一种基于超参数神经辐射场的人脸语音驱动方法及装置与流程
本发明涉及人脸图像处理,尤其是涉及一种基于超参数神经辐射场的人脸语音驱动方法及装置。
背景技术:
1、基于音频驱动的数字人像动画合成在多个领域都具有非常重要的应用场景,如虚拟助手、娱乐产业等。在现今信息技术高度发达的时代,通过音频输入实现与人工智能的自然交互是不可或缺的一环。为了实现这一目标,如何以高度逼真的方式还原说话者的面部表情成为了关键。
2、在基于音频驱动的数字人像动画建模方面,面临多方面挑战。首先,准确建模音频与面部动画的复杂关系至关重要,以确保最终动画能高度逼真地反映说话者的表情变化。同时,保持嘴部运动的自然流畅性需要精细处理细节。
3、传统基于缝合的技术通过规则定义音频-嘴型关系来修改嘴部形状,但其在处理不同发音和口型的说话者上存在局限性,导致合成动画显得生硬不自然,失去真实感。
4、另一方面,利用面部标志与3d变形模型等结构表示辅助说话者合成也存在误差引入问题,影响动画质量。
技术实现思路
1、为了克服背景技术中的不足,本发明公开了一种基于超参数神经辐射场的人脸语音驱动方法及装置。
2、为实现上述发明目的,本发明采用如下技术方案:
3、一种基于超参数神经辐射场的人脸语音驱动方法,包括以下步骤:
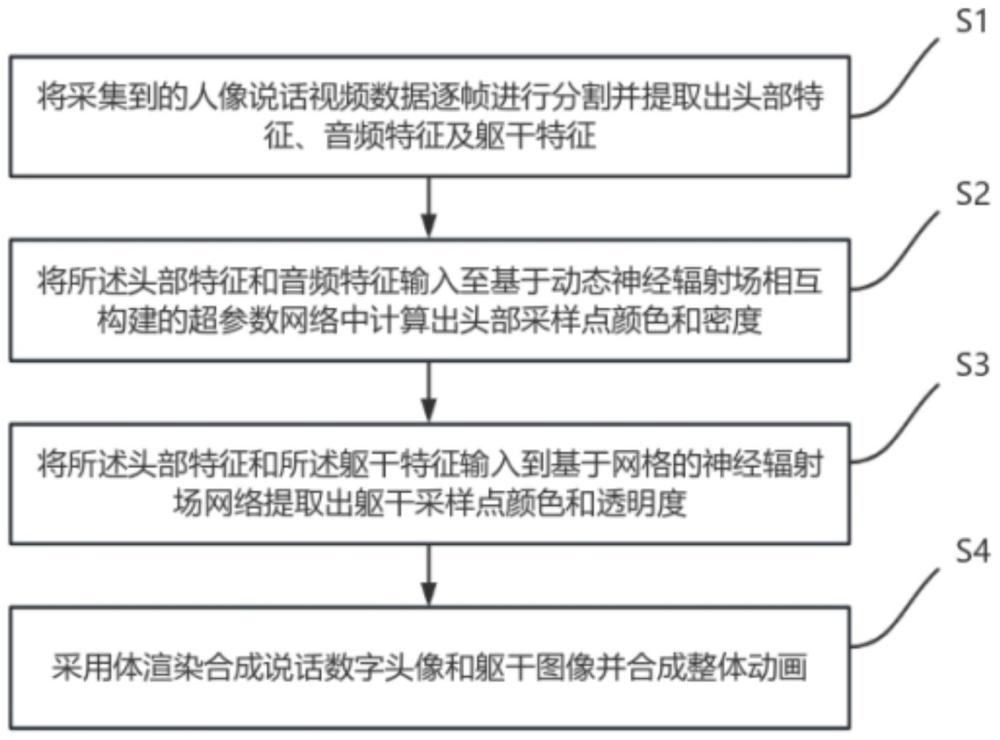
4、s1、将采集到的人像说话视频数据逐帧进行分割并提取出头部特征、音频特征及躯干特征;
5、s2、将所述头部特征和音频特征输入至基于动态神经辐射场相互构建的超参数网络中提取出头部高层语义特征和音频高层语义特征,并根据所述头部高层语义特征和音频高层语义特征计算出头部采样点颜色与头部采样点密度;
6、s3、将所述头部特征和所述躯干特征输入到基于网格的神经辐射场网络提取出躯干采样点颜色与躯干采样点透明度;
7、s4、采用体渲染合成说话数字头像和躯干图像并合成整体图像,具体为:根据所述头部采样点颜色与头部采样点密度进行体渲染获得头部图像,并根据所述躯干采样点颜色和躯干采样点透明度进行体渲染获得躯干图像,最后将所述头部图像和所述躯干图像合成整体图像。
8、具体的,步骤s2中将所述头部特征和音频特征输入至基于动态神经辐射场相互构建的超参数网络中提取出头部高层语义特征和音频高层语义特征具体包括以下步骤:
9、s21、通过所述音频特征为头部特征构建第一超参数网络获得超参数头部矩阵,如式(4)所示:
10、 (4)
11、其中,为超参数头部权重矩阵,为超参数头部偏差矩阵,mlp是多层感知机;
12、s22、通过所述头部特征为音频特征构建第二超参数网络获得超参数音频矩阵,如式(5)所示:
13、 (5)
14、其中,为超参数音频权重矩阵,为超参数音频偏差矩阵,mlp是多层感知机;
15、s23、通过所述头部特征与所述超参数头部矩阵输入到预设第一超参数网络的获得所述头部高层语义特征,如式(6)所示:
16、 (6)
17、其中,为一种s型激活函数;
18、s24、通过所述音频特征与所述超参数音频矩阵输入到预设第二超参数网络的获得所述音频高层语义特征,如式(7)所示:
19、 (7)
20、其中,为一种s型激活函数。
21、具体的,步骤s2根据所述头部高层语义特征和音频高层语义特征计算出头部采样点颜色与头部采样点密度具体包括以下步骤:
22、s25、在第i帧时,从原点o以角度发出一条射线,以式(8)在射线上进行采样,
23、 (8)
24、其中,代表在射线路径上采样的第y个点的三维坐标; 为在射线上的距离参数,即步长;
25、s26、通过多层感知机结合潜在外观嵌入计算所有采样点的颜色与密度,如式(9)所示:
26、 (9)
27、其中,为潜在外观嵌入;与为第i帧所有头部采样点的颜色与密度;头部采样点颜色表示为,头部采样点密度表示为。
28、具体的,所述步骤s1具体包括以下步骤:
29、s11、将视频数据分解成视频帧数组,并通过分割算法将每个视频帧分解成头部图像、音频信号和躯干图像,其中i表示当前视频帧的序号;
30、s12、从头部图像中提取出头部特征,如式(1)所示,
31、 (1)
32、其中,表示在第i帧处的头部输入信息;为头部的3d坐标;为观测方向,与分别为观测的方位角与俯仰角;为时间信息,是帧数i的线性变换;
33、s13、将音频信号转化为声谱图提取出音频特征,如式(2)所示,
34、 (2)
35、其中,表示在第i帧处的音频输入;是希尔伯特窗口函数;是复指数项,表示频率的相位,其中j是虚数单位的虚部;u是时间的自变量,du表示从负无穷到正无穷,表示对整个时间轴进行积分,以考虑整个信号的信息;
36、s14、从躯干的图像 中提取出躯干特征,如式(3)所示,
37、 (3)
38、其中,表示在第i帧处的躯干输入信息;代表躯干的2d坐标。
39、具体的,步骤s3具体包括以下步骤:
40、s31、将躯干图像分割为网格,并将其离散化为网格单元,所述网格单元包含局部躯干特征;
41、s32、对每个网格单元内部进行多点采样获得采样点;
42、s33、通过计算采样点与网格单元的边界的欧式距离得到i帧下躯干所有采样点的欧氏距离集合;
43、s34、结合所述头部特征的观测方向与多层感知与残差结构计算躯干所有采样点的透明度与颜色,如式(10)所示:
44、 (10)
45、其中,表示第i帧所有躯干采样点的颜色,表示第i帧所有躯干采样点的透明度。具体的,步骤s4具体包括以下步骤:
46、s41、根据每个像素颜色的均方差损失函数来训练网络生成头部模型,如式(11)所示:
47、 (11)
48、其中,n表示帧的总数,y表示在采样点的总数,表示在由模型计算出的第i帧下头部沿点采集的第y个采样点的预测颜色,而则表示第i帧下头部沿点采集的第y个采样点的真实颜色。
49、s42、根据头部采样点的预测颜色与密度的对头部模型进行体渲染获得头部渲染结果,如式(12)所示:
50、 (12)
51、其中,表示点处的渲染结果,表示沿点以方向和步长进行的采样的集合,是光线传播的衰减系数;
52、s43、根据每个像素颜色的均方差损失函数来训练网络生成躯干模型,如式(13)所示:
53、 (13)
54、其中,n表示帧的总数,y表示在采样点的总数,表示在由模型计算出的第i帧下躯干沿点采集的第y个采样点的预测颜色,而则表示第i帧下躯干沿点采集的第y个采样点的真实颜色;
55、s44、根据躯干采样点的预测颜色与透明度的对躯干模型进行体渲染获得躯干渲染结果,如式(14)所示:
56、 (14)
57、其中,表示点处的渲染结果,表示沿点以方向和步长进行的采样的集合,是光线传播的衰减系数;
58、s45、将头部渲染结果和躯干渲染结果进行合成得到整体图像。
59、具体的,步骤s12从头部图像中提取出头部特征采用的方法是短时傅里叶变换方法。
60、具体的,步骤s45中合成方法为阿尔法合成方法。
61、本发明还公开了一种基于超参数神经辐射场的人脸语音驱动装置,包含如下单元:
62、视频预处理单元,用于将采集到的人像说话视频数据逐帧进行分割并提取出头部特征、音频特征及躯干特征;
63、头部采样单元,用于将所述头部特征和音频特征输入至基于动态神经辐射场相互构建的超参数网络中提取出头部高层语义特征和音频高层语义特征,并根据所述头部高层语义特征和音频高层语义特征计算出头部采样点颜色与头部采样点密度;
64、躯干采样单元,用于将所述头部特征和所述躯干特征输入到基于网格的神经辐射场网络提取出躯干采样点颜色与躯干采样点透明度;
65、体渲染合成单元,采用体渲染合成说话数字头像和躯干图像并合成整体图像,具体为:根据所述头部采样点的颜色与密度进行体渲染获得头部图像,并根据所述躯干采样点的颜色和透明度进行体渲染获得躯干图像,最后将头部图像和躯干图像合成整体图像。
66、本发明公开的一种基于超参数神经辐射场的人脸语音驱动方法,包括以下步骤:s1、将采集到的人像说话视频数据逐帧进行分割并提取出头部特征、音频特征及躯干特征;s2、将所述头部特征和音频特征输入至基于动态神经辐射场相互构建的超参数网络中提取出头部高层语义特征和音频高层语义特征,并根据所述头部高层语义特征和音频高层语义特征计算出头部采样点颜色与头部采样点密度;s3、将所述头部特征和所述躯干特征输入到基于网格的神经辐射场网络提取出躯干采样点颜色与躯干采样点透明度;s4、采用体渲染合成说话数字头像和躯干图像并合成整体图像。本发明通过头部特征和音频特征之间的相互引导优化,头部特征在嘴部运动中起到引导作用,使得合成动画的口型更准确地反映了音频输入。同时,音频特征也能反过来对头部特征进行微调,使得面部表情更贴合说话者的实际情感变化,从而能够准确建模音频与面部动画的复杂关系,使得最终动画能高度逼真地反映说话者的表情变化;
67、进一步的,本发明通过构建两个超参数网络,分别以头部特征和音频特征作为输入,实现了对音频与头部的高层语义特征的提取,双重网络的相互优化也使得合成结果更具准确性和真实感,从而有效保持了精细处理的细节,使得嘴部运动更加自然流畅。
68、进一步的,本发明采用了细粒度合成,分别渲染头部和躯干,然后通过阿尔法合成整体图像,提高了渲染的灵活性,并且整体图像可以与任何提供的背景图像结合,产生更逼真的数字人物模型,使其在视觉上更具真实感和立体感。
- 还没有人留言评论。精彩留言会获得点赞!