一种无人机辅助移动边缘计算系统
本发明涉及一种基于td3(twin delayed deep deterministic policygradient)的多无人机辅助移动边缘计算系统,属于移动边缘计算领域。
背景技术:
1、随着信息技术的发展,移动用户需要处理的任务逐渐转向计算密集型和延迟敏感型,移动边缘计算能够以较低的传输延迟为移动用户提供强大计算服务,如何有效保证用户的服务体验是十分关键的问题,用户体验包括延迟、能耗、鲁棒性、公平性等,如果用户数量激增,无人机由于其灵活可部署性为移动边缘计算发挥了重要的作用。
2、无人机辅助移动边缘计算因为无人机受到信道环境、计算资源等限制,使用传统方法不仅需要知道整个环境中的全局信息,而且还面临着复杂的连续离散混合优化问题,导致算法在延迟和公平性方面表现不好,并且在多变的环境中,每一步动作都需要重新求解,很难满足实时要求。
3、深度强化学习方法可以很好的解决上述问题,深度强化学习可以先通过试错的方式让智能体懂得什么行为是好的,什么行为是差的,从而部署在环境中可以保证无人机对于环境的实时性决策。
4、目前的深度强化算法通常考虑的是单无人机辅助移动边缘计算即单智能体深度强化学习算法,并且通信模型使用的是自由空间传播模型,但是在现实生活中,大部分情况都是多无人机辅助移动边缘计算,信道传播模型也很难是自由空间传播模型,在这种情况下,如果都按照自由传播模型进行计算会导致鲁棒性差,实际应用效果不好。
技术实现思路
1、本发明提供了一种基于td3的多无人机辅助移动边缘计算系统延迟和公平性优化方法,旨在优化无人机飞行轨迹,无人机用户选择、地面基站与无人机之间的任务分配比以降低用户延迟以及提高用户被服务次数的公平性,能够保证用户体验。
2、为解决上述优化问题,本发明采取了下述技术方案实现:
3、一,对提出的无人机辅助移动边缘计算系统进行建模。
4、二,获取用户和无人机的基本状态信息,以无人机路径规划、无人机用户选择为动作,以及给出一个公式决定任务分配比,基于我们设计的奖励函数和折扣因子,将模型转化为马尔可夫决策过程。
5、三,各无人机通过其配备的神经网络进行马尔可夫决策过程求解,从而得到优化后的飞行轨迹和用户选择,最终达到降低延迟和提升用户被服务次数公平性的目的。
6、我们考虑的是当基站负载很大时,无人机辅助基站进行移动用户任务处理,用户在每个时刻都会产生一个延迟敏感型任务,无人机根据深度强化学习算法同时在这个时刻决定自己的飞行方向以及选择服务的用户,无人机在同一时间内只能服务一个用户,然后无人机飞行完成后给出一个任务分配比用于决定基站与无人机之间的任务分配,通过优化这三个行为,最终实现了用户延迟的降低和用户被服务次数公平性的提高。
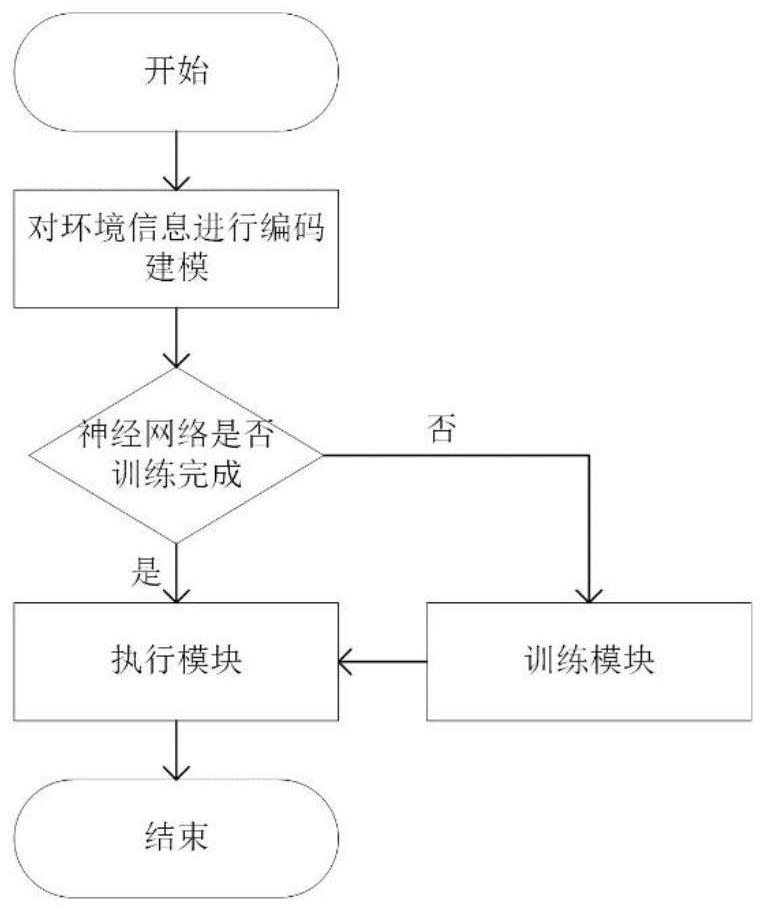
7、根据本发明的第一方面,提供一种无人机辅助移动边缘计算系统,包括:
8、编码模块,用于对环境进行编码建模操作。
9、训练模块,用于对无人机上搭载的神经网络进行训练。
10、执行模块,用于使用训练好的神经网络根据无人机观察信息得到无人机动作以及使用提出的任务分配比公式得到无人机与基站之间的任务分配比,并在环境中执行无人机动作和任务分配比。
11、其中,每个无人机上搭载了六个神经网络,分别为:actor网络,参数为α的,第一critic网络,参数为β1,第二critic网络,参数为β2,actor网络对应的第一target网络,第一critic网络对应的第二target网络,第二critic网络对应的第三target网络。
12、进一步地,本发明所提供的无人机辅助移动边缘计算系统延迟和公平性优化方法,训练模块包括用于进行以下训练过程:
13、步骤a1:对环境参数进行初始化。
14、步骤a2:获取无人机观察信息并进行正则化处理。
15、步骤a4:critic网络训练。
16、步骤a5:actor网络训练。
17、步骤a6:target网络更新。
18、步骤a7:判断无人机运行时刻是否到达最大限制时刻,如果未达最大限制时刻则返回步骤a2;如果达到最大限制时刻,则判断是否到达设定的最大训练轮数,如果否,则返回步骤a1,如果是则结束训练。
19、进一步地,本发明所提供的无人机辅助移动的边缘计算系统,步骤a1包括:初始化无人机位置cm(t)、所有用户被服务次数an(t)、基站位置ck、用户位置cn、时间t、神经网络训练优化器adam。
20、步骤a2包括:观察信息om(t)计算方式为:
21、
22、其中an(t)代表用户n在t时刻是否被服务,表示为:
23、
24、将om(t)正则化从而将数据压缩在0-1范围内,计算方式为:
25、
26、其中,om(t)max为om(t)可能达到最大的值。
27、进一步地,本发明所提供的无人机辅助移动边缘计算系统,步骤a3包括:
28、将正则化处理后的观察信息om(t)输入actor神经网络得到动作am(t)并将动作和任务分配比um(t)作用于环境可以得到四元组(s(t),am(t),rm(t),s(t+1))以完成经验存储;其中s(t)代表所有无人机的观察,可以表示为s(t)={o1(t),o2(t),…,om(t)}。无人机的动作其中zm(t)代表t时刻无人机m的用户选择,代表t时刻无人机的飞行方向,任务分配比um(t)由任务分配比公式给出,如下:
29、
30、其中,s为cpu周期数,fk为地面基站的cpu频率,fm为无人机的cpu频率,rm,k(t)为tst时无人机m与地面基站k之间的传输速度。
31、为了优化离散和连续混合动作的探索,以探索更多的路径,避免陷入局部最优,将离散变量的用户选择zm(t)设置为:
32、
33、其中ε表示给定探索参数,exp表示均值为0,方差为1的正态函数,是无人机上搭载的actor网络。
34、将连续变量的飞行方向φm(t)设置为:
35、
36、其中∈表示噪音探索参数。
37、四元组中rm(t)表示无人机根据输出动作am(t)和任务分配比um(t)从环境中获取到的奖励,奖励是用来评价无人机输出动作am(t)的好坏,奖励函数表示为:
38、
39、其中,tm代表无人机m处理的任务总延迟,pcol,pue,prange分别代表无人机之间的碰撞惩罚,无人机选择相同用户惩罚,无人机超出边界惩罚。
40、进一步地,本发明所提供的无人机辅助移动边缘计算系统延迟和公平性优化方法,步骤a4包括:
41、在经验回放缓冲器中随机抽样得到k条经验,利用抽样得到的四元组(s(t),am(t),rm(t),s(t+1))更新智能体的两个critic网络,使用梯度下降法,基于critic网络的损失函数,更新所述两个critic网络;其中critic网络的损失函数为:
42、
43、其中,s(t)表示所有无人机观察0m(t)的合集,ym(t)表示td-target,表示为:
44、
45、其中,表示第二或第三target网络输出,是指在无人机m中,将om(t+1)输入无人机m的第一target网络得到的动作,γ表示马尔可夫折扣因子。
46、critic神经网络用于根据所有无人机观察信息s(t)对当前无人机动作am(t)进行打分。进一步地,本发明所提供的无人机辅助移动边缘计算系统延迟和公平性优化方法,步骤a5包括:actor网络训练采用策略梯度上升算法,表示为:
47、
48、其中,m={1,2,…,m}为无人机的集合,为无人机的actor网络梯度。
49、进一步地,本发明所提供的无人机辅助移动的边缘计算系统,步骤a6包括:target网络更新表示为:
50、α′=τα+(1-τ)α′
51、β′i=τβi+(1-τ)β′i,i=1,2
52、其中,α′表示第一target网络的参数,β′i表示第二或第三target网络的参数,τ是更新速率。
53、进一步地,本发明所提供的无人机辅助移动边缘计算系统,用以进行延迟和公平性优化,执行模块包括用于进行以下执行过程:
54、初始化环境参数,再获取无人机的观察信息om(t)并对其进行正则化处理,将正则化处理后的的观察信息om(t)输入actor网络得到动作am(t),此时的动作am(t)不进行探索,包含的用户选择飞行方向根据无人机与基站之间的任务分配比um(t),执行am(t)和um(t)。
55、根据本发明的第二方面,提供一种计算机设备,其特征在于,包括:
56、存储器,用于存储指令;以及处理器,用于调用存储器存储的指令实现第一方面的系统。
57、根据本发明的第三方面,提供一种计算机可读存储介质,其特征在于,存储有指令,指令被处理器执行时,实现第一方面的系统。
58、与现有技术相比,本发明所构思的上述技术方案至少具有以下有益效果:
59、(1)考虑了概率信道模型,能够更加适应现实环境。
60、(2)考虑的多智能体深度强化学习算法,相对于单智能体算法来说鲁棒性更好,而且能够达到实时部署的能力,并给出了一种全新的关于深度强化学习的探索方法。
61、(3)创新性的给出了一个任务分配比公式,并且给出了一种连续和离散混合型动作的探索处理方法。
62、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本发明。
- 还没有人留言评论。精彩留言会获得点赞!