基于医疗知识增强的组织病理切片自动识别方法与系统与流程
本发明涉及图像识别,尤其是涉及基于医疗知识增强的组织病理切片自动识别方法与系统。
背景技术:
1、近年来,伴随着语言模型在自然语言处理领域的突破和繁荣,从网络中爬取海量图文对数据以统一图像和文本表征空间的多模态基础模型在零样本自然图像分类任务上性能卓绝(clip基础模型在16/27个下游数据集中取得了比全监督残差网络模型更优的结果),为标注匮乏且下游任务多样的计算病理学提供了新的技术路线。然而,面向病理切片的多模态自动识别系统仍然稀少且性能有限,其原因在于:
2、第一、用于预训练的高质量病理图文数据短缺;
3、第二、缺乏针对病理学领域的专业知识建模;病理学诊断是知识密集型任务,需要广泛的病理学知识对病理切片图像中的细胞和形态学特征进行辨别;现有技术仅依赖于网络爬取的图文对进行表征空间对齐,无法抽象概括出专业病理知识用于疾病诊断;
4、第三、缺乏对同一疾病不同表述方式的鲁棒性;自然语言中对单一疾病的表述存在多种不同方式,因此对病理诊断系统在下游零样本诊断任务中提出了一致性要求;现有技术未能统一疾病的不同表述方式,导致在疾病诊断任务中针对病理图像的不同文本提示的诊断精度差异显著。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在缺乏针对病理学领域的专业知识建模,缺乏对同一疾病不同表述方式的鲁棒性的缺陷而提供一种基于医疗知识增强的组织病理切片自动识别方法与系统。
2、本发明的目的可以通过以下技术方案来实现:
3、一种基于医疗知识增强的组织病理切片自动识别方法,包括以下步骤:
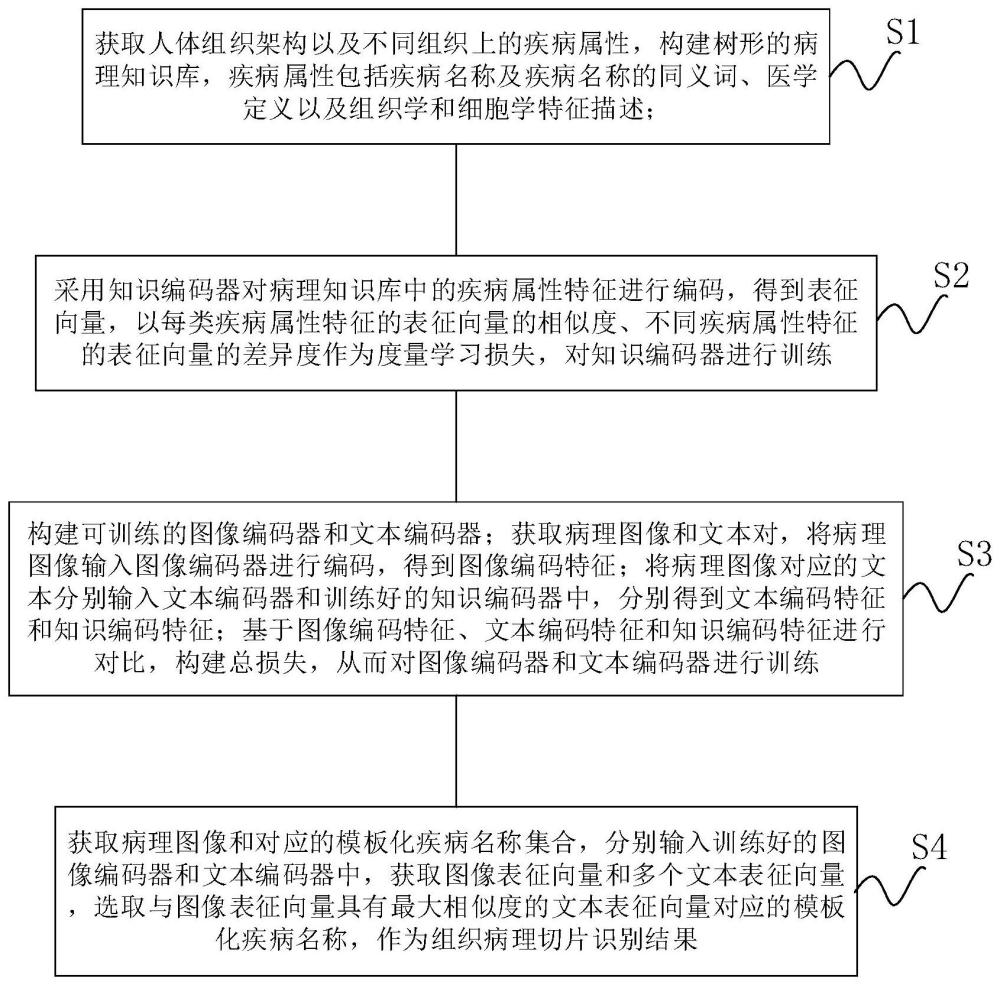
4、病理知识库构建步骤:获取人体组织架构以及不同组织上的疾病属性,构建树形的病理知识库,所述疾病属性包括疾病名称及疾病名称的同义词、医学定义以及组织学和细胞学特征描述;
5、知识编码器预训练步骤:采用知识编码器对病理知识库中的疾病属性特征进行编码,得到表征向量,以每类疾病属性特征的表征向量的相似度、不同疾病属性特征的表征向量的差异度作为度量学习损失,对知识编码器进行训练;
6、预训练模型训练步骤:构建可训练的图像编码器和文本编码器;获取病理图像和文本对,将病理图像输入图像编码器进行编码,得到图像编码特征;将病理图像对应的文本分别输入文本编码器和训练好的知识编码器中,分别得到文本编码特征和知识编码特征;基于图像编码特征、文本编码特征和知识编码特征进行对比,构建总损失,从而对图像编码器和文本编码器进行训练;
7、组织病理切片诊断步骤:获取病理图像和对应的模板化疾病名称集合,分别输入训练好的图像编码器和文本编码器中,获取图像表征向量和多个文本表征向量,选取与所述图像表征向量具有最大相似度的文本表征向量对应的模板化疾病名称,作为组织病理切片识别结果。
8、进一步地,所述知识编码器预训练步骤中,通过在病理知识库中,随机采样多种疾病,对每种疾病随机采样多种疾病属性特征,从而构建训练数据块;采用知识编码器对训练数据块中的疾病属性特征进行编码,获取多个表征向量。
9、进一步地,所述度量学习损失以每类疾病属性特征的表征向量的极大极小相似度衡量相似度,以同疾病属性特征的表征向量的极大相似度衡量差异度,所述每类疾病属性特征的表征向量的极大极小相似度的计算表达式为:
10、
11、式中,为第i类疾病属性特征的表征向量的极大极小相似度,和分别表示第i类疾病的第p个和第q个属性向量;
12、所述同疾病属性特征的表征向量的极大相似度的计算表达式为:
13、
14、式中,为同疾病属性特征的表征向量的极大相似度,和分别表示表示第i类疾病的第p个属性表征向量和第j类疾病的q个表征向量。
15、进一步地,所述总损失的构建过程包括:
16、基于图像编码特征和文本编码特征构造第一对比损失,基于文本编码特征和知识编码特征构造第二对比损失,从而基于第一对比损失和第二对比损失构建总损失。
17、进一步地,对第一对比损失和第二对比损失进行加权求和,得到所述总损失。
18、进一步地,所述组织病理切片诊断步骤中获取的病理图像为块级别病理图像,将该块级别病理图像输入训练好的图像编码器中,进行组织病理切片诊断。
19、进一步地,所述组织病理切片诊断步骤中获取的病理图像为病理全切片图像,将该病理全切片图像拆分为固定大小的多个图像块,将各个图像块分别输入训练好的图像编码器中,进行组织病理切片诊断,获取每个图像块与各个模板化疾病名称的相似度,选取相似度最大的前n个模板化疾病名称,进行相似度求平均,得到病理全切片图像与模板化疾病名称的表征相似度,选取表征相似度最大的模板化疾病名称作为该病理全切片图像的最终诊断结果。
20、进一步地,所述图像编码器为视觉transformer图像编码器或卷积神经网络结构。
21、进一步地,所述病理知识库的数据来源包括教科书和专业期刊。
22、本发明还提供一种基于医疗知识增强的组织病理切片自动识别系统,包括:
23、病理知识库构建模块,用于获取人体组织架构以及不同组织上的疾病属性,构建树形的病理知识库,所述疾病属性包括疾病名称及疾病名称的同义词、医学定义以及组织学和细胞学特征描述;
24、知识编码器预训练模块,用于采用知识编码器对病理知识库中的疾病属性特征进行编码,得到表征向量,以每类疾病属性特征的表征向量的相似度、不同疾病属性特征的表征向量的差异度作为度量学习损失,对知识编码器进行训练;
25、预训练模型训练模块,用于构建可训练的图像编码器和文本编码器;获取病理图像和文本对,将病理图像输入图像编码器进行编码,得到图像编码特征;将病理图像对应的文本分别输入文本编码器和训练好的知识编码器中,分别得到文本编码特征和知识编码特征;基于图像编码特征、文本编码特征和知识编码特征进行对比,构建总损失,从而对图像编码器和文本编码器进行训练;
26、组织病理切片诊断模块,用于获取病理图像和对应的模板化疾病名称集合,分别输入训练好的图像编码器和文本编码器中,获取图像表征向量和多个文本表征向量,选取与所述图像表征向量具有最大相似度的文本表征向量对应的模板化疾病名称,作为组织病理切片识别结果。
27、与现有技术相比,本发明具有以下优点:
28、(1)本发明通过构建病理知识库对知识编码器进行预先训练,并用于与图像编码器和文本编码器进行交叉对比,为预训练模型引入了病理知识增强图文表征能力,在应用过程中输入模板化疾病名称即可对测试病理图像进行有效诊断。
29、(2)与现有技术相比,本发明对病理图像块的诊断任务取得了更加优异的性能,而且由于病理知识库中以树形保存包括疾病名称及疾病名称的同义词、医学定义以及组织学和细胞学特征描述的疾病属性,使得预训练模型对于同一疾病不同名称的敏感度降低,诊断性能更加稳定。此外,由于对细粒度病理知识的建模,本发明对癌症患者的病理全切片图像的肿瘤亚型识别能力显著提高。
- 还没有人留言评论。精彩留言会获得点赞!