一种对马来酸二乙酯生产数据智能管理方法与流程
本发明涉及数据聚类,具体涉及一种对马来酸二乙酯生产数据智能管理方法。
背景技术:
1、马来酸二乙酯主要由顺丁烯二酸酐和乙醇在硫酸存在下酯化后分馏得到,通常液体混合物中各成分的沸点不同,通过适当加热可以使其中沸点较低的成分首先蒸发,然后通过冷凝收集从而实现分离混合物。因此,对分馏过程中温度数据的检测与存储意义重大。
2、目前对于制备马来酸二乙酯中分馏过程中温度传感器的温度数据的存储一般采用无损压缩存储,但是由于反应过程中可能存在温度数据相似情况,采用无损压缩存储可能会占用较多的冗余空间,降低压缩效率。
技术实现思路
1、为了解决马来酸二乙酯制备过程中温度数据存在相似情况,采用无损压缩存储占用较多的冗余空间且降低压缩效率的技术问题,本发明的目的在于提供一种对马来酸二乙酯生产数据智能管理方法,所采用的技术方案具体如下:
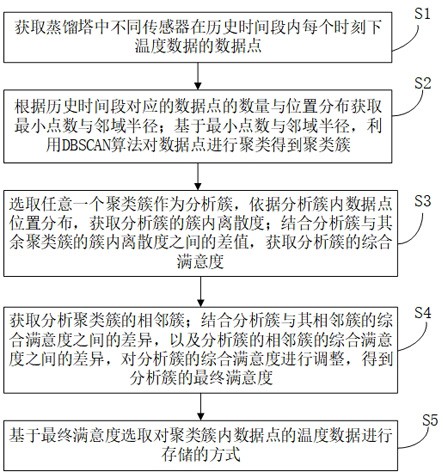
2、本发明提出了一种对马来酸二乙酯生产数据智能管理方法,该方法包括:
3、获取蒸馏塔中不同传感器在历史时间段内每个时刻下温度数据的数据点;
4、根据历史时间段对应的数据点的数量与位置分布获取最小点数与邻域半径;基于所述最小点数与所述邻域半径,利用dbscan算法对数据点进行聚类得到聚类簇;
5、选取任意一个聚类簇作为分析簇,依据分析簇内数据点位置分布,获取分析簇的簇内离散度;结合分析簇与其余聚类簇的所述簇内离散度之间的差值,获取分析簇的综合满意度;
6、获取分析聚类簇的相邻簇;结合分析簇与其相邻簇的所述综合满意度之间的差异,以及分析簇的相邻簇的所述综合满意度之间的差异,对分析簇的综合满意度进行调整,得到分析簇的最终满意度;
7、基于所述最终满意度对聚类簇内数据点的温度数据进行压缩存储。
8、进一步地,所述获取最小点数与邻域半径的方法,包括:
9、以时间为横轴、温度数据为纵轴建立直角坐标系;将所有数据点在所述直角坐标系进行标注得到每个数据点的坐标点;获取所有坐标点的凸包;
10、将坐标点的总数量与所述凸包的面积的比值向上取整,得到最小点数;
11、选取任意一个数据点作为分析数据点,获取分析数据点与除分析数据点外的其余每个数据点之间的欧式距离,将所述欧式距离从小到大顺序排列得到距离序列,将距离序列中第最小点数个欧式距离作为分析数据点的初始邻域距半径;
12、将所有数据点的所述初始邻域半径的均值作为邻域半径。
13、进一步地,所述依据分析簇内数据点位置分布,获取分析簇的簇内离散度的方法,包括:
14、将分析簇内数据点在所述直角坐标系中对应坐标点作为分析坐标点;获取分析坐标点的最小外接矩形;
15、选取任意一个分析坐标点作为目标坐标点,将目标坐标点与除目标坐标点外的其余分析坐标点之间的欧式距离的均值作为目标坐标点的初始均距离;将所有分析坐标点的所述初始均距离的均值作为综合均距离;
16、对分析簇内数据点进行降维分析,获取最大主成分向量与最小主成分向量,将所述最大主成分向量的模长作为第一模长,将最小主成分向量的模长作为第二模长;
17、获取分析簇内的核心点;结合所述最小外接矩形的长度与宽度、所述综合均距离、所述第一模长、所述第二模长以及所述核心点的数量,获取分析簇的簇内离散度。
18、进一步地,所述分析簇的簇内离散度的计算公式如下:
19、;式中,u为分析簇的簇内离散度;l为分析簇内数据点对应的所述最小外接矩阵的长度;h为分析簇内数据点对应的所述最小外接矩阵的宽度;为所述综合均距离;hn为分析簇内核心点的总数量;为所述第一模长;为所述第二模长;c为预设正数;exp为以自然常数e为底数的指数函数。
20、进一步地,所述获取分析簇的综合满意度的方法,包括:
21、获取所述分析簇与除分析簇外的其余每个聚类簇的形心之间的欧式距离,将最小的所述欧式距离对应的聚类簇作为分析簇的关联簇;
22、利用聚类簇的所述簇内离散度的极差,对所述关联簇与分析簇的所述簇内离散度的差值进行归一化,得到分析簇的离散差值;
23、根据分析簇与其关联簇的形心之间的欧式距离,以及所述离散差值,获取分析簇的综合满意度;分析簇与其关联簇的形心之间的欧式距离与所述离散差值均与所述综合满意度为正相关的关系。
24、进一步地,所述获取分析簇的相邻簇的方法,包括:
25、将分析簇的形心在所述直角坐标系中对应坐标点作为分析簇的形心坐标;
26、选取除分析簇外的其余任意一个聚类簇作为判断簇,在所述直角坐标系中,将连接分析簇与判断簇的所述形心坐标形成的线段作为判断线段;
27、选取除分析簇与判断簇外的其余任意一个聚类簇作为待定簇,获取待定簇内数据点在所述直角坐标系对应的坐标点的凸包作为待定凸包,若所述判断线段与所述待定凸包不存在交点,则判断线段上不存在待定簇;
28、若所述判断线段上不存在除分析簇与判断簇外其余的聚类簇,则将判断簇作为分析簇的相邻簇。
29、进一步地,所述分析簇的最终满意度的获取方法,包括:
30、根据分析簇与其相邻簇的所述综合满意度之间的差异,以及分析簇的所述相邻簇的综合满意度之间的差异,获取分析簇的局部异常度;
31、当所述局部异常度大于或者等于预设异常阈值时,将分析簇的相邻簇的所述综合满意度的均值作为分析簇的最终满意度;当所述局部异常度小于预设异常阈值时,将分析簇的综合满意度作为分析簇的最终满意度。
32、进一步地,所述分析簇的局部异常度的计算公式如下:
33、;式中,p为分析簇的局部异常度;z为分析簇的综合满意度;为分析簇的第e个相邻簇的综合满意度;e为分析簇的相邻簇的总数量;为分析簇的第r个相邻簇的综合满意度;为分析簇的第s个相邻簇的综合满意度;c为预设正数;为绝对值函数。
34、进一步地,所述基于所述最终满意度对聚类簇内数据点的温度数据进行压缩存储的方法,包括:
35、将大于或者等于预设满意阈值的最终满意度对应的聚类簇作为集中型簇,小于预设满意阈值的最终满意度对应的聚类簇作为一般型簇;
36、将每个集中型簇内数据点的温度数据的均值作为每个集中型簇内每个数据点的修正温度数据,利用游程编码对每个一般型簇内数据点的修正温度数据进行压缩;对每个一般型簇内数据点的温度数据进行无压缩存储。
37、进一步地,所述对分析簇内数据点进行降维分析的算法为主成分分析算法。
38、本发明具有如下有益效果:
39、本发明实施例中,为了提高历史时间段对应的数据点的聚类效果,根据数据点的数量与位置分布获取最小点数与邻域半径,并基于两个参数利用dbscan算法对数据点进行聚类得到聚类簇;聚类簇内数据点的位置分布呈现聚类簇内数据点的聚类情况即簇内离散度,单纯通过簇内离散度衡量样本空间中聚类簇的聚类效果不够全面,为了更准确地衡量聚类的满意程度,结合聚类簇之间距离来判断聚类簇之间的分布情况,获取分析簇的综合满意度;由于反应进行中伴随着不同的吸热与放热,导致局部反应温度数据可能存在异常,即可能存在某个时间段内某个聚类簇内数据点较为聚集,但其周围大多数聚类簇内数据点较为分散;或者出现与上述相反的情况;上述两种情况局部的综合满意度异常的情况会导致基于综合满意度分类进行压缩时产生异常,分析簇与其相邻簇的综合满意度的差异以及相邻簇的综合满意度之间的差异均能呈现分析簇内数据点的温度数据的异常情况,结合两种因素对分析簇的综合满意度调整至于周围聚类簇的综合满意度相似的水平,得到最终满意度,从而实现一致压缩方式;基于最终满意度自适应选取对聚类簇内数据点的温度数据进行压缩存储的方式,避免反应过程中存在相似的温度数据占用较多的冗余空间的问题,提高压缩效率。
- 还没有人留言评论。精彩留言会获得点赞!