一种轻量化手部重建与驱动的方法
本发明涉及计算机视觉和三维重建,特别是涉及一种轻量化手部重建与驱动的方法。
背景技术:
1、手部重建与驱动是人类与新媒体交互的重要形式之一,也是沉浸式虚拟世界中提升用户沉浸感不可或缺的一部分。在轻量化采集设备采集数据的场景下,高精度的手部重建与任意姿态的手部驱动能使用户方便、快捷地沉浸体验虚拟世界交互行为。因此,仅在轻量化采集设备获取的稀疏视角图像输入下,手部重建与驱动不仅为人机交互提供基础,还能丰富沉浸式虚拟世界中照片级三维内容的生态。所以,手部重建与驱动在轻量化采集设备场景下具有广泛应用,是构建沉浸式虚拟世界、创建超真实感数字人的基础算法。
2、近些年来,手部重建和驱动领域取得了重要进展。随着神经辐射场的提出与发展,手部重建从依赖三维真值网格,到密集多视角图像重建,再到稀疏视角重建;手部驱动也从依赖海量高质量真值网格做训练集,到依靠多层感知机隐式驱动,再扩展到基于参数化模型的高效驱动,实现了快速的发展。轻量化采集设备采集稀疏视角图像场景下,优化手部网格作为神经辐射场初始化可以弥补其固有的难以拟合高精度几何的缺点,索引模板获取变形权重则节约了学习隐式变形场所需的大量计算资源,实现高效快捷轻量化的手部重建与驱动。
3、尽管现有手部重建与驱动工作已有大量的研究基础,目前的方法仍存在三个问题。首先,手部重建方法需要同时建模手部的高精度几何和较不明显的弱纹理特征,在稀疏视角输入下,大部分方法难以对自遮挡区域与未见区域进行良好建模;其次,现有手部重建方法在输入视图的数量与重建质量之间很难平衡,即,获取高质量重建结果的前提是大量密集视图输入与投入长时间大量计算资源的训练,这还会导致收敛过慢、训练时间和渲染时间过长的问题;最后,手部姿态估计与网格优化往往与真值有偏差,这首先使得现有方法在稀疏视角下难以学习隐式运动场,同时在处理驱动时如果直接采用隐式场或直接代入混合蒙皮模型,会导致“橡皮糖”效应,使得手部的弯折存在过平滑或皮肤破损的情况,还会出现大量伪影,造成手指残缺的渲染效果。
4、综上所述,现有技术存在在稀疏视角输入下无法进行良好建模,获取高质量重建结果存在收敛过慢、训练时间和渲染时间过长,处理驱动时存在手部的弯折存在过平滑或皮肤破损的情况和渲染效果差的问题。
5、需要说明的是,在上述背景技术部分公开的信息仅用于对本技术的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现思路
1、为了解决现有技术在稀疏视角输入下无法进行良好建模,获取高质量重建结果存在收敛过慢、训练时间和渲染时间过长,处理驱动时存在手部的弯折存在过平滑或皮肤破损的情况和渲染效果差的问题,本发明提出一种轻量化手部重建与驱动的方法。
2、本发明的技术问题通过以下的技术方案予以解决:
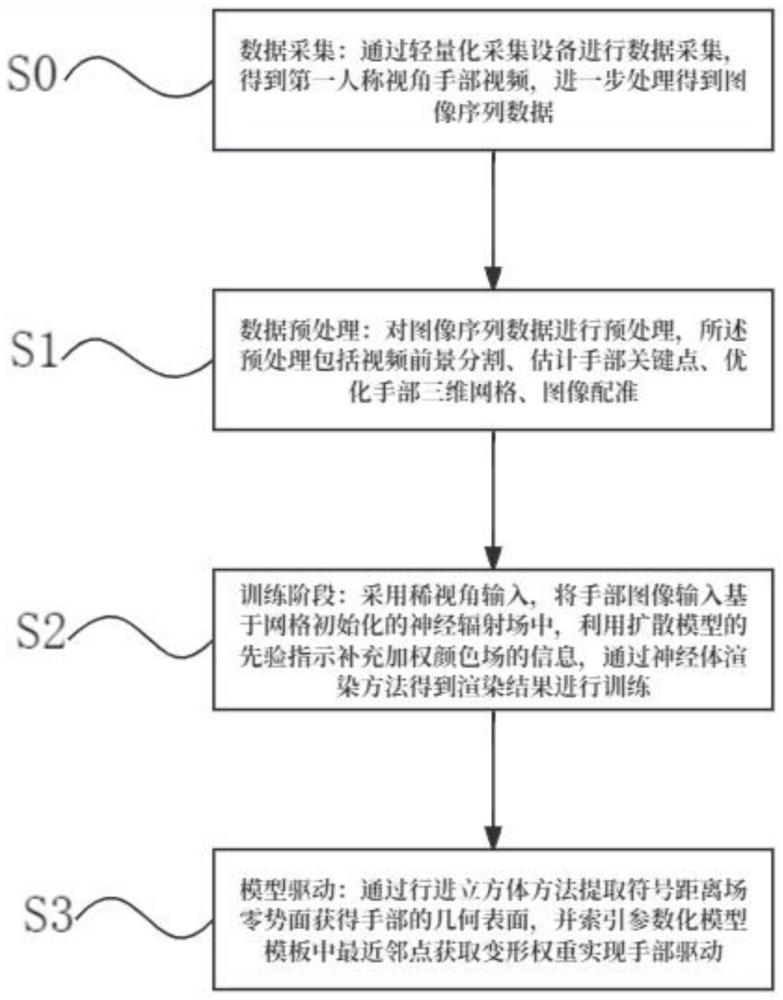
3、一种轻量化手部重建与驱动的方法,包括如下步骤:
4、s1:数据预处理:对图像序列数据进行预处理,所述预处理包括视频前景分割、估计手部关键点、优化手部三维网格、图像配准;
5、s2:训练阶段:采用稀视角输入,将手部图像输入基于网格初始化的神经辐射场中,利用扩散模型的先验指示补充加权颜色场的信息,通过神经体渲染方法得到渲染结果进行训练;
6、s3:模型驱动:通过行进立方体方法提取符号距离场零势面获得手部的几何表面,并索引参数化模型模板中最近邻点获取变形权重实现手部驱动。
7、在一些实施例中,步骤s1中,所述图像序列数据由如下步骤获得:
8、s0:数据采集:通过轻量化采集设备进行数据采集,得到第一人称视角手部视频,进一步处理得到图像序列数据。
9、在一些实施例中,步骤s0中,解帧处理所述得到第一人称视角手部视频得到所述图像序列数据,所述图像序列数据为单目图像序列或时序对齐的多目图像序列。
10、在一些实施例中,步骤s0中,所述第一人称视角手部视频为待重建手部的视频序列,包括手心朝向采集设备姿态、手背朝向采集设备姿态及在以上两种姿态基础上轻程度动作变形的视频序列。
11、在一些实施例中,步骤s1中,所述视频前景分割具体为:利用前景分割算法对所述图像序列数据进行前景分割,得到手部掩码图;
12、所述估计手部关键点具体为:利用手部检测算法检测手部检测框,根据所述手部检测框和利用基于手部关键点检测算法的关键点检测器检测手部关键点,所述手部关键点包括的2d手部关键点;
13、所述优化手部三维网格具体为:根据所述2d手部关键点和利用手部姿态估计算法以及mano参数化模型进行手部姿态估计与网格优化,得到手部姿态并获得手部在相机坐标系下的网格表示,所述手部姿态包括姿态参数和形状参数;
14、所述图像配准包括以下步骤:首先利用掩码截取手腕,然后计算手部在相机坐标系下的网格表示与参数化模板网格的缩放比例,获取缩放后真实三维关键点坐标与网格信息,由经焦距校正过后的相机参数投影得到的二维点与所述2d手部关键点计算仿射变换矩阵实现图像配准。
15、在一些实施例中,步骤s2中,所述训练阶段包括以下步骤:
16、s2-1:在一个训练周期内取稀疏视角关键帧图像数据进行训练,所述疏视角关键帧图像数据进行训练包括单帧的训练;
17、所述单帧的训练以该帧的手部姿态、相机姿态作为输入,输出渲染图像;所述稀疏视角关键帧图像数据为所述图像序列数据中关键的几帧,所述稀疏视角关键帧图像数据包含手心和手背的帧图像。
18、在一些实施例中,所述检测手部关键点的点数为21个,所述手部姿态包括48个姿态参数和10个形状参数,所述稀疏视角关键帧图像数据小于8张帧图像。
19、在一些实施例中,所述步骤s2-1的具体流程为:
20、s2-1-1:在像素坐标系中采样一定数量的坐标,按照相机内参进行逆投影获取单位三维齐次坐标,按照相机外参坐标变换至世界坐标系,得到以相机光心为原点的射线,再在射线上进行以体密度为先验的间隔采样,得到世界坐标系下的采样点;经过以网格作为初始化的神经辐射场学习得到体密度场和加权颜色场,通过插值获得空间中任一点的颜色与体密度;
21、s2-1-2:对于几何分支,通过行进立方体方法获取手部几何网格,依照参数化模型标准模板以投影方法逐点索引真实几何在标准模板上的最近点,通过加权插值获取真实网格上每一点的变形权重;
22、s2-1-3:对于颜色表达分支,利用缺失真实数据的待合成新视角,利用具有强先验信息的可泛化扩散模型提供特定方向梯度,用于优化未见视角的颜色表达;
23、s2-1-4:最后,真实网格按照索引所得变形权重经过线性混合蒙皮模型,依照预处理所得手部姿态参数对采样点进行坐标映射,并将映射后的坐标点代入经过增强的颜色场获取逐点颜色,进行体渲染获取高质量渲染图像。
24、在一些实施例中,步骤s2-1-1中,所述以网格作为初始化的神经辐射场由多分辨率哈希编码表达和一个多层感知机构成,用于预测正则空间中的颜色、带符号距离场、体密度值。
25、在一些实施例中,步骤s2-1-2和s2-1-4中,所述索引参数化模型模板中最近邻点获取变形权重,计算真实网格与标准模板之间逐点欧氏距离获取索引序列,并同时计算相邻点的距离作为插值权重,按照重心插值公式对变形权重实现加权求和。
26、本发明与现有技术对比的有益效果包括:
27、本发明提出的一种轻量化手部重建与驱动的方法采用稀疏视角输入,远优于现有技术普遍采用的密集视角输入,可有效减少时间与计算资源成本;
28、本发明利用网格初始化的神经辐射场结合扩散模型先验知识,其网格初始化神经辐射场使得轻量化手部重建与驱动的方法的训练速度优于其他算法的初始化方法,此种初始化本身提供了粗糙的几何结构,减少了时间与计算资源消耗,结合扩散模型可以提高渲染结果质量,使算法更快收敛,使算法中的参数概率分布符合梯度下降的方向,进一步加速收敛;并由于质量提高可获得超高精度三维手部网格,大量缩短训练时间、渲染时间与计算资源消耗,还可解决稀疏视角下未见区域的纹理问题,实现了稀疏视角下手部高质量几何与纹理重建,并以参数化模型模板为基准插值获取逐点变形权重,实现了任意姿态驱动;
29、同时本发明引入索引模板蒙皮权重的方法,依据参数化模型模板索引逐点变形权重并插值计算,解决变形问题中的皮肤破损、过平滑、关节弯曲程度受限、渲染图像几何残缺的问题,保证算法具有较高鲁棒性。
30、本发明实施例中的其他有益效果将在下文中进一步述及。
- 还没有人留言评论。精彩留言会获得点赞!