞行轨迹采样算法模块的具体内容为:
7、(1-1)将三维空间中所有果蝇的飞行轨迹定义为三维空间坐标点序列的集合,具体为:
8、
9、
10、
11、i∈[1,n]t∈[1,t+1]
12、其中,n是果蝇的数量;t+1是果蝇的飞行总时长;fi表示编号为i的果蝇;traj表示所有果蝇的飞行轨迹集合;表示果蝇fi的飞行轨迹序列;表示果蝇fi在t时刻的三维空间坐标点,按照时间顺序排列构成飞行轨迹序列。
13、(1-2)果蝇的飞行轨迹由频繁的局部运动与间歇的长跳跃运动组成,飞行轨迹数据集的步长统计符合长尾幂律分布,即lévy分布,具体为:
14、p(x)~x-1-α0<α<2
15、其中,x是飞行步长;p(x)是飞行步长x在统计分布中的出现概率;α是lévy指数,取值范围为(0,2)。
16、(1-3)受果蝇飞行轨迹步长分布统计的启发,采用mantegna方法为每只果蝇的飞行过程设置了符合lévy分布的步长,具体为:
17、
18、σv=1,0<β≤2
19、其中,s表示果蝇的飞行步长;u、v分别符合均值为0、方差为和的正态分布;β为常数,取值范围为(0,2];γ是gamma函数,采用标准的计算过程,即为:
20、
21、(1-4)利用基于mantegna方法采样初始化的步长,可以得到果蝇fi在t时刻的飞行速度三维向量具体为:
22、
23、其中,sx、sy、sz分别表示采样初始化获得的三维空间中的飞行步长数值。
24、优选的,所述(s2)构建的基于ddpg模型的果蝇飞行状态控制算法模块的具体内容为:
25、(2-1)将环境空间定义为一个大小为l1×l2×l3的长方体,并且在长方体的三维环境空间中定义了一个目标点goal。
26、(2-2)利用目标点进行了两种基本飞行任务的设置,分别为接近目标点与远离目标点,分别对应了常见的果蝇飞行实验场景。
27、根据两种基本飞行任务定义了奖励值函数,在奖励值函数中添加了群体距离惩罚项,防止果蝇群体在接近目标点时过于聚集、在远离目标点时过于分散,使得果蝇能够在三维环境空间中保持群体特性,具体为:
28、其中,奖励值函数计算值为标量reward;||·||2为l2范数的计算公式;gd表示群体中所有果蝇之间的平均距离;state表示每只果蝇在每个时刻的飞行状态,其值设置为三维空间坐标点,具体为:
29、
30、所有果蝇在t=0时刻的空间位置是通过随机初始化获得的,具体的初始化过程为:
31、
32、其中,random(0,1)表示能够生成(0,1)范围内的随机浮点数的函数。
33、(2-3)在ddpg模型中,基于全连接神经网络实现的actor函数与critic函数分别对连续控制动作进行输出与评估,通过网络的训练学习提升动作对果蝇飞行状态的控制效果。
34、训练过程采用了软目标更新技术,将actor网络和critic网络分别扩展为训练网络actor_online、critic_online以及目标网络actor_target、critic_target,通过将训练网络的参数逐步缓慢地复制至目标网络,能够消除噪声的干扰影响,实现网络训练过程的快速稳定收敛。
35、同时引入经验回放技术,设置了名为replay_buffer的经验池,存储actor_online网络产生的用于训练抽取的经验数据样本,从而降低经验数据样本之间的相关性,有效地提升数据样本的利用效果。
36、(2-5)在ddpg每一轮的训练学习过程中,首先将每只果蝇在每个时刻的飞行状态state输入actor_online网络,获得控制动作action,具体为:
37、
38、其中,ax、ay与az分别为控制动作在三维空间中的分量,满足值为(0,1)的限制。
39、将飞行状态state作为奖励值函数reward_func的输入,得到奖励值标量reward。
40、(2-6)为了促进果蝇在环境空间中的探索性,在控制动作action中进行了高斯随机噪声的添加,将噪声探索与经验利用相结合,增强控制动作的泛化性。添加高斯噪声后的控制动作仍保持值为(0,1)之间的限制,具体为:
41、
42、其中,nx、ny、nz分别为高斯噪声noise在三维空间中的分量,均符合均值为0、方差为的正态分布;clip(·,min=·,max=·)函数表示将输入的数值范围限定在min值和max值之间。
43、(2-7)将兼顾了探索与利用的控制动作action与飞行轨迹采样算法初始化的飞行速度进行向量逐元素相乘,实现对飞行速度向量的调整,维持果蝇在个体层面的随机飞行行为特性。
44、基于控制动作调整的飞行速度向量,飞行状态state更新为果蝇fi在下一时刻的飞行状态next_state,具体为:
45、
46、其中,next_state为三维向量。
47、利用飞行状态state、控制动作action、奖励值reward与下一飞行状态next_state构建元组sars=(state,action,reward,next_state),并将sars存储到replay_buffer中。
48、(2-8)当replay_buffer中存储的元组数量达到训练学习所需的batch_size大小后,通过策略梯度法对actor_online、actor_target网络以及critic_online、critic_target网络进行参数的更新。
49、从经验回放池replay_buffer中以batch_size为大小随机抽取一批sars,并构造训练数据样本,分别为:
50、
51、其中,statbeatch、actionbatch以及next_stabtaetc均表示大小为batch_size×3的矩阵;而rewardbatch则表示大小为batch_size×1的向量。
52、(2-9)statebatch与actionbatch输入critic_online网络,从而直接计算获得状态动作q值,具体为:
53、q=critic_online(statebatch,actionbatch)
54、同时,将next_stabtaetch作为actor_targ网络的输入,计算得到next_actionbatch,并将next_statebatch与next_actionbatch同时输入critic_target网络,输出与折扣因子γ相乘进行调整,与rewardbatch相加获得目标状态动作q值q_target,具体为:
55、
56、其中,γ作为折扣因子,满足值为(0,1]的限制。
57、对q值与目标q值采用均方误差损失函数计算,构建q值损失q_loss,具体为:
58、
59、由此,根据策略梯度法,得到对critic_online网络参数的更新过程,具体为:
60、θcritic_online←θcritic_online-αcritic·▽(q_loss)
61、其中,θcritic_online表示critic_online网络的参数;αcritic表示critic_online网络参数更新的学习率;▽(q_loss)表示对q_loss进行的梯度计算过程。
62、将statebatch以及statebatch通过actor_online网络的输出同时作为critic_online网络的输入,输出值平均求反得到策略损失policy_loss,具体为:
63、policy_loss=-mean(critic_online(statebatch,actor_online(statebatch)))
64、其中,mean为求平均值函数。
65、由此,根据策略梯度法,得到对actor_online网络参数的更新过程,具体为:
66、θactor_online←θactor_online-αactor·▽(policy_loss)
67、其中,θactor_online表示actor_online网络的参数;αactor表示actor_online网络参数更新的学习率;▽(policy_loss)表示对policy_loss进行的梯度计算过程。
68、(2-10)最后,通过软更新机制,利用actor_online以及critic_online网络的参数逐步缓慢地对actor_target以及critic_target网络的参数进行更新,具体为:
69、
70、其中,θactor_target与θcritic_target分别表示actor_target网络与critic_target网络的参数,ζ表示软更新率,满足值为(0,1]的限制。
71、优选的,所述(s3)构建的基于boids模型的果蝇局部交互作用算法模块的具体内容为:
72、(3-1)对boids模型中的三种基本作用规则进行了定义,通过作用力的形式进行表现,包括了分离力、聚集力以及对齐力,以果蝇fi为例,具体的计算如下:
73、分离力使得果蝇fi与其他果蝇保持距离,具体为:
74、
75、其中,boids_space表示果蝇的个体空间范围;表示果蝇fi在t时刻受到的分离力,是一个三维向量;表示在t时刻果蝇fi的个体空间范围内的果蝇数量,根据的计算结果进行逐一累加。
76、聚集力使得果蝇fi向其他果蝇进行靠拢,具体为:
77、
78、其中,boids_sight表示果蝇的视野半径范围;表示果蝇fi在t时刻受到的聚集力,是一个三维向量;表示在t时刻果蝇fi的视野半径范围内的果蝇数量,根据的计算结果进行逐一累加。
79、对齐力使得果蝇fi与其他果蝇保持方向一致,具体为:
80、
81、其中,表示果蝇fi在t时刻受到的对齐力,是一个三维向量。
82、(3-2)将分离力聚集力以及对齐力加权求和,得到果蝇fi在t时刻受到的基于boids模型的局部交互综合作用力具体为:
83、
84、其中,ωs是分离力的权重,ωc是聚集力的权重,ωa为对齐力的权重,均为标量。
85、将局部交互综合作用力直接作用于果蝇fi的飞行状态上,具体为:
86、
87、其中,三维向量next_state是ddpg模型控制更新后的果蝇飞行状态。
88、(3-3)最后,添加了果蝇受到的环境反馈限制,保证果蝇的所有飞行状态均处于定义的三维环境空间中,具体为:
89、pit+1=clip(pit+1,min=(0,0,0),max=(l1,l2,l3))
90、至此,构建完成受果蝇轨迹分布及交互模式启发的飞行行为生成模型。
91、本发明的有益效果是:
92、(1)本发明受到果蝇轨迹步长统计分布以及局部交互作用模式的启发,提出了基于lévy分布的果蝇飞行轨迹采样算法模块与基于boids模型的果蝇局部交互作用算法模块,分别对果蝇在个体层面的随机飞行行为以及果蝇在群体层面的多种局部交互作用进行了建模,从而使得生成的飞行行为能够更好地拟合真实飞行行为中的特征;
93、(2)本发明根据果蝇飞行行为符合马尔可夫模型的特点,提出了基于ddpg模型的果蝇飞行状态控制算法模块,将果蝇的飞行行为建模为飞行状态在环境空间中受到连续控制动作影响的结果。根据环境空间中的基本飞行任务定义了包含群体距离惩罚项的奖励值函数,使得果蝇能够在三维环境空间中保持群体特性。在控制动作中添加高斯随机噪声,将噪声探索与经验利用相结合,增强控制动作的泛化性,促进果蝇在环境空间中的探索性。控制动作通过调整飞行轨迹采样算法获得的果蝇飞行速度向量,实现对飞行状态的控制更新,维持果蝇在个体层面的随机飞行行为特性。将全连接神经网络作为actor函数和critic函数的近似,引入软目标更新技术与经验回放技术,实现网络训练过程的快速稳定收敛;
94、(3)本发明避免了果蝇飞行轨迹数据采集过程中的困难、传统仿真建模方法依赖于手工设计特征与规则且泛化能力差的问题,定义的基本飞行任务对应了常见的果蝇飞行实验场景,能够在有限计算资源下根据配置生成包含多种行为模式的果蝇飞行行为;
95、(4)本发明能够辅助生物行为学的实验研究,为飞行生物的感知、决策以及运动提供有效的模拟实验环境;同时能够应用于机器人的设计研究,提升受昆虫启发的微小型机器人集群在有限计算资源情况下的任务执行与环境探索效率。
- 还没有人留言评论。精彩留言会获得点赞!